
Abstract
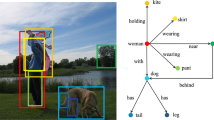
Previous methods treat visual relationship detection as a combination of object detection and predicate detection. However, natural images likely contain hundreds of objects and thousands of object pairs. Relying only on object detection and predicate detection is insufficient for effective visual relationship detection because the significant relationships are easily overwhelmed by the dominant less-significant relationships. In this paper, we propose a novel subtask for visual relationship detection, the significance detection, as the complement of object detection and predicate detection. Significance detection refers to the task of identifying object pairs with significant relationships. Meanwhile, we propose a novel multi-task compositional network (MCN) that simultaneously performs object detection, predicate detection, and significance detection. MCN consists of three modules, an object detector, a relationship generator, and a relationship predictor. The object detector detects objects. The relationship generator provides useful relationships, and the relationship predictor produces significance scores and predicts predicates. Furthermore, MCN proposes a multimodal feature fusion strategy based on visual, spatial, and label features and a novel correlated loss function to deeply combine object detection, predicate detection, and significance detection. MCN is validated on two datasets: visual relationship detection dataset and visual genome dataset. The experimental results compared with state-of-the-art methods verify the competitiveness of MCN and the usefulness of significance detection in visual relationship detection.









Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Notes
The source code is provided at https://github.com/Atmegal/MCN.
References
Chen, T., Yu, W., Chen, R., & Lin, L. (2019). Knowledge-embedded routing network for scene graph generation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6163–6171).
Chen, X., & Gupta, A. (2017). An implementation of faster rcnn with study for region sampling. arXiv preprint arXiv:1702.02138
Desai, C., & Ramanan, D. (2012). Detecting actions, poses, and objects with relational phraselets. In European conference on computer vision (pp 158–172). Springer.
Du Plessis, M., Niu, G., & Sugiyama, M. (2015). Convex formulation for learning from positive and unlabeled data. In International conference on machine learning (pp. 1386–1394).
Fang, H., Gupta, S., Iandola, F., Srivastava, R.K., Deng, L., Dollar, P., Gao, J., He, X., Mitchell, M., Platt, J.C., Zitnick, C.L., & Zweig, G. (2015). From captions to visual concepts and back. In 2015 IEEE conference on computer vision and pattern recognition (CVPR) (vol 00, pp. 1473–1482). https://doi.org/10.1109/CVPR.2015.7298754.
Farhadi, A., & Sadeghi, M. A. (2011). Recognition using visual phrases. In CVPR 2011(CVPR) (vol 00, pp. 1745–1752). https://doi.org/10.1109/CVPR.2011.5995711.
Galleguillos, C., Rabinovich, A., & Belongie, S. (2008). Object categorization using co-occurrence, location and appearance. In IEEE conference on computer vision and pattern recognition, 2008 (pp. 1–8). CVPR 2008, IEEE.
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580–587).
Gould, S., Rodgers, J., Cohen, D., Elidan, G., & Koller, D. (2008). Multi-class segmentation with relative location prior. International Journal of Computer Vision, 80(3), 300–316.
Gu, J., Zhao, H., Lin, Z., Li, S., Cai, J., & Ling, M. (2019). Scene graph generation with external knowledge and image reconstruction. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1969–1978).
Han, C., Shen, F., Liu, L., & Yang, Y. (2018). Shen HT (2018) Visual spatial attention network for relationship detection. In ACM multimedia conference on multimedia conference, ACM (pp. 510–518).
Hsieh, C.J., Natarajan, N., & Dhillon, I.S. (2015). Pu learning for matrix completion. In ICML (pp. 2445–2453).
Hu, H., Gu, J., Zhang, Z., Dai, J., & Wei, Y. (2018). Relation networks for object detection. In The IEEE conference on computer vision and pattern recognition (CVPR).
Jae Hwang, S., Ravi, SN., Tao, Z., Kim, H.J., Collins, M.D., & Singh, V. (2018). Tensorize, factorize and regularize: Robust visual relationship learning. In The IEEE conference on computer vision and pattern recognition (CVPR).
Kaji, H., Yamaguchi, H., & Sugiyama, M. (2018). Multi task learning with positive and unlabeled data and its application to mental state prediction. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), IEEE (pp. 2301–2305).
Kanehira, A., & Harada, T. (2016). Multi-label ranking from positive and unlabeled data. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5138–5146).
Kong, Y., & Fu, Y. (2017). Max-margin heterogeneous information machine for rgb-d action recognition. International Journal of Computer Vision, 123(3), 350–371.
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., et al. (2017). Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123(1), 32–73.
Li, X. L., Yu, P. S., Liu, B., & Ng, S. K. (2009). Positive unlabeled learning for data stream classification. In Proceedings of the 2009 SIAM international conference on data mining, SIAM (pp. 259–270).
Li, Y., Ouyang, W., Wang, X., & Tang, X. (2017a). Vip-cnn: Visual phrase guided convolutional neural network. In Computer vision and pattern recognition (pp. 7244–7253).
Li, Y., Ouyang, W., Zhou, B., Wang, K., & Wang, X. (2017b). Scene graph generation from objects, phrases and region captions. In Proceedings of the IEEE international conference on computer vision (pp. 1261–1270).
Liang, K., Guo, Y., Chang, H., & Chen, X. (2018). Visual relationship detection with deep structural ranking. In AAAI Conference on artificial intelligence.
Liang, X., Lee, L., & Xing, E. P. (2017). Deep variation-structured reinforcement learning for visual relationship and attribute detection. In Computer vision and pattern recognition (pp. 4408–4417).
Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980–2988).
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., et al. (2016). Ssd: Single shot multibox detector. In European conference on computer vision (pp. 21–37). Springer.
Lu, C., Krishna, R., Bernstein, M. S., & Feifei, L. (2016). Visual relationship detection with language priors. In European conference on computer vision (pp. 852–869).
Misra, I., Shrivastava, A., Gupta, A., & Hebert, M. (2016). Cross-stitch networks for multi-task learning. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3994–4003).
Ouyang, W., Zeng, X., & Wang, X. (2016). Learning mutual visibility relationship for pedestrian detection with a deep model. International Journal of Computer Vision, 120(1), 14–27.
Palmero, C., Clapés, A., Bahnsen, C., Møgelmose, A., Moeslund, T. B., & Escalera, S. (2016). Multi-modal rgb-depth-thermal human body segmentation. International Journal of Computer Vision, 118(2), 217–239.
Pennington, J., Socher, R., & Manning, C. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532–1543).
Peyre, J., Laptev, I., Schmid, C., & Sivic, J. (2017). Weakly-supervised learning of visual relations. In international conference on computer vision (pp. 5189–5198).
Platanios, E., Poon, H., Mitchell, T. M., & Horvitz, E. J. (2017). Estimating accuracy from unlabeled data: A probabilistic logic approach. In Advances in neural information processing systems (pp. 4361–4370).
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779–788).
Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis & Machine Intelligence, 6, 1137–1149.
Ruder, S. (2017). An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098
Sansone, E., De Natale, F. G., & Zhou, Z. H. (2018). Efficient training for positive unlabeled learning. In IEEE Transactions on pattern analysis and machine intelligence.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Xu, D., Zhu, Y., Choy, C.B., & Fei-Fei, L. (2017). Scene graph generation by iterative message passing. In Proceedings of the IEEE conference on computer vision and pattern recognition (vol. 2).
Yang, X., Zhang, H., & Cai, J. (2018). Shuffle-then-assemble: learning object-agnostic visual relationship features. arXiv preprint arXiv:1808.00171
Yao, T., Pan, Y., Li, Y., & Mei, T. (2018). Exploring visual relationship for image captioning. In Proceedings of the European conference on computer vision (ECCV) (pp. 684–699).
Yin, G., Sheng, L., Liu, B., Yu, N., Wang, X., Shao, J., & Loy, C.C. (2018). Zoom-net: Mining deep feature interactions for visual relationship recognition. arXiv preprint arXiv:1807.04979
Yu, R., Li, A., Morariu, V. I., & Davis, L. S. (2017). Visual relationship detection with internal and external linguistic knowledge distillation. In International conference on computer vision (pp. 1068–1076).
Yu, Z., Yu, J., Fan, J., & Tao, D. (2017). Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In Proceedings of the IEEE international conference on computer vision (pp. 1821–1830).
Yu, Z., Yu, J., Xiang, C., Fan, J., & Tao, D. (2018). Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering. IEEE Transactions on Neural Networks and Learning Systems, 99, 1–13.
Zhan, Y., Yu, J., Yu, T., & Tao, D. (2019). On exploring undetermined relationships for visual relationship detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5128–5137).
Zhang, H., Kyaw, Z., Chang, S., & Chua, T. (2017a). Visual translation embedding network for visual relation detection. In Computer vision and pattern recognition (pp. 3107–3115).
Zhang, H., Kyaw, Z., Yu, J., & Chang, S. (2017b). Ppr-fcn: Weakly supervised visual relation detection via parallel pairwise r-fcn. In International conference on computer vision (pp. 4243–4251).
Zhang, J., Kalantidis, Y., Rohrbach, M., Paluri, M., Elgammal, A., & Elhoseiny, M. (2019a). Large-scale visual relationship understanding. Proceedings of the AAAI Conference on Artificial Intelligence, 33, 9185–9194.
Zhang, J., Shih, K. J., Elgammal, A., Tao, A., & Catanzaro, B. (2019b). Graphical contrastive losses for scene graph parsing. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 11535–11543).
Zhang, K., Zhang, Z., Li, Z., & Qiao, Y. (2016). Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10), 1499–1503.
Zhang, X., & LeCun, Y. (2017). Universum prescription: Regularization using unlabeled data. In AAAI (pp. 2907–2913).
Zhou, J. T., Pan, S. J., Mao, Q., & Tsang, I. W. (2012). Multi-view positive and unlabeled learning. In Asian conference on machine learning (pp. 555–570).
Zhu, Y., & Jiang, S. (2018). Deep structured learning for visual relationship detection. In AAAI Conference on artificial intelligence.
Zhuang, B., Liu, L., Shen, C., & Reid, I. (2017). Towards context-aware interaction recognition for visual relationship detection. In Proceedings of the IEEE international conference on computer vision (pp. 589–598).
Acknowledgements
This work was supported in part by the National Key R&D Program of China: Grant No. 2018AAA0100603, in part by the National Nature Science Foundation of China: Grant No. 61836002, and in part by the Australian Research Council Project: FL-170100117.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Li Liu, Matti Pietikäinen, Jie Qin, Jie Chen, Wanli Ouyang, Luc Van Gool.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhan, Y., Yu, J., Yu, T. et al. Multi-task Compositional Network for Visual Relationship Detection. Int J Comput Vis 128, 2146–2165 (2020). https://doi.org/10.1007/s11263-020-01353-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-020-01353-8