
Abstract
In this paper, we propose an online learning based intra-frame video coding approach, exploiting the texture sparsity of natural images. The proposed method is capable of learning the basic texture elements from previous frames with convergence guaranteed, leading to effective dictionaries for sparser representation of incoming frames. Benefiting from online learning, the proposed online dictionary learning based codec (ODL codec) is able to achieve a goal that the more video frames are being coded, the less non-zero coefficients are required to be transmitted. Then, these non-zero coefficients for image patches are further quantized and coded combined with dictionary synchronization. The experimental results demonstrate that the number of non-zero coefficients of each frame decreases rapidly while more frames are encoded. Compared to the off-line mode training, the proposed ODL codec, learning from video on the fly, is able to reduce the computational complexity with fast convergence. Finally, the rate distortion performance shows improvement in terms of PSNR compared with the K-SVD dictionary based compression and H.264/AVC for intra-frame video at low bit rates.






Similar content being viewed by others
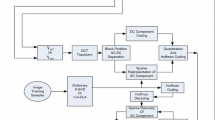

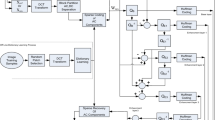
Notes
The state-of-the-art K-SVD dictionary is well learned off-line from large numbers of training data.
References
Aharon, M., & Elad, M. (2006). K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Transactions on Signal Processing, 54(11), 4311–4322.
Bross, B., Han, W. J., Ohm, J. R., & Sullivan, G. (2012). High efficiency video coding (HEVC) text specification draft 8. document JCTVC-J1003.
Bryt, O., & Elad, M. (2008). Compression of facial images using the K-SVD algorithm. Journal of Visual Communication and Image Representation, 19(4), 270–282.
Candes, E. J., Romberg, J., & Tao, T. (2006). Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on Information Theory, 52(2), 489–509.
Cisco visual networking index (VNI). (2012). Global mobile data traffic forecast 2012–2017.
Dai, W., & Milenkovic, O. (2009). Subspace pursuit for compressive sensing signal reconstruction. IEEE Transactions on Information Theory, 55(5), 2230–2249.
ISO/IEC 15444–1 (2000). JPEG 2000 Part I Final Committee Draft Version 1.0.
Kang, J. W., Kuo, C. C., Cohen, R., & Vetro, A. (2011). Efficient dictionary based video coding with reduced side information. In 2011 IEEE International Symposium on Circuits and Systems (ISCAS) (pp. 109–112).
Karklin, Y., & Lewicki, M. (2008). Emergence of complex cell properties by learning to generalize in natural scenes. Nature, 457(7225), 83–86.
Lee, H., Battle, A., Raina, R., & Ng, A.Y. (2006). Efficient sparse coding algorithms. In Advances in neural information processing systems (NIPS’06) (pp. 801–808).
Mairal, J., & Bach, F. (2009). Online dictionary learning for sparse coding. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML’09 (pp. 689–696). ACM.
Mairal, J., & Bach, F. (2010). Online learning for matrix factorization and sparse coding. Journal of Machine Learning Research, 11, 19–60.
Mallat, S., & Zhang, Z. (1993). Matching pursuits with time-frequency dictionaries. IEEE Transactions on Signal Processing, 41(12), 3397–3415.
Marpe, D. (2006). The H.264/MPEG4 advanced video coding standard and its applications. IEEE Communications Magazine, 44(8), 134–143.
Needell, D., & Tropp, J. (2009). Cosamp: Iterative signal recovery from incomplete and inaccurate samples. Applied and Computational Harmonic Analysis, 26(3), 301–321.
Neff, R., & Zakhor, A. (1997). Very low bit-rate video coding based on matching pursuits. Circuits and Systems for Video Technology, IEEE Transactions on, 7(1), 158–171.
Neff, R., & Zakhor, A. (2002). Matching pursuit video coding. i. Dictionary approximation. Circuits and Systems for Video Technology, IEEE Transactions on, 12(1), 13–26.
Olshausen, B., & Field, D. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381, 607–609.
Olshausen, B. A., & Field, D. J. (1997). Sparse coding with an overcomplete basis set: A strategy employed by v1? Vision Research, 37, 3311–3325.
Pati, Y., & Rezaiifar, R. (1993). Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition. In 1993 Conference Record of The Twenty-Seventh Asilomar Conference on Signals Systems and Computers (Vol. 1, pp. 40–44).
Rubinstein, R. (2010). Dictionaries for sparse representation modeling. Proceedings of the IEEE, 98(6), 1045–1057.
Skretting, K., & Engan, K. (2011). Image compression using learned dictionaries by RLS-DLA and compared with K-SVD. In 2011 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP) (pp. 1517–1520).
Skretting, K., & Engan, K. (2010). Recursive least squares dictionary learning algorithm. IEEE Transactions on Signal Processing, 58(4), 2121–2130.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological), 58(1), 267–288.
Trevor, B. E., & Hastie, T. (2002). Least angle regression. Annals of Statistics, 32, 407–499.
Tseng, P. (2001). Convergence of a block coordinate descent method for nondifferentiable minimization. Journal of Optimization Theory and Applications, 109(3), 475–494.
Turkan, M, & Guillemot, C. (2011). Online dictionaries for image prediction. In 2011 18th IEEE International Conference on Image Processing (ICIP) (pp. 293–296).
Wiegand, T., Sullivan, G., Bjontegaard, G., & Luthra, A. (2003). Overview of the H.264/AVC video coding standard. IEEE Transactions on Circuits and Systems for Video Technology, 13(7), 560–576.
Zepeda, J., & Guillemot, C. (2011). Image compression using sparse representations and the iteration-tuned and aligned dictionary. IEEE Journal of Selected Topics in Signal Processing, 5(5), 1061–1073.
Acknowledgments
The authors would like to thank the anonymous reviews for their valuable comments and suggestions that highly improve the quality of the paper. The authors would also like to thank Xuan Dong, the Ph.D candidate at the Dept. of Computer Science, Tsinghua University, for giving a helping hand. This work was supported by the National Basic Research Project of China (973) (2013CB329000, 2013CB329006), National Natural Science Foundation of China (NSFC, No.61101071, 61021001, 60972021, 61202139) and Tsinghua-Qualcomm Joint Research Program.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Sun, Y., Xu, M., Tao, X. et al. Online Dictionary Learning Based Intra-frame Video Coding. Wireless Pers Commun 74, 1281–1295 (2014). https://doi.org/10.1007/s11277-013-1577-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-013-1577-y