
Abstract
Low-bit deep neural networks (DNNs) become critical for embedded applications due to their low storage requirement yet high computing efficiency. However, they suffer much from the non-negligible accuracy drop. This paper proposes the stochastic quantization (SQ) algorithm for learning accurate low-bit DNNs. The motivation is due to the following observation. Existing training algorithms approximate the real-valued weights with low-bit representation all together in each iteration. The quantization error may be small for some elements/filters, while is remarkable for others, which leads to inappropriate gradient directions during training, and thus brings notable accuracy drop. Instead, SQ quantizes a portion of elements/filters to low-bit values with a stochastic probability inversely proportional to the quantization error, while keeping the other portion unchanged with full precision. The quantized and full precision portions are updated with their corresponding gradients separately in each iteration. The SQ ratio, which measures the ratio of the quantized weights to all weights, is gradually increased until the whole network is quantized. This procedure can greatly compensate for the quantization error and thus yield better accuracy for low-bit DNNs. Experiments show that SQ can consistently and significantly improve the accuracy for different low-bit DNNs on various datasets and various network structures, no matter whether activation values are quantized or not.






Similar content being viewed by others


Notes
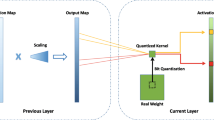
We can also define the non-quantization probability indicating the probability each row should not be quantized.
References
Bengio, Y. (2013). Estimating or propagating gradients through stochastic neurons. arXiv preprint arXiv:1305.2982.
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2015). Semantic image segmentation with deep convolutional nets and fully connected crfs. In International conference on learning representations (ICLR).
Courbariaux, M., & Bengio, Y. (2016). Binarynet: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv preprint arXiv:1602.02830.
Courbariaux, M., Bengio, Y., & David, J. P. (2015). Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in neural information processing systems (NIPS) (pp. 3123–3131).
Denil, M., Shakibi, B., Dinh, L., Ranzato, M., & de Freitas, Nando. (2013). Predicting parameters in deep learning. In Advances in neural information processing systems (NIPS) (pp. 2148–2156).
Dong, Y., Ni, R., Li, J., Chen, Y., Zhu, J., & Su, H. (2017). Learning accurate low-bit deep neural networks with stochastic quantization. In Proceedings of the British machine vision conference (BMVC).
Girshick, R., Donahue, J., Darrell T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) (pp. 580–587).
Han, S., Pool, J., Tran, J., & Dally, W. (2015). Learning both weights and connections for efficient neural network. In Advances in neural information processing systems (NIPS) (pp. 1135–1143).
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) (pp. 770–778).
Hinton, G., Srivastava, N., & Swersky, K. (2012). Neural networks for machine learning. Coursera Video Lectures. https://www.youtube.com/playlist?list=PLoRl3Ht4JOcdU872GhiYWf6jwrk_SNhz9.
Hong, S., Roh, B., Kim, K. H., Cheon, Y., & Park, M. (2016). Pvanet: Lightweight deep neural networks for real-time object detection. arXiv preprint arXiv:1611.08588.
Hou, L., Yao, Q., & Kwok, J. T. (2017). Loss-aware binarization of deep networks. In International conference on learning representations (ICLR).
Huang, G., Sun, Y., Liu, Z., Sedra, D., Weinberger, K. Q. (2016). Deep networks with stochastic depth. In European conference on computer vision (ECCV) (pp. 646–661).
Hubara, I., Courbariaux, M., Soudry, D., El-Yaniv, R., & Bengio, Y. (2016). Quantized neural networks: Training neural networks with low precision weights and activations. arXiv preprint arXiv:1609.07061.
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., & Darrell, T. (2014). Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on multimedia (MM) (pp. 675–678).
Krizhevsky, A., & Hinton, G. (2009). Learning multiple layers of features from tiny images. University of Toronto.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (NIPS) (pp. 1097–1105).
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
Li, F., Zhang, B., & Liu, B. (2016). Ternary weight networks. In NIPS workshop on EMDNN.
Lin, D., Talathi, S., & Annapureddy, V. S. (2016). Fixed point quantization of deep convolutional networks. In International conference on machine learning (ICML) (pp. 2849–2858).
Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) (pp. 3431–3440).
Miyashita, D., Lee, E. H., & Murmann, B. (2016). Convolutional neural networks using logarithmic data representation. arXiv preprint arXiv:1603.01025.
Rastegari, M., Ordonez, V., Redmon, J., & Farhadi, A. (2016). Xnor-net: Imagenet classification using binary convolutional neural networks. In European conference on computer vision (ECCV) (pp. 525–542).
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (NIPS) (pp. 91–99).
Russakovsky, O., Deng, J., Hao, S., Krause, J., Satheesh, S., Ma, S., et al. (2015). Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3), 211–252.
Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. In International conference on learning representations (ICLR).
Srivastava, N., Hinton, G. E., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1), 1929–1958.
Tang, W., Hua, G., & Wang, L. (2017). How to train a compact binary neural network with high accuracy? In AAAI conference on artificial intelligence (AAAI) (pp. 2625–2631).
Venkatesh, G., Nurvitadhi, E., & Marr, D. (2016). Accelerating deep convolutional networks using low-precision and sparsity. arXiv preprint arXiv:1610.00324.
Zhou, S., Wu, Y., Ni, Z., Zhou, X., Wen, H., & Zou, Y. (2016). Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv preprint arXiv:1606.06160.
Zhou, A., Yao, A., Guo, Y., Lin, X., & Chen, Y. (2017). Incremental network quantization: Towards lossless cnns with low-precision weights. In International conference on learning representations (ICLR).
Zhu, C., Han, S., Mao, H., & Dally, W. J. (2017). Trained ternary quantization. In International conference on learning representations (ICLR).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Dr. Tae-Kyun Kim, Dr. Stefanos Zafeiriou, Dr. Ben Glocker and Dr. Stefan Leutenegger.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was done when Yinpeng Dong and Renkun Ni were interns at Intel Labs supervised by Jianguo Li. Yinpeng Dong, Hang Su and Jun Zhu are also supported by the National Basic Research Program of China (2013CB329403), the National Natural Science Foundation of China (61620106010, 61621136008)
Rights and permissions
About this article

Cite this article
Dong, Y., Ni, R., Li, J. et al. Stochastic Quantization for Learning Accurate Low-Bit Deep Neural Networks. Int J Comput Vis 127, 1629–1642 (2019). https://doi.org/10.1007/s11263-019-01168-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01168-2