
Abstract
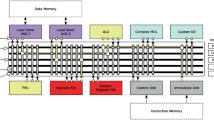
We introduce FlexCore, the first exemplar of an architecture based on the FlexSoC framework. Comprising the same datapath units found in a conventional five-stage pipeline, the FlexCore has an exposed datapath control and a flexible interconnect to allow the datapath to be dynamically reconfigured as a consequence of code generation. Additionally, the FlexCore allows specialized datapath units to be inserted and utilized within the same architecture and compilation framework. This study shows that, in comparison to a conventional five-stage general-purpose processor, the FlexCore is up to 40% more efficient in terms of cycle count on a set of benchmarks from the embedded application domain. We show that both the fine-grained control and the flexible interconnect contribute to the speedup. Furthermore, according to our VLSI implementation study, the FlexCore architecture offers both time and energy savings. The exposed FlexCore datapath requires a wide control word. The conducted evaluation confirms that this increases the instruction bandwidth and memory footprint. This calls for efficient instruction decoding as proposed in the FlexSoC framework.












Similar content being viewed by others

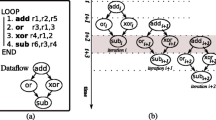
Notes
Register transfer notation.
It also complicates exception handling, which is however not the topic of this paper.
References
Hughes, J., Jeppson, K., Larsson-Edefors, P., Sheeran, M., Stenstrom, P., & Svensson, L. J. (2003). FlexSoC: Combining flexibility and efficiency in SoC designs. In Proceedings of the IEEE NorChip conference.
Reshadi, M., Gorjiara, B., & Gajski, D. (2005). Utilizing horizontal and vertical parallelism with no-instruction-set compiler for custom datapaths. In International conference on computer design (ICCD), October.
Mårts, J., & Carlqvist, T. (2006) A hardware audio decoder using flexible datapaths. MSc Thesis, Chalmers University of Technology, March.
Patterson, D. A., & Hennessy, J. L. (1998). Computer organization & design, the hardware/software interface (2nd ed.). Morgan Kaufman.
Kongetira, P., Aingaran, K., & Olukotun, K. (2005). Niagara: A 32-way multithreaded sparc processor. IEEE Micro, 25(2), 21–29.
Balakrishnan, S., Rajwar, R., Upton, M., & Lai, K. (2005). The impact of performance asymmetry in emerging multicore architectures. SIGARCH Computer Architecture News, 33(2), 506–517.
Reshadi, M., & Gajski, D. (2005). A cycle-accurate compilation algorithm for custom pipelined datapaths. In International symposium on hardware/software codesign and system synthesis (CODES+ISSS), September.
Encounter User Guid Version 6.2.
Själander, M., Larsson-Edefors, P., & Björk, M. (2007). A flexible datapath interconnect for embedded applications. In IEEE Computer Society Annual Symposium on VLSI, May.
Hartenstein, R. (2001). A decade of reconfigurable computing: a visionary retrospective. In Proceedings of design, automation and test in Europe, 2001 (pp. 642–649), March.
Ye, Z. A., Moshovos, A., Hauck, S., & Banerjee, P. (2000). CHIMAERA: A high-performance architecture with a tightly-coupled reconfigurable functional unit. In ISCA ’00: Proceedings of the 27th annual international symposium on computer architecture (pp. 225–235). New York, NY, USA: ACM Press.
M. B. T. et al. (2004). Evaluation of the RAW microprocessor: An exposed-wire-delay architecture for ILP and streams. In ISCA ’04: Proceedings of the 31st annual international symposium on computer architecture (p. 2). Washington, DC, USA: IEEE Computer Society.
K. S. et al. (2004). TRIPS: A polymorphous architecture for exploiting ILP, TLP, and DLP. ACM Trans. Archit. Code Optim., 1(1), 62–93.
Gorjiara, B., Reshadi, M., & Gajski, D. (2006). Designing a custom architecture for DCT using NISC design flow. In ASP-DAC’06 Design contest.
Corporaal, H. (1999). Ttas: Missing the ilp complexity wall. Journal of Systems Architecture, 45(12–13), 949–973.
Liang, X., Athalye, A., & Hong, S. (2005). Dynamic coarse grain dataflow reconfiguration technique for real-time systems design. In The 2005 IEEE international symposium on circuits and systems (pp. 3511–3514). IEEE Computer Society, May.
Nia, E., & Fatemi, O. (2003). Multimedia extensions for DLX processor. In Proceedings of the 10th IEEE international conference on electronics, circuits and systems (pp. 1010–1013), December.
Cheng, A., Tyson, G., & Mudge, T. (2004). FITS: Framework-based instruction-set tuning synthesis for embedded application specific processors. In DAC ’04: Proceedings of the 41st annual conference on design automation (pp. 920–923). ACM Press.
Cheng, A., Tyson, G., & Mudge, T. (2005). PowerFITS: Reduce dynamic and static i-cache power using application specific instruction set synthesis. In Performance analysis of systems and software, 2005. ISPASS 2005. IEEE International Symposium on (pp. 32–41).
Cheng, A. C., & Tyson, G. S. (2006). High-quality ISA synthesis for low-power cache designs in embedded microprocessors. IBM Journal of Research and Development, 50(2), 299–309.
Acknowledgements
We thank our FlexSoC colleagues (Hughes, Jeppson, Sheeran) for support and helpful discussions, Marius Grannæs for valuable comments, and Jonas Ferry for his help during the project. The FlexSoC project is sponsored by the Swedish Foundation for Strategic Research.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Thuresson, M., Själander, M., Björk, M. et al. FlexCore: Utilizing Exposed Datapath Control for Efficient Computing. J Sign Process Syst Sign Image Video Technol 57, 5–19 (2009). https://doi.org/10.1007/s11265-008-0172-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-008-0172-z