
Abstract
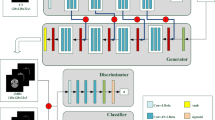
Multimodal medical images have been widely applied in various clinical diagnoses and treatments. Due to the practical restrictions, certain modalities may be hard to acquire, resulting in incomplete data. Existing methods attempt to generate the missing data with multiple available modalities. However, the modality differences in tissue contrast and lesion appearance become an obstacle to making a precise estimation. To address this issue, we propose an autoencoder-driven multimodal collaborative learning framework for medical image synthesis. The proposed approach takes an autoencoder to comprehensively supervise the synthesis network using the self-representation of target modality, which provides target-modality-specific prior to guide multimodal image fusion. Furthermore, we endow the autoencoder with adversarial learning capabilities by converting its encoder into a pixel-sensitive discriminator capable of both reconstruction and discrimination. To this end, the generative model is completely supervised by the autoencoder. Considering the efficiency of multimodal generation, we also introduce a modality mask vector as the target modality label to guide the synthesis direction, empowering our method to estimate any missing modality with a single model. Extensive experiments on multiple medical image datasets demonstrate the significant generalization capability as well as the superior synthetic quality of the proposed method, compared with other competing methods. The source code will be available: https://github.com/bcaosudo/AE-GAN.







Similar content being viewed by others


Data Availability
The data generated during the current study are available on reasonable request.
References
Blumberg, H. (1920). Hausdorff’s grundzüge der mengenlehre. Bulletin of the American Mathematical Society, 27(3), 116–129.
Bourlard, H., & Kamp, Y. (1988). Auto-association by multilayer perceptrons and singular value decomposition. Biological cybernetics, 59(4), 291–294.
Burgos, N., Cardoso, M. J., Thielemans, K., Modat, M., Pedemonte, S., Dickson, J., Barnes, A., Ahmed, R., Mahoney, C. J., Schott, J. M., Duncan, J. S., Atkinson, D., Arridge, S. R., Hutton, B. F., & Ourselin, S. (2014). Attenuation correction synthesis for hybrid pet-mr scanners: Application to brain studies. IEEE Transactions on Medical Imaging, 33(12), 2332–2341.
Cao, B., Zhang, H., Wang, N., Gao, X., & Shen, D. (2020). Auto-gan: Self-supervised collaborative learning for medical image synthesis. In Proceedings of the thirty-fourth AAAI conference on artificial intelligence, pp. 10486–10493.
Choi, Y., Choi, M., Kim, M., Ha, J.-W., Kim, S., & Choo, J. (2018). Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8789–8797.
Costa, P., Galdran, A., Meyer, M. I., Niemeijer, M., Abràmoff, M., Mendonça, A. M., & Campilho, A. (2017). End-to-end adversarial retinal image synthesis. IEEE Transactions on Medical Imaging, 37(3), 781–791.
Dalmaz, O., Mirza, U., Elmas, G., Özbey, M., Dar, S. U., Ceyani, E., Avestimehr, S., & Çukur, T. (2022a). One model to unite them all: Personalized federated learning of multi-contrast mri synthesis. arXiv preprint arXiv:2207.06509.
Dalmaz, O., Mirza, U., Elmas, G., Özbey, M., Dar, S. U., & Çukur, T. (2022b). A specificity-preserving generative model for federated mri translation. In Distributed, Collaborative, and Federated Learning, and Affordable AI and Healthcare for Resource Diverse Global Health: Third MICCAI Workshop, DeCaF 2022, and Second MICCAI Workshop, FAIR 2022, Held in Conjunction with MICCAI 2022, Singapore, September 18 and 22, 2022, Proceedings, pp. 79–88. Springer.
Dalmaz, O., Yurt, M., & Çukur, T. (2022). Resvit: residual vision transformers for multimodal medical image synthesis. IEEE Transactions on Medical Imaging, 41(10), 2598–2614.
Dice, L. R. (1945). Measures of the amount of ecologic association between species. Ecology, 26(3), 297–302.
Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2414–2423.
Georgopoulos, M., Oldfield, J., Nicolaou, M. A., Panagakis, Y., & Pantic, M. (2021). Mitigating demographic bias in facial datasets with style-based multi-attribute transfer. International Journal of Computer Vision, 129(7), 2288–2307.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. In Advances in Neural Information Processing Systems, pp. 2672–2680.
Han, L., Musunuri, S. H., Min, M. R., Gao, R., Tian, Y., & Metaxas, D. (2022). Ae-stylegan: Improved training of style-based auto-encoders. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 3134–3143.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778.
Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504–507.
Huang, Y., Shao, L., & Frangi, A. F. (2017). Cross-modality image synthesis via weakly coupled and geometry co-regularized joint dictionary learning. IEEE Transactions on Medical Imaging, 37(3), 815–827.
Ioffe, S. & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pp. 448–456.
Isola, P., Zhu, J.-Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1125–1134.
Jiang, L., Zhang, C., Huang, M., Liu, C., Shi, J., & Loy, C. C. (2020). TSIT: A simple and versatile framework for image-to-image translation. In European conference on computer vision, pp. 206–222.
Jiao, J., Yang, Q., He, S., Gu, S., Zhang, L., & Lau, R. W. (2017). Joint image denoising and disparity estimation via stereo structure pca and noise-tolerant cost. International Journal of Computer Vision, 124(2), 204–222.
Jog, A., Carass, A., Roy, S., Pham, D. L., & Prince, J. L. (2017). Random forest regression for magnetic resonance image synthesis. Medical Image Analysis, 35, 475–488.
Jog, A., Roy, S., Carass, A., & Prince, J. L. (2013). Magnetic resonance image synthesis through patch regression. In 2013 IEEE 10th international symposium on biomedical imaging, pp. 350–353. IEEE.
Karras, T., Laine, S., & Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4401–4410.
Kermi, A., Mahmoudi, I., & Khadir, M. T. (2018). Deep convolutional neural networks using u-net for automatic brain tumor segmentation in multimodal mri volumes. In International MICCAI Brainlesion Workshop, pp. 37–48. Springer.
Kim, K., & Myung, H. (2018). Autoencoder-combined generative adversarial networks for synthetic image data generation and detection of jellyfish swarm. IEEE Access, 6, 54207–54214.
Kim, Y. & Rush, A. M. (2016). Sequence-level knowledge distillation. arXiv preprint arXiv:1606.07947.
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., & Shi, W. (2017). Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4681–4690.
Lee, D., Kim, J., Moon, W.-J., & Ye, J. C. (2019). Collagan: Collaborative gan for missing image data imputation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2487–2496.
Lee, H.-Y., Tseng, H.-Y., Mao, Q., Huang, J.-B., Lu, Y.-D., Singh, M., & Yang, M.-H. (2020). Drit++: Diverse image-to-image translation via disentangled representations. International Journal of Computer Vision, 128(10), 2402–2417.
Li, R., Zhang, W., Suk, H.-I., Wang, L., Li, J., Shen, D., & Ji, S. (2014). Deep learning based imaging data completion for improved brain disease diagnosis. In International conference on medical image computing and computer-assisted intervention, pp. 305–312. Springer.
Liu, Y., Cao, J., Li, B., Yuan, C., Hu, W., Li, Y., & Duan, Y. (2019). Knowledge distillation via instance relationship graph. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7096–7104.
Maier, O., Menze, B., Gablentz, J., Häni, L., Heinrich, M., Liebrand, M., Winzeck, S., Basit, A., Bentley, P., Chen, L., Christiaens, D., Dutil, F., Egger, K., Feng, C., Glocker, B., Götz, M., Haeck, T., Halme, H.-L., Havaei, M., & Reyes, M. (2017). Isles 2015-a public evaluation benchmark for ischemic stroke lesion segmentation from multispectral mri. Medical Image Analysis, 35, 250–269.
Makhzani, A., Shlens, J., Jaitly, N., Goodfellow, I., & Frey, B. (2015). Adversarial autoencoders. arXiv preprint arXiv:1511.05644.
Menze, B. H., Jakab, A., Bauer, S., Kalpathy-Cramer, J., & Farahani, K. (2015). The multimodal brain tumor image segmentation benchmark (brats). IEEE Transactions on Medical Imaging, 34(10), 1993–2024.
Miller, M. I., Christensen, G. E., Amit, Y., & Grenander, U. (1993). Mathematical textbook of deformable neuroanatomies. Proceedings of the National Academy of Sciences, 90(24), 11944–11948.
Mirza, M. & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
Ng, A. (2011). Sparse autoencoder. CS294A Lecture notes, 72(2011):1–19.
Nie, D., & Shen, D. (2020). Adversarial confidence learning for medical image segmentation and synthesis. International Journal of Computer Vision, 128(10), 2494–2513.
Nie, D., Trullo, R., Lian, J., Petitjean, C., Ruan, S., Wang, Q., & Shen, D. (2017). Medical image synthesis with context-aware generative adversarial networks. In International conference on medical image computing and computer-assisted intervention, pp. 417–425. Springer.
Özbey, M., Dar, S. U., Bedel, H. A., Dalmaz, O., Özturk, Ş., Güngör, A., & Çukur, T. (2022). Unsupervised medical image translation with adversarial diffusion models. arXiv preprint arXiv:2207.08208.
Park, T., Efros, A. A., Zhang, R., & Zhu, J.-Y. (2020a). Contrastive learning for unpaired image-to-image translation. In European conference on computer vision, pp. 319–345. Springer.
Park, T., Liu, M.-Y., Wang, T.-C., & Zhu, J.-Y. (2019). Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 2337–2346.
Park, T., Zhu, J.-Y., Wang, O., Lu, J., Shechtman, E., Efros, A., & Zhang, R. (2020). Swapping autoencoder for deep image manipulation. Advances in Neural Information Processing Systems, 33, 7198–7211.
Perrin, R. J., Fagan, A. M., & Holtzman, D. M. (2009). Multimodal techniques for diagnosis and prognosis of Alzheimer’s disease. Nature, 461(7266), 916–922.
Preedanan, W., Kondo, T., Bunnun, P., & Kumazawa, I. (2018). A comparative study of image quality assessment. In 2018 international workshop on advanced image technology (IWAIT), pp. 1–4. IEEE.
Ramirez-Manzanares, A., & Rivera, M. (2006). Basis tensor decomposition for restoring intra-voxel structure and stochastic walks for inferring brain connectivity in dt-mri. International Journal of Computer Vision, 69(1), 77–92.
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In International conference on medical image computing and computer-assisted intervention, pp. 234–241. Springer.
Sauerbrei, W., & Royston, P. (1999). Building multivariable prognostic and diagnostic models: transformation of the predictors by using fractional polynomials. Journal of the Royal Statistical Society: Series A (Statistics in Society), 162(1), 71–94.
Shen, D., Wu, G., & Suk, H.-I. (2017). Deep learning in medical image analysis. Annual Review of Biomedical Engineering, 19(1), 221–248.
Singh, N. K., & Raza, K. (2021). Medical image generation using generative adversarial networks: A review (pp. 77–96). Health informatics: A computational perspective in healthcare.
Sun, L., Dong, W., Li, X., Wu, J., Li, L., & Shi, G. (2021). Deep maximum a posterior estimator for video denoising. International Journal of Computer Vision, 129(10), 2827–2845.
Torrado-Carvajal, A., Herraiz, J. L., Alcain, E., Montemayor, A. S., Garcia-Canamaque, L., Hernandez-Tamames, J. A., Rozenholc, Y., & Malpica, N. (2016). Fast patch-based pseudo-ct synthesis from t1-weighted mr images for pet/mr attenuation correction in brain studies. Journal of Nuclear Medicine, 57(1), 136–143.
Van Buuren, S., Boshuizen, H. C., & Knook, D. L. (1999). Multiple imputation of missing blood pressure covariates in survival analysis. Statistics in Medicine, 18(6), 681–694.
Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., Manzagol, P.-A., & Bottou, L. (2010). Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 11(12).
Wang, T.-C., Liu, M.-Y., Zhu, J.-Y., Tao, A., Kautz, J., & Catanzaro, B. (2018a). High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8798–8807.
Wang, Y., Zhou, L., Yu, B., Wang, L., Zu, C., Lalush, D. S., Lin, W., Wu, X., Zhou, J., & Shen, D. (2018). 3d auto-context-based locality adaptive multi-modality gans for pet synthesis. IEEE Transactions on Medical Imaging, 38(6), 1328–1339.
Wang, Z., Bovik, A., Sheikh, H., & Simoncelli, E. (2004). Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4), 600–612.
Xu, W., Keshmiri, S., & Wang, G. (2019). Adversarially approximated autoencoder for image generation and manipulation. IEEE Transactions on Multimedia, 21(9), 2387–2396.
Yurt, M., Dar, S. U., Erdem, A., Erdem, E., Oguz, K. K., & Çukur, T. (2021). Mustgan: Multi-stream generative adversarial networks for mr image synthesis. Medical Image Analysis, 70, 101944.
Zhang, H., & Ma, J. (2021). Sdnet: A versatile squeeze-and-decomposition network for real-time image fusion. International Journal of Computer Vision, 129(10), 2761–2785.
Zhang, L., Zhang, L., Mou, X., & Zhang, D. (2011). Fsim: A feature similarity index for image quality assessment. IEEE Transactions on Image Processing, 20(8), 2378–2386.
Zhang, X., Dong, H., Hu, Z., Lai, W.-S., Wang, F., & Yang, M.-H. (2020). Gated fusion network for degraded image super resolution. International Journal of Computer Vision, 128(6), 1699–1721.
Zhou, T., Fu, H., Chen, G., Shen, J., & Shao, L. (2020). Hi-net: Hybrid-fusion network for multi-modal mr image synthesis. IEEE Transactions on Medical Imaging, 39(9), 2772–2781.
Zhu, J.-Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pp. 2223–2232.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grants 62106171, 61925602, U22A2096, 62036007, and 62131015; in part by the Science and Technology Commission of Shanghai Municipality (STCSM) under Grant 21010502600; in part by the Technology Innovation Leading Program of Shaanxi under Grant 2022QFY01-15; in part by Open Research Projects of Zhejiang Lab under Grant 2021KG0AB01; in part by the Fundamental Research Funds for the Central Universities under Grant QTZX23042.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Communicated by Laurent Najman.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Discussions on Discriminator
1.1 A.1: Comparison with Multi-Scale Discriminator
Some previous methods (Wang et al., 2018a; Park et al., 2019) introduce multiple discriminators to discriminate images in different resolutions to enhance the discriminant capability and further improve the image synthetic quality. Here, we compare our model with Pix2PixHD (Wang et al., 2018a), which utilizes multi-scale generators and multi-scale discriminators. The results are shown in Table 8. Compared to the non-multi-scale version of Pix2Pix, Pix2PixHD synthesizes images with more precise details and higher quantitative scores. But there is still a considerable gap in comparison with our AE-GAN, which demonstrates the effectiveness of our model.
1.2 A.2: Comparison with Residual Discriminator
Recently, some previous works (Han et al., 2022; Kim & Myung, 2018; Xu et al., 2019) also adapt autoencoder in the generative tasks. Han et al. (2022) proposed a novel algorithm (AE-StyleGAN) to train a style-based autoencoder along with the generator by using a residual discriminator. Kim and Myung (2018) combined the autoencoder with the GAN model to synthesize the encoded vectors and used the discriminator to discriminate the vectors instead of images. Xu et al. (2019) also adapted an autoencoder to drive the generator to learn the latent codes, which used two discriminators to discriminate the latent codes and the reconstruction results. To further verify the effectiveness of our discriminator’s architecture, we have conducted experiments to replace our discriminator with the most recent residual discriminator in AE-StyleGAN (Han et al., 2022). As shown in Table 9, the performance degrades after replacing the discriminator of AE-StyleGAN. Compared with the residual discriminator, our autoencoder-based discriminator shows significant superiority, which demonstrates our effectiveness.
Appendix B: Hyperparameter Analysis
Since some of the competing methods are not specifically designed for medical image synthesis, their performance might be decreased by using the default parameters. For fairer comparisons, we tune the key hyperparameters of all the competing methods and choose the best results for the presentation. For Pix2Pix, CycleGAN, StarGAN, Hi-Net, CollaGAN, and our Auto-GAN and AE-GAN, they both contain the pixel-level reconstruction loss constraints on the generators, the weights of which are important hyperparameters. As most methods set this hyperparameter to 10 or 100 by default, we tune this parameter in the following five values: 1, 10, 50, 100, and 200. For CUT, we tune the hyperparameter of PatchNCE loss weight \(\lambda _X\) and \(\lambda _Y\). For TSIT, we tune the hyperparameter of perceptual loss \(\lambda _p\) and feature matching loss \(\lambda _{FM}\). The default weight of these hyperparameters is 1, so we tune these parameters in 0.1, 0.5, 1, 5, 10. Besides, for our AE-GAN, we also tune the parameter \(\lambda \) of self-representation loss. The results are shown in Table 10. According to the experimental results, the hyperparameter of Pix2Pix remains default as 100, CycleGAN, StarGAN, and Hi-Net are tuned to 50, CollaGAN and Auto-GAN are tuned to 200, CUT and TSIT are tuned to 10. The two hyperparameters \(\lambda \) and \(\gamma \) of our AE-GAN are set to 100 and 0.1, separately.

The qualitative comparisons of different imaging orientations on T2 modality of ISLES2015 dataset
Appendix C: Discussion on Imaging Orientations
For the ISLES2015 dataset, T2 modality is acquired in sagittal orientation, which results in relatively limited in-plane resolution in axial orientation compared to other modalities that are acquired in axial orientation. We conduct experiments to translate images that are acquired from one orientation to those that are acquired from another orientation, as shown in Fig. 8. Due to the in-plane resolution difference, the synthetic results show more blurry and inaccurate details. We have also provided quantitative evaluation in Table 11, the performance of translating the high-resolution image to the low-resolution is significantly better than the opposite experiment. This might be because the high-resolution plane provides more accurate information than the low-resolution plane, which improves the synthetic quality.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Cao, B., Bi, Z., Hu, Q. et al. AutoEncoder-Driven Multimodal Collaborative Learning for Medical Image Synthesis. Int J Comput Vis 131, 1995–2014 (2023). https://doi.org/10.1007/s11263-023-01791-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-023-01791-0