
Abstract
In the training process of deep learning models, one of the important steps is to choose an appropriate optimizer that directly determines the final performance of the model. Choosing the appropriate direction and step size (i.e. learning rate) of parameter update are decisive factors for optimizers. Previous gradient descent optimizers could be oscillated and fail to converge to a minimum point because they are only sensitive to the current gradient. Momentum-Based Optimizers (MBOs) have been widely adopted recently since they can relieve oscillation to accelerate convergence by using the exponentially decaying average of gradients to fine-tune the direction. However, we find that most of the existing MBOs are biased and inconsistent with the local fastest descent direction resulting in a high number of iterations. To accelerate convergence, we propose an Unbiased strategy to adjust the descent direction of a variety of MBOs. We further propose an Unbiased Quasi-hyperbolic Nesterov-gradient strategy (UQN) by combining our Unbiased strategy with the existing Quasi-hyperbolic and Nesterov-gradient. It makes each update step move in the local fastest descent direction, predicts the future gradient to avoid crossing the minimum point, and reduces gradient variance. We extend our strategies to multiple MBOs and prove the convergence of our strategies. The main experimental results presented in this paper are based on popular neural network models and benchmark datasets. The experimental results demonstrate the effectiveness and universality of our proposed strategies.








Similar content being viewed by others


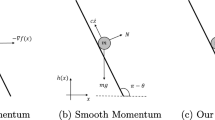
Data availability
The data sets supporting the results of this article are included within the article.
Notes
References
Nebel, B.: On the compilability and expressive power of propositional planning formalisms. J. Artif. Intell. Res. 12, 271–315 (2000)
Lessard, L., Recht, B., Packard, A.K.: Analysis and design of optimization algorithms via integral quadratic constraints. SIAM J. Optim. 26(1), 57–95 (2016)
Zhong, H., Chen, Z., Qin, C., Huang, Z., Zheng, V.W., Xu, T., Chen, E.: Adam revisited: a weighted past gradients perspective. Frontiers Comput. Sci. 14(5), 145309 (2020)
Jin, D., He, J., Chai, B., He, D.: Semi-supervised community detection on attributed networks using non-negative matrix tri-factorization with node popularity. Frontiers of Computer Science 15(4), 1–11 (2021)
Ye, Y., Gong, S., Liu, C., Zeng, J., Jia, N., Zhang, Y.: Online belief propagation algorithm for probabilistic latent semantic analysis. Frontiers Comput. Sci. 7(4), 526–535 (2013)
Tan, Z., Chen, S.: On the learning dynamics of two-layer quadratic neural networks for understanding deep learning. Frontiers Comput. Sci. 16(3), 163313 (2022)
Bühlmann, P., Yu, B.: Boosting with the l 2 loss: regression and classification. Journal of the American Statistical Association 98(462), 324–339 (2003)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. Commun. ACM 60(6), 84–90 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Gehring, J., Auli, M., Grangier, D., Yarats, D., Dauphin, Y.N.: Convolutional sequence to sequence learning. In: Proceedings of the 34th International Conference on Machine Learning, ICML 2017, vol. 70, pp. 1243–1252 (2017)
Dong, Q., Niu, S., Yuan, T., Li, Y.: Disentangled graph recurrent network for document ranking. Data Sci. Eng. 7(1), 30–43 (2022)
He, J., Liu, H., Zheng, Y., Tang, S., He, W., Du, X.: Bi-labeled LDA: inferring interest tags for non-famous users in social network. Data Sci. Eng. 5(1), 27–47 (2020)
Abburi, H., Parikh, P., Chhaya, N., Varma, V.: Fine-grained multi-label sexism classification using a semi-supervised multi-level neural approach. Data Sci. Eng. 6(4), 359–379 (2021)
Xue, H., Xu, H., Chen, X., Wang, Y.: A primal perspective for indefinite kernel SVM problem. Frontiers Comput. Sci. 14(2), 349–363 (2020)
Jain, P., Kakade, S.M., Kidambi, R., Netrapalli, P., Sidford, A.: Accelerating stochastic gradient descent. arXiv preprint arXiv:1704.08227 (2017)
Cyrus, S., Hu, B., Scoy, B.V., Lessard, L.: A robust accelerated optimization algorithm for strongly convex functions. In: 2018 Annual American Control Conference, ACC 2018, pp. 1376–1381 (2018)
Scoy, B.V., Freeman, R.A., Lynch, K.M.: The fastest known globally convergent first-order method for minimizing strongly convex functions. IEEE Control. Syst. Lett. 2(1), 49–54 (2018)
Kidambi, R., Netrapalli, P., Jain, P., Kakade, S.M.: On the insufficiency of existing momentum schemes for stochastic optimization. In: 6th International Conference on Learning Representations, ICLR 2018 (2018)
Robbins, H., Monro, S.: A stochastic approximation method. The annals of mathematical statistics, 400–407 (1951)
Polyak, B.T.: Some methods of speeding up the convergence of iteration methods. Ussr Computational Mathematics and Mathematical Physics 4(5), 1–17 (1964)
Qian, N.: On the momentum term in gradient descent learning algorithms. Neural Networks 12(1), 145–151 (1999)
Ruder, S.: An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747 (2016)
Zhou, B., Liu, J., Sun, W., Chen, R., Tomlin, C.J., Yuan, Y.: pbsgd: Powered stochastic gradient descent methods for accelerated non-convex optimization. In: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pp. 3258–3266 (2020)
Luo, L., Huang, W., Zeng, Q., Nie, Z., Sun, X.: Learning personalized end-to-end goal-oriented dialog. In: The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, pp. 6794–6801 (2019)
Wu, Y., He, K.: Group normalization. In: Computer Vision -ECCV 2018. Lecture Notes in Computer Science, vol. 11217, pp. 3–19 (2018)
Ma, J., Yarats, D.: Quasi-hyperbolic momentum and adam for deep learning. In: 7th International Conference on Learning Representations, ICLR 2019 (2019)
Nesterov, Y.E.: A method for solving the convex programming problem with convergence rate o (1/k2). Dokl. Akad. Nauk Sssr. 269, 543–547 (1983)
Reddi, S.J., Kale, S., Kumar, S.: On the convergence of adam and beyond. In: 6th International Conference on Learning Representations, ICLR 2018 (2018)
Bottou, L., Curtis, F.E., Nocedal, J.: Optimization methods for large-scale machine learning. SIAM Rev. 60(2), 223–311 (2018)
Pouyanfar, S., Sadiq, S., Yan, Y., Tian, H., Tao, Y., Reyes, M.E.P., Shyu, M., Chen, S., Iyengar, S.S.: A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. 51(5), 1–36 (2019)
Ben-Tal, A., Nemirovskii, A.: Lectures on Modern Convex Optimization - Analysis, Algorithms, and Engineering Applications. MPS-SIAM series on optimization, (2001)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015 (2015)
Dozat, T.: Incorporating nesterov momentum into adam. In: International Conference on Learning Representations Workshop (2016)
Zeiler, M.D.: ADADELTA: an adaptive learning rate method. CoRR (2012)
Baydin, A.G., Cornish, R., Martínez-Rubio, D., Schmidt, M., Wood, F.: Online learning rate adaptation with hypergradient descent. In: 6th International Conference on Learning Representations, ICLR 2018 (2018)
Vapnik, V.N.: Adaptive and learning systems for signal processing communications, and control. Statistical learning theory (1998)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images. In: Tech Report (2009)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M.S., Berg, A.C., Fei-Fei, L.: Imagenet large scale visual recognition challenge. IJCV 115(3), 211–252 (2015)
Wright, R.E.: Logistic regression. (1995)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: 3rd International Conference on Learning Representations, ICLR 2015 (2015)
Acknowledgements
The work is partially supported by the National Key Research and Development Program of China (2020YFB1707901), National Natural Science Foundation of China (Nos. 62072088, 61991404), Ten Thousand Talent Program (No. ZX20200035), Liaoning Distinguished Professor (No. XLYC1902057), 111 Project (B16009), and GZU-HKUST Joint Research Collaboration Grant (GZU22EG04).
Author information
Authors and Affiliations
Contributions
Weiwei Cheng and Xiaochun Yang wrote the main manuscript text and Bin Wang and Wei Wang contributed ideas, prepared Figures 1-9, and proofread the paper. All authors reviewed the manuscript. Weiwei Cheng: School of Computer Science and Engineering, Northeastern University, Shenyang, Liaoning, China. Xiaochun Yang, and Bin Wang: School of Computer Science and Engineering, Northeastern University, Shenyang, Liaoning, China; National Frontiers Science Center for Industrial Intelligence and Systems Optimization; Key Laboratory of Data Analytics and Optimization for Smart Industry (Northeastern University), Ministry of Education, China. Wei Wang: Information Hub, The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, Guangdong, China; The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong.
Corresponding author
Ethics declarations
Competing interests
The authors have no relevant financial or non-financial interests to disclose.
Ethical Approval and Consent to participate
Not applicable.
Human and Animal Ethics
Not applicable.
Consent for publication
Not applicable.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Cheng, W., Yang, X., Wang, B. et al. Unbiased quasi-hyperbolic nesterov-gradient momentum-based optimizers for accelerating convergence. World Wide Web 26, 1323–1344 (2023). https://doi.org/10.1007/s11280-022-01086-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11280-022-01086-3