
Abstract
Wireless sensor networking is a viable communication technology among low-cost and energy-limited sensor nodes deployed in an environment. Due to high operational features, the application area of this technology is extended significantly but with some energy related challenges. One main cause of the nodes energy wasting in these networks is idle listening characterized with no communication activity. This drawback can be mitigated by the means of energy-efficient multiple access control schemes so as to minimize idle listening. In this paper, we discuss the applicability of distributed learning algorithms namely reinforcement learning towards multiple access control (MAC) in wireless sensor networks. We perform a comparative review of relevant work in the literature and then present a cooperative multi agent reinforcement learning framework for MAC design in wireless sensor networks. Accordingly, the paper concludes with some major challenges and open issues of distributed MAC design using reinforcement learning.




Similar content being viewed by others
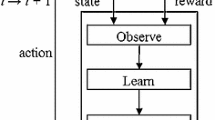

References
Boushaba, M., Hafid, A., & Benslimane, A. (2009). High accuracy localization method using AoA in sensor networks. Computer Networks, 53(18), 3076–3088.
Akyildiz, I. F., Su, W., Sankarasubramaniam, Y., & Cayirci, E. (2002). Wireless sensor networks: A survey. Computer Networks, 38(4), 393–422.
Akyildiz, I. F., & Vuran, M. (2010). Wireless sensor networks. London: Wiley.
Predd, J. B., Kulkarni, S. R., & Poor, H. V. (2006). Distributed learning in wireless sensor networks. IEEE Signal Processing Magazine, 23(4), 56–69.
Nguyen, X., Wainwright, M. J., & Jordan, M. I. (2005). Nonparametric decentralized detection using kernel methods. IEEE Transactions on Signal Processing, 53(11), 4053–4066.
Akkarajitsakul, K., Hossain, E., Niyato, D., & Kim, D. (2011). Game theoretic approaches for multiple access in wireless networks: A survey. IEEE Communications Surveys and Tutorials, 13(3), 372–395.
Ye, W., Heidemann, J., & Estrin, D. (2004). Medium access control with coordinated adaptive sleeping for wireless sensor networks. IEEE/ACM Transactions on Networking, 12(3), 493–506.
Dam, T. V., & Langendoen, K. (2003, November). An adaptive energy-efficient MAC protocol for wireless sensor networks. 1st ACM Conference on Embedded Networked Sensor Systems. CA: LosAngeles.
Demirkol, I., Ersoy, C., & Alagöz, F. (2006). MAC protocols for wireless sensor networks: A survey. IEEE Communications Magazine, 44(4), 115–121.
Huang, P., Xiao, L., Soltani, S., Mutka, M., & Xi, N. (2012). The evolution of MAC protocols in wireless sensor networks: A survey. IEEE Communications Surveys Tutorials, PP(99), 1–20.
Niu, J., & Deng, Z. (2011, in press). Distributed self-learning scheduling approach for wireless sensor network. Ad Hoc Networks.
Kaelbling, L. P., & Littman, M. L. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
Kulkarni, R. V., Forster, A., & Venayagamoorthy, G. K. (2011). Computational intelligence in wireless sensor networks: a survey. IEEE Communications Surveys and Tutorials, 13(1), 68–96.
Pandana, C., & Liu, K. J. R. (2005). Near-optimal reinforcement learning framework for energy-aware sensor communications. IEEE Journal on Selected Areas in Communications, 23(4), 788–797.
Chang, Y. H., Ho, T., & Kaelbling, L. P. (2004). Mobilized ad-hoc networks: A reinforcement learning approach. In Proceedings of International Conference on Autonomic Computing.
Dong, S., Agrawal, P., & Sivalingam, K. (2007). Reinforcement learning based geographic routing protocol for UWB wireless sensor network. In Proceedings of global telecommunications conference.
Förster, A., & Murphy, A. L. (2007). FROMS: Feedback routing for optimizing multiple sinks in WSN with reinforcement learning. In Proceedings of international conference intelligent sensors, sensor Network Information Processing (ISSNIP).
Yu, F. R., Wong, V., & Leong, V. (2008). A new QoS provisioning method for adaptive multimedia in wireless networks. IEEE Transactions on Vehicular Technology, 57(3), 1899–1909.
Alexandri, E., Martinez, G., & Zeghlache, D. (2002). A distributed reinforcement learning approach to maximize resource utilization and control hand over dropping in multimedia wireless networks. In Proceedings of indoor and mobile radio communication: International symposium on personal.
Yau, K., Komisarczuk, P., & Teal, P. (2010). Enhancing network performance in distributed cognitive radio networks using single-agent and multi-agent reinforcement learning. In Proceedings of conference on local computer networks.
Predd, J. B., Kulkarni, S. R., & Poor, H. V. (2006). Consistency in models for distributed learning under communication constraints. IEEE Transactions on Information Theory, 52(1), 52–63.
Gummeson, J., Ganesan, D., Corner, M. D., & Shenoy, P. (2010). An adaptive link layer for hetrogeneous multi-radio mobile sensor networks. IEEE Journal on Selected Areas in Communications, 28(7), 1094–1104.
Yau, K. A., Komisarczuk, P., & Teal, P. D. (2012). Reinforcement learning for context awareness and intelligence in wireless networks: Review, new features and open issues. Journal of Network and Computer Applications, 35(1), 253–267.
Liu, Z., & Elahanany, I. (2006). RL-MAC: A reinforcement learning based MAC protocol for wireless sensor networks. Internationa Journal on Sensor Networks, 1(3/4), 117–124.
Mihaylov, M., Tuyls, K., & Nowé, A. (2009). Decentralized learning in wireless sensor networks. In Proceedings of adaptive and learning agents workshop Budapest, Hungary.
Sutton, & Barto, (1998). Reinforcement learning: An introduction. Cambridge: MIT Press.
Ye, W., Heidemann, J., & Estrin, D. (2002). Mobility increases the capacity of ad hoc wireless networks. IEEE/ACM Transactions on Networking, 10(4), 477–486.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Fathi, M., Maihami, V. & Moradi, P. Reinforcement Learning for Multiple Access Control in Wireless Sensor Networks: Review, Model, and Open Issues. Wireless Pers Commun 72, 535–547 (2013). https://doi.org/10.1007/s11277-013-1028-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-013-1028-9