
Abstract
In this paper novel algorithms are introduced for solving NP hard discrete quadratic optimization problems commonly referred to as unconstrained binary quadratic programming. The proposed methods are based on hypergraph representation and recursive reduction of the dimension of the search space. In this way, efficient and fast search can be carried out and high quality suboptimal solutions can be obtained in real-time. The new algorithms can directly be applied to the quadratic problems of present day communication technologies, such as multiuser detection and scheduling providing fast optimization and increasing the performance. In the case of multiuser detection, the achieved bit error rate can approximate the Bayesian optimum and in the case of scheduling better Weighted Tardiness can be achieved by running the proposed algorithms. The methods are also tested on large scale quadratic problems selected from ORLIB and the solutions are compared to the ones obtained by traditional algorithms, such as Devour digest tidy-up, Hopfield neural network, local search, Taboo search and semi definite relaxing. As the corresponding performance analysis reveals the proposed methods can perform better than the traditional ones with similar complexity.























Similar content being viewed by others

References
Aumage, O., Brunet, E., Furmento, N., & Namyst, R. (2007). New madeleine: A fast communication scheduling engine for high performance networks. In Parallel and distributed processing symposium, 2007. IPDPS 2007. IEEE international (pp. 1–8). doi:10.1109/IPDPS.2007.370476.
Barahona, F. (1986). A solvable case of quadratic 0–1 programming. Discrete Applied Mathematics, 13(1), 23–26.
Barahona, F., Jünger, M., & Reinelt, G. (1989). Experiments in quadratic 0–1 programming. Mathematical Programming, 44(1), 127–137.
Beasley, J. (1998). Heuristic algorithms for the unconstrained binary quadratic programming problem. London: Management School, Imperial College.
Beasley, J. E. (1990). OR-Library: Distributing test problems by electronic mail. Journal of the Operational Research Society, 41(11), 1069–1072.
Billionnet, A., & Elloumi, S. (2007). Using a mixed integer quadratic programming solver for the unconstrained quadratic 0–1 problem. Mathematical Programming, 109, 55–68. doi:10.1007/s10107-005-0637-9.
Boros, E., Hammer, P., & Sun, X. (1989). The ddt method for quadratic 0–1 minimization. RUTCOR Research Center, RRR, 39, 89.
Boros, E., Hammer, P., & Tavares, G. (2007). Local search heuristics for quadratic unconstrained binary optimization (qubo). Journal of Heuristics, 13(2), 99–132.
Chicano, F., & Alba, E. (2011). Elementary landscape decomposition of the 0–1 unconstrained quadratic optimization. Journal of Heuristics pp, 1–18. doi:10.1007/s10732-011-9170-6.
Choi, H., Wang, J., & Hughes, E. (2009). Scheduling for information gathering on sensor network. Wireless Networks, 15, 127–140. doi:10.1007/s11276-007-0050-9.
Damen, M., El Gamal, H., & Caire, G. (2003). On maximum-likelihood detection and the search for the closest lattice point. Information Theory, IEEE Transactions on, 49(10), 2389–2402. doi:10.1109/TIT.2003.817444.
De Simone, C. (1990). The cut polytope and the boolean quadric polytope. Discrete Mathematics, 79(1), 71–75.
For Official Publications of the European Communities O. (1989). Digital land mobile radio communications: cost 207, final report. Technical Report.
Fogarasi, N., Tornai, K., & Levendovszky, J. (2012). A novel hopfield neural network approach for minimizing total weighted tardiness of jobs scheduled on identical machines. Acta Univ Sapientiae Informatica, 4(1), 48–66.
Garey, M., & Johnson, D. (1979). Computers and intractability (Vol. 174). San Francisco, CA: Freeman.
Glover, F., Kochenberger, G., & Alidaee, B. (1998). Adaptive memory tabu search for binary quadratic programs. Management Science, 44, 336–345.
Glover, F., Alidaee, B., Rego, C., & Kochenberger, G. (2002). One-pass heuristics for large-scale unconstrained binary quadratic problems. European Journal of Operational Research, 137(2), 272–287.
Gold, R. (1967). Optimal binary sequences for spread spectrum multiplexing (corresp.). IEEE Transactions on Information Theory, 13(4), 619–621. doi:10.1109/TIT.1967.1054048.
Hanafi, S., Rebai, A. R., & Vasquez, M. (2011). Several versions of the devour digest tidy-up heuristic for unconstrained binary quadratic problems. Journal of Heuristics, 1–33. doi:10.1007/s10732-011-9169-z.
Haykin, S., & Moher, M. (2006). An introduction to analog and digital communications. London: Wiley.
Helmberg, C., & Rendl, F. (1998). Solving quadratic (0, 1)-problems by semidefinite programs and cutting planes. Mathematical Programming, 82(3), 291–315.
Kaddoum, G., & Gagnon, F. (2013). Fast communication: Performance analysis of STBC-CSK communication system over slow fading channel. Signal Processing, 93(7), 2055–2060. doi:10.1016/j.sigpro.2012.12.020.
Kaddoum, G., Chargeé, P., Roviras, D., & Fournier-Prunaret, D. (2009). A methodology for bit error rate prediction in chaos-based communication systems. Circuits, Systems and Signal Processing, 28(6), 925–944. doi:10.1007/s00034-009-9124-5.
Kochenberger, G., Glover, F., Alidaee, B., & Rego, C. (2004a). Solving combinatorial optimization problems via reformulation and adaptive memory metaheuristics. In Menon, A. (ed) Frontiers of evolutionary computation, genetic algorithms and evolutionary computation (vol. 11, pp. 103–113). Springer, US. doi:10.1007/1-4020-7782-3_5.
Kochenberger, G., Glover, F., Alidaee, B., & Rego, C. (2004b). A unified modeling and solution framework for combinatorial optimization problems. OR Spectrum, 26(2), 237–250.
Larsson, E. (2009). Mimo detection methods: How they work [lecture notes]. Signal Processing Magazine, IEEE, 26(3), 91–95. doi:10.1109/MSP.2009.932126.
Levendovszky, J., Tornai, K., Treplan, G., & Olah, A. (2011). Novel load balancing algorithms ensuring uniform packet loss probabilities for wsn. In Vehicular technology conference (VTC Spring), 2011 IEEE 73rd (pp. 1–5). doi:10.1109/VETECS.2011.5956703.
Li, H., Shenoy, P., & Ramamritham, K. (2005). Scheduling messages with deadlines in multi-hop real-time sensor networks. In Real time and embedded technology and applications symposium, 2005. RTAS 2005. 11th IEEE (pp. 415–425). doi:10.1109/RTAS.2005.48.
Lodi, A., Allemand, K., & Liebling, T. (1999). An evolutionary heuristic for quadratic 0–1 programming. European Journal of Operational Research, 119(3), 662–670.
Luo, Z., Ma, W., So, A., Ye, Y., & Zhang, S. (2010). Semidefinite relaxation of quadratic optimization problems. Signal Processing Magazine, IEEE, 27(3), 20–34.
Merz, P., & Freisleben, B. (2002). Greedy and local search heuristics for unconstrained binary quadratic programming. Journal of Heuristics, 8, 197–213. doi:10.1023/A:1017912624016.
Merz, P., & Katayama, K. (2004). Memetic algorithms for the unconstrained binary quadratic programming problem. Biosystems, 78(1–3), 99–118. doi:10.1016/j.biosystems.2004.08.002.
Palubeckis, G. (2006). Iterated tabu search for the unconstrained binary quadratic optimization problem. Informatica, 17(2), 279–296.
Picard, J.-C., & Ratliff, H. D. (1973). Mathematical programming and its applications. Operations Research, 21(1), 261–269.
Picard, J., & Ratliff, H. (1975). Minimum cuts and related problems. Networks, 5(4), 357–370.
Poljak, S., Rendl, F., & Wolkowicz, H. (1995). A recipe for semidefinite relaxation for (0, 1)-quadratic programming. Journal of Global Optimization, 7(1), 51–73.
Proakis, J., & Salehi, M. (2007). Digital communications (5th ed.). London: McGraw-Hill Science/Engineering/Math.
Rahnama, N., & Talebi, S. (2013). Performance comparison of chaotic spreading sequences generated by two different classes of chaotic systems in a chaos-based direct sequencecode division multiple access system. Communications, IET, 7(10), 1024–1031. doi:10.1049/iet-com. 2012.0763.
Smith, K., Palaniswami, M., & Krishnamoorthy, M. (1998). Neural techniques for combinatorial optimization with applications. Neural Networks, IEEE Transactions on, 9(6), 1301–1318.
Smith, K. A. (1999). Neural networks for combinatorial optimization: A review of more than a decade of research. INFORMS Journal on Computing, 11(1), 15–34. doi:10.1287/ijoc.11.1.15 http://joc.journal.informs.org/content/11/1/15.abstract, http://joc.journal.informs.org/content/11/1/15.full.pdf+html.
Verdu, S. (1998). Multiuser detection. Cambridge: Cambridge University Press.
Wang, J. (2010). Discrete hopfield network combined with estimation of distribution for unconstrained binary quadratic programming problem. Expert Systems with Applications, 37(8), 5758–5774.
Acknowledgments
The support of the Grants TÁMOP-4.2.1.B-11/2/KMR-2011-0002 and TÁMOP-4.2.2./B-10/1-2010-0014 are gratefully acknowledged. One author (Andras Olah) would like to acknowledge the support of the Bolyai Janos Research Scholarship of the Hungarian Academy of Sciences. This work was also supported by the European Union and the European Social Fund through project FuturICT.hu (Grant No. TAMOP-4.2.2.C-11/1/KONV-2012-0013).
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
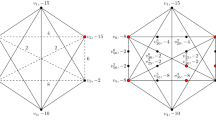
1.1 Description of the Algorithms
In this appendix we give the precise definition of the algorithms used in this article. We define the rules presented in Sect. 4.
1.1.1 Dimension Reduction of the Greedy Algorithm: L01
This algorithm uses a greedy strategy at the hypergraph level to determine in which direction the next hypernode falls. The algorithm stores the best N dimension candidate solution in \(\mathbf {y^{opt}}\).
-
1.
The algorithm starts at the original N dimension hypernode.
-
2.
The inner solver is chosen to be a DHNN structure.
-
3.
The performance of a “candidate solution” is defined by the value of the N dimension quadratic function on this solution.
-
4.
We use the “inner solver” in every hypernode.
-
5.
The next \(n-1\) dimension hypernode is chosen from an \(n\le \hbox {N}\) dimension hypernode as follows (\(\Psi \)): We search all the possible \(n-1\) dimension hypernodes accessible from the current hypernode, and pick the best among them, which is performed by the following steps:
-
We assume that if we are in an arbitrary \(n\le \hbox {N}\) dimension hypernode the best N dimension candidate solutions is accessible in \(\mathbf {y}^{opt}\).
-
We select a starting point in an \(n-1\) dimension hypernode for the “inner solver” from the actual \(\mathbf {y}^{opt}\) by discarding the appropriate dimensions.
-
In each \(n-1\) dimension hypernode the “inner solver” generates a \(n-1\) dimension candidate solution, we denote it with \(\mathbf {y^*}^{(i)}(\hbox {next})\).
-
We map every \(\mathbf {y^*}^{(i)}(\hbox {next})\) back to the original N dimension space by filling the missing coordinates of \(\mathbf {y^\dagger }^{(i)}(\hbox {next})\) with the coordinates of \(\mathbf {y}^{opt}\).
-
According to the N dimension quadratic function we pick the best \(\mathbf {y^\dagger }^{(i)}(\hbox {next})\) and compare with the value of the quadratic function taken over \(\mathbf {y}^{opt}\).
-
If the performance is improved we choose that hypernode.
-
-
6.
If not, the algorithm stops.
1.1.2 Dimension Reduction of the First Chance Algorithm: D01
This algorithm is different from the one described above in one rule. We do not evaluate all possible lower dimension hypernodes, but if we find one which gives a better candidate solution then we choose that hypernode. So instead of a full evaluation we introduce a “first-improve” strategy.
-
1.
The algorithm starts at the original N dimension hypernode.
-
2.
The inner solver is chosen to be a DHNN structure.
-
3.
The performance of a “candidate solution” is defined by the value of the N dimension quadratic function on this solution.
-
4.
We use the “inner solver” in every hypernode.
-
5.
The next hypernode from an \(n\le \hbox {N}\) dimension hypernode is chosen as follows \((\Psi )\). We pick one by one a possible \(n-1\) dimension hypernode from the current node and if it improves our current candidate solution, we choose that hypernode, which is performed by the following steps:
-
We assume that if we are in an arbitrary \(n\le \hbox {N}\) dimension hypernode the best N dimension candidate solutions is accessible in \(\mathbf {y}^{opt}\).
-
We select a starting point in an \(n-1\) dimension hypernode for the “inner solver” from the actual \(\mathbf {y}^{opt}\) by discarding the appropriate dimensions.
-
In that \(n-1\) dimension hypernode the “inner solver” generates one specific \(n-1\) dimension candidate solution, we denote it by \(\mathbf {y^*}^{(i)}(\hbox {next})\).
-
We map \(\mathbf {y^*}^{(i)}(\hbox {next})\) back to the original N dimension space by filling the missing coordinates of \(\mathbf {y^\dagger }^{(i)}(\hbox {next})\) with the coordinates of \(\mathbf {y}^{opt}\).
-
According to the N dimension quadratic function we compare them with each other.
-
If the performance is improved we choose that hypernode.
-
If not, we try another not yet inspected hypernode in the \(n-1\) dimension regime.
-
-
6.
If we inspected every possible \(n-1\) dimension hypernode and did not find a better candidate solution, the algorithm stops.
1.1.3 The Description of Dimension Adder DA01 Algorithm
This algorithm constructs a candidate solution gradually by adding dimensions starting from a low dimension hypernode until it reaches the highest dimension hypernode.
-
1.
The algorithm starts from the 0 dimension hypernode.
-
2.
The inner solver is chosen to be a DHNN structure.
-
3.
The performance of a candidate solution depends on the dimension as we leave out the corresponding parts of the matrix and vector of the original N dimension quadratic function
-
4.
We use the “inner solver” in every hypernode.
-
5.
The next hypernode from an \(n\le \hbox {N}\) dimension hypernode is chosen as follows \((\Psi )\): We pick one by one a possible \(n+1\) dimension hypernode from the current node and if it improves our current candidate solution, we choose that hypernode, which is performed by the following steps:
-
We denote the set containing the indices of the coordinates of the current \(n\) dimension hypernode with \( C \). We denote the proposed candidate solution in this hypernode with \(\mathbf {y}^*\).
-
We choose randomly a dimension which has not yet been picked, denoted by: \( B =\{i\},i\ni C \).
-
We inspect the \(n+1\) dimension hypernode with dimension indices \( A = C \cup B \) with the “inner solver”.
-
At the inspected \(n+1\) dimension hypernode the starting point of the “inner solver” (denoted by \(\mathbf {y}\)) is generated via copying the appropriate coordinates from the best found candidate solution and computing the missing coordinate via the gradient. \(\mathbf {y}_ C =\mathbf {y}^*\) and \(\mathbf {y}_\mathrm{B}=-{{\mathrm{sgn}}}(\mathbf {W^\mathrm{orig}}_\mathrm{B,C} \cdot \mathbf {y}^* - \mathbf {b^\mathrm{orig}}_\mathrm{B})\)
-
We use the “inner solver” to get \(\mathbf {y^*}\hbox {(next)}\) from \(\mathbf {y}\).
-
-
6.
If the Nth dimension was also added to the problem we stop and put \(\mathbf {y}^{opt}=\mathbf {y^*}\hbox {(next)}\).
1.1.4 The Description of the Dimension Adder DA02 Algorithm
This algorithm is similar DA01 algorithm. It also constructs a candidate solution from a lower dimension one, but instead of a first-improve hypernode choice strategy this inspects all the possible one distance higher dimension hypernodes and chooses the best one.
-
1.
The algorithm starts from the 0 dimension hypernode.
-
2.
The “inner solver” is a DHNN structure.
-
3.
The performance of a candidate solution here is dynamic. It is determined by the current \(n=1\cdots \hbox {N}\) dimension quadratic function.
-
4.
We use the “inner solver” in every hypernode.
-
5.
The strategy by which we choose the next hypernode (\(\Psi \)) is the following:
-
We assume that if we are in an \(n\) dimension hypernode, we also know the indices of the coordinates of the said hypernode. We denote this set with \( C \), and the proposed candidate solution in this hypernode with \(\mathbf {y}^*\).
-
We iterate through every dimension index which we did not inspect so far:\(\forall i: B =\{i\},i\ni C \). We inspect all the possible \(n+1\) dimension hypernode with dimension indices \( A = C \cup B \) with the “inner solver”.
-
At each inspected \(n+1\) dimension hypernode the starting point of the “inner solver” (denoted by \(\mathbf {y}^{(i)}\)) is generated via copying the appropriate coordinates from the best found candidate solution and computing the missing coordinate via the gradient. \(\mathbf {y}^{(i)}_ C =\mathbf {y}^*\) and \(\mathbf {y}^{(i)}_\mathrm{B}=-{{\mathrm{sgn}}}(\mathbf {W^\mathrm{orig}}_\mathrm{B,C} \cdot \mathbf {y}^* - \mathbf {b^\mathrm{orig}}_\mathrm{B})\)
-
We use the “inner solver” to get \(\mathbf {y^*}^{(i)}\hbox {(next)}\) from \(\mathbf {y}^{(i)}\).
-
We choose the best performing \(\mathbf {y^*}^{(i)}\hbox {(next)}\) and the corresponding hypernode for the next iteration.
-
-
6.
If the Nth dimension was inspected as well the algorithm stops, and we put \(\mathbf {y}^{opt}=\mathbf {y^*}\hbox {(next)}\).
1.2 Run-Time and Performance Analysis Tables
Rights and permissions
About this article
Cite this article
Tisza, D., Oláh, A. & Levendovszky, J. Novel Algorithms for Quadratic Programming by Using Hypergraph Representations. Wireless Pers Commun 77, 2305–2339 (2014). https://doi.org/10.1007/s11277-014-1639-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-014-1639-9