
Abstract
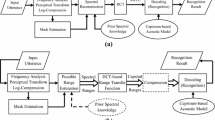
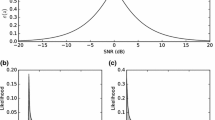
Automatic speech recognition under adverse noise conditions has been a challenging problem. Under noise conditions when the stationarity assumption is valid, effective techniques have been established to provide excellent recognition accuracies. Under the conditions when this assumption cannot hold, recognition performance de- clines rapidly. Missing data, MD, theory is a promising method for robust automatic speech recognition, ASR, under an y noise condition. Unfortunately, the choice of feature used in the recognizer process is commonly limited to spectral based representations. The combination of recognizers approach to MD ASR allows the use of cepstral based features within the MD framework through a fusion of features mechanism in the pat- tern recognition stage. It was found that under two types of non-stationary noise conditions the combined fused effect, experienced by the fusion process, increased recognition accuracies substantially over traditional MD and cepstral based recognizers.






Similar content being viewed by others

References
Atal, B. S. (1974). Effectiveness of linear prediction characteristics of the speech wave for automatic speaker identification and verification. The Journal of the Acoustical Society of America, 55, 1304–12.
Hermansky, H., & Morgan, N. (1994). RASTA processing of speech. IEEE Transactions on Speech and Audio Processing, 2(4), 578–589.
Klatt, D. (1976). A digital filter bank for spectral matching. In: IEEE ICASSP , International Conference on Acoustics, Speech, and Signal Processing, 1, 573–576.
Jr, T. G. S., Cannon, T. M., & Ingebretsen, R. B. (1975). Blind deconvolution through digital signal processing. Proceedings of the IEEE, 63(4), 678–692.
Varga, A.P ., Mo ore, R.K.: Hidden markov model decomposition of speech and noise. In: IEEE ICASSP, International Conference on Acoustics, Speech, and Signal Processing, 1990., pp. 845{848 (1990)
Gales, M. J. F., & Young, S. J. (1996). Robust continuous speech recognition using parallel model- combination. IEEE Transactions on Speech and Audio Processing, 4(5), 352–359.
Cooke, M., Green, P., Josifovski, L., & Vizinho, A. (2001). Robust automatic speech recognition with missing and unreliable acoustic data. Speech Communication, 34(3), 267–285.
Barker, J., Josifovski, L., Co ok e, M., Green, P .: Soft decisions in missing data techniques for robust automatic speech recognition. In: Sixth International Conference on Spoken Language Processing, pp. 373{376. ISCA (2000)
Acero, A., Stern, R.M.: Environmental robustness in automatic speech recognition. In: IEEE ICASSP International Conference on Acoustics, Speech, and Signal Processing, 1990., pp. 849{852 (1990)
Cerisara, C.: Towards missing data recognition with cepstral features. In: Eighth European Conference on Speech Communication and Technology , pp. 3057{3060. ISCA (2003)
VanHamme, H.: Robust speech recognition using cepstral domain missing data techniques and noisy masks. In: IEEE ICASSP , International Conference on Acoustics, Speech, and Signal Processing, vol. 1 (2004)
Hakkinen, J., Haverinen, H.: On the use of missing feature theory with cepstral features. In: Proc. CRAC Workshop (2001)
Raj, B., Seltzer, M.L., Stern, R.M.: Robust speech recognition: The case for restoring missing features (2001)
Chibelushi, C. C., Deravi, F., & Mason, J. S. D. (2002). A review of speech-based bimodal recognition. IEEE Transactions on Multimedia, 4(1), 23–37.
Raj, B., & Stern, R. M. (2005). Missing-feature approaches in speech recognition. Signal Processing Magazine, IEEE, 22(5), 101–116.
Bregman, A.S.: Auditory Scene Analysis: The Perceptual Organization of Sound. MIT Press (1990)
Cerisara, C., Demange, S., & Haton, J. P. (2007). On noise masking for automatic missing data speech recognition: A survey and discussion. Computer Speech & Language, 21(3), 443–457.
Marr, D. (1982). Vision: A Computational Investigation in to the Human Representation and Processing of Visual Information. New York: Holt.
VanHamme: Robust speech recognition using missing feature theory in the cepstral or LDA domain. In: Eighth European Conference on Speech Communication and Technology , pp. 1973{1976. ISCA (2003)
Campbell, J.P ., Reynolds, D.A., Dunn, R.B.: F using high–and Low-Level features for speaker recognition. In: Eighth European Conference on Speech Communication and Technology, pp. 2665{2668. ISCA (2003)
Bishop, C.M.: Pattern recognition and machine learning. Springer (2006)
Bengio, Y., & Frasconi, P. (1996). Input-output HMMs for sequence processing. IEEE Transactions on Neural Networks, 7(5), 1231–1249.
Saul, L. K., & Jordan, M. I. (1999). Mixed memory markov models: Decomposing complex stochastic processes as mixtures of simpler ones. Machine Learning, 37(1), 75–87.
Kristjansson, T. T., Frey, B. J., & Huang, T. S. (2000). Even t-coupled hidden markov models. In: IEEE ICME Multimedia and Expo, 1, 385–388.
Brand, M.: Coupled hidden markov models for modeling interacting processes (1997)
Pan, H., Levinson, S. E., Huang, T. S., & Liang, Z. P. (2004). A fused hidden markov model with application to bimodal speech 0. IEEE Transactions on Acoustics, Speech, and Signal Processing, 52(3), 573–581.
Cooke, M., Barker, J., Cunningham, S., & Shao, X. (2006). An audiovisual corpus for speech perception and automatic speech recognition. The Journal of the Acoustical Society of America, 120, 2421–2424.
Moore, B.C.J.: An Introduction to the Psychology of Hearing. Academic Press (2003)
Young, S.J., Woodland, P .C., Byrne, W.J.: HTK User, Reference and Programming Manual. Cambridge University, Engineering Department & Entropic Research Laboratory Inc. (1993)
Barker, J.: Respite case toolkit ctk v1.1.1 user’s guide. In: University of Sheffield (2001)
Varga, A., Steeneken, H.J.M., Tomlinson, M., Jones, D.: The NOISEX-92 study on the effect of additiv e noise on automatic speech recognition. DRA Speech Research Unit, Malvern, England, Tech. Rep (1992)
Tyagi, V., McCowan, I., Bourlard, H., Misra, H.: Mel-Cepstrum modulation spectrum (MCMS) features for robust ASR. In: IEEE ASR U (2003)
Barker, J. P., Cooke, M. P., & Ellis, D. P. W. (2005). Decoding speech in the presence of other sources. Speech Communication, 45(1), 5–25.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Joshi, N., Guan, L. Feature Fusion Applied to Missing Data ASR with the Combination of Recognizers. J Sign Process Syst Sign Image Video Technol 58, 359–370 (2010). https://doi.org/10.1007/s11265-009-0374-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-009-0374-z