
Abstract
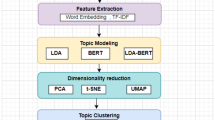
Natural Language Processing (NLP) applications have difficulties in dealing with automatically transcribed spoken documents recorded in noisy conditions, due to high Word Error Rates (WER), or in dealing with textual documents from the Internet, such as forums or micro-blogs, due to misspelled or truncated words, bad grammatical form… To improve the robustness against document errors, hitherto-proposed methods map these noisy documents in a latent space such as Latent Dirichlet Allocation (LDA), supervised LDA and author-topic (AT) models. In comparison to LDA, the AT model considers not only the document content (words), but also the class related to the document. In addition to these high-level representation models, an original compact representation, called c-vector, has recently been introduced avoid the tricky choice of the number of latent topics in these topic-based representations. The main drawback in the c-vector space building process is the number of sub-tasks required. Recently, we proposed both improving the performance of this c-vector compact representation of spoken documents and reducing the number of needed sub-tasks, using an original framework in a robust low dimensional space of features from a set of AT models called “Latent Topic-based Subspace” (LTS). This paper goes further by comparing the original LTS-based representation with the c-vector technique as well as with the state-of-the-art compression approach based on neural networks Encoder-Decoder (Autoencoder) and classification methods called deep neural networks (DNN) and long short-term memory (LSTM), on two classification tasks using noisy documents taking the form of speech conversations but also with textual documents from the 20-Newsgroups corpus. Results show that the original LTS representation outperforms the best previous compact representations with a substantial gain of more than 2.1 and 3.3 points in terms of correctly labeled documents compared to c-vector and Autoencoder neural networks respectively. An optimization algorithm of the scoring model parameters is then proposed to improve both the robustness and the performance of the proposed LTS-based approach. Finally, an automatic clustering approach based on the radial proximity between documents classes is introduced and shows promising performances.
















Similar content being viewed by others


Notes
The Universal Background Model (UBM) UBM is a GMM (Gaussian Mixture Model) that represents all the possible observations.
The name “bottleneck” is employed to better understand that features are extracted from the middle hidden layer even if this layer has a size greater or equal to other layers.
The UBM is a GMM that represents all the possible observations.
References
Abdi, H., & Williams, L.J. (2010). Principal component analysis. Wiley Interdisciplinary Reviews: Computational Statistics, 2(4), 433–459.
Albishre, K., Albathan, M., Li, Y. (2015). Effective 20 newsgroups dataset cleaning. In 2015 IEEE/WIC/ACM international conference on web intelligence and intelligent agent technology (WI-IAT) (Vol. 3, pp. 98–101). IEEE.
Bechet, F., Maza, B., Bigouroux, N., Bazillon, T., El-Beze, M., De Mori, R., Arbillot, E. (2012). Decoda: a call-centre human-human spoken conversation corpus. LREC’12.
Bengio, Y. (2009). Learning deep architectures for ai. Foundations and trends®;, in Machine Learning, 2(1), 1–127.
Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde-Farley, D., Bengio, Y. (2010). Theano: a CPU and GPU math expression compiler. In Proceedings of the python for scientific computing conference (SciPy). Oral Presentation.
Blei, D.M., & McAuliffe, J.D. (2010). Supervised topic models. arXiv:1003.0783.
Blei, D.M., Ng, A.Y., Jordan, M.I. (2003). Latent dirichlet allocation. The Journal of Machine Learning Research, 3, 993–1022.
Bouallegue, M., Morchid, M., Dufour, R., Driss, M., Linarès, G., De Mori, R. (2014). Subspace Gaussian mixture models for dialogues classification. In Conference of the international speech communication association (interspeech) 2014. ISCA.
Bousquet, P.M., Matrouf, D., Bonastre, J.F. (2011). Intersession compensation and scoring methods in the i-vectors space for speaker recognition. In Interspeech (pp. 485–488).
De Boer, P.T., Kroese, D.P., Mannor, S., Rubinstein, R.Y. (2005). A tutorial on the cross-entropy method. Annals of Operations Research, 134(1), 19–67.
Dehak, N., Kenny, P.J., Dehak, R., Dumouchel, P., Ouellet, P. (2011). Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 19(4), 788–798.
Eisenstein, J., & Barzilay, R. (2008). Bayesian unsupervised topic segmentation. In: Proceedings of the conference on empirical methods in natural language processing (pp. 334–343). ACL.
Golub, G.H., & Reinsch, C. (1970). Singular value decomposition and least squares solutions. Numerische Mathematik, 14(5), 403–420.
Hazen, T. (2011). Topic identification. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech, 12, 319–356.
Hinton, G.E., Osindero, S., Teh, Y.W. (2006). A fast learning algorithm for deep belief nets. Neural Computation, 18(7), 1527–1554.
Hinton, G.E., & Salakhutdinov, R.R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504–507.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Kamvar, S.D., Klein, D., Manning, C.D. Incremental spectral classification for weakly supervised text learning http://www.ai.mit.edu/jrennie/20Newsgroups/.
Kamvar, S.D., Klein, D., Manning, C.D. Incremental spectral classification for weakly supervised text learning.
Killian, J., Morchid, M., Dufour, R., Linarès, G. (2016). A log-linear weighting approach in the word2vec space for spoken language understanding. In Spoken language technology workshop (SLT), 2016 IEEE (pp 356–361). IEEE.
Lagus, K., & Kuusisto, J. (2002). Topic identification in natural language dialogues using neural networks. In Proceedings of the third SIGdial workshop on discourse and dialogue. https://doi.org/10.3115/1118121.1118135. http://www.aclweb.org/anthology/W02-1014 (pp. 95–102). Philadelphia: Association for Computational Linguistics.
LeCun, Y., Bengio, Y., Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
Linares, G., Nocéra, P., Massonie, D., Matrouf, D. (2007). The lia speech recognition system: from 10xrt to 1xrt. In Text, speech and dialogue (pp. 302–308). Springer.
Matrouf, D., Scheffer, N., Fauve, B.G., Bonastre, J.F. (2007). A straightforward and efficient implementation of the factor analysis model for speaker verification. In Interspeech (pp. 1242–1245).
Melamed, I., & Gilbert, M. (2011). Speech analytics. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech, 14, 397–416.
Mikolov, T., Corrado, G., Chen, K., Dean, J. (2013). Efficient estimation of word representations in vector space. In Proceedings of the international conference on learning representations (ICLR) 2013 (pp. 1–12).
Mohamed, A., Dahl, G., Hinton, G. (2009). Deep belief networks for phone recognition. In Nips workshop on deep learning for speech recognition and related applications.
Mohamed, A.R., Yu, D., Deng, L. (2010). Investigation of full-sequence training of deep belief networks for speech recognition. In INTERSPEECH (pp. 2846–2849).
Morchid, M. (2017). Internal memory gate for recurrent neural networks with application to spoken language understanding. In Proceedings of interspeech 2017 (pp. 3316–3319).
Morchid, M., Bouallegue, M., Dufour, R., Linarès, G., Matrouf, D., De Mori, R. (2015). Compact multiview representation of documents based on the total variability space. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 23(8), 1295–1308.
Morchid, M., Bouaziz, M., Ben Khedder, W., Janod, K., Bousquet, P.M., Dufour, R., Linarès, G. (2016). Spoken language understanding in a latent topic-based subspace. In Conference of the international speech communication association (INTERSPEECH) 2016. ISCA.
Morchid, M., Dufour, R., Bouallegue, M., Linarès, G. (2014). Author-topic based representation of call-center conversations. In International spoken language technology workshop (SLT) 2014. IEEE.
Morchid, M., Dufour, R., Bouallegue, M., Linarès, G., De Mori, R. (2014). Theme identification in human-human conversations with features from specific speaker type hidden spaces. In Conference of the international speech communication association (interspeech) 2014. ISCA.
Morchid, M., Dufour, R., Bousquet, P.M., Bouallegue, M., Linarès, G., De Mori, R. (2014). Improving dialogue classification using a topic space representation and a Gaussian classifier based on the decision rule. In ICASSP. IEEE.
Morchid, M., Dufour, R., Linarès, G. (2016). Impact of word error rate on theme identification task of highly imperfect human–human conversations. Computer Speech & Language, 38, 68–85.
Morchid, M., Dufour, R., Linarès, G., Hamadi, Y. (2015). Latent topic model based representations for a robust theme identification of highly imperfect automatic transcriptions. In International conference on intelligent text processing and computational linguistics (CICLing) 2015.
Purver, M. (2011). Topic segmentation. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech, 291–317.
Rosen-Zvi, M., Griffiths, T., Steyvers, M., Smyth, P. (2004). The author-topic model for authors and documents. In Proceedings of the 20th conference on uncertainty in artificial intelligence (pp. 487–494). AUAI Press.
Rubinstein, R.Y. (1997). Optimization of computer simulation models with rare events. European Journal of Operational Research, 99(1), 89–112.
Salakhutdinov, R., Mnih, A., Hinton, G. (2007). Restricted boltzmann machines for collaborative filtering. In Proceedings of the 24th international conference on machine learning (pp. 791–798). ACM.
Srivastava, N., Salakhutdinov, R.R., Hinton, G.E. (2013). Modeling documents with deep boltzmann machines. arXiv:1309.6865.
Tur, G., & De Mori, R. (2011). Spoken language understanding: systems for extracting semantic information from speech. New York: Wiley.
Van Asch, V. (2013). Macro-and micro-averaged evaluation measures [[basic draft]].
Yin, P.Y. (2007). Multilevel minimum cross entropy threshold selection based on particle swarm optimization. Applied Mathematics and Computation, 184(2), 503–513.
Yu, D., Deng, L., Wang, S. (2009). Learning in the deep-structured conditional random fields. In Proceedings of NIPS workshop (pp. 1–8).
Yu, D., Wang, S., Karam, Z., Deng, L. (2010). Language recognition using deep-structured conditional random fields. In 2010 IEEE international conference on acoustics speech and signal processing (ICASSP) (pp. 5030–5033). IEEE.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Morchid, M., Bousquet, PM., Kheder, W.B. et al. Latent Topic-based Subspace for Natural Language Processing. J Sign Process Syst 91, 833–853 (2019). https://doi.org/10.1007/s11265-018-1388-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-018-1388-1