
Abstract
Malware classification using machine learning algorithms is a difficult task, in part due to the absence of strong natural features in raw executable binary files. Byte n-grams previously have been used as features, but little work has been done to explain their performance or to understand what concepts are actually being learned. In contrast to other work using n-gram features, in this work we use orders of magnitude more data, and we perform feature selection during model building using Elastic-Net regularized Logistic Regression. We compute a regularization path and analyze novel multi-byte identifiers. Through this process, we discover significant previously unreported issues with byte n-gram features that cause their benefits and practicality to be overestimated. Three primary issues emerged from our work. First, we discovered a flaw in how previous corpora were created that leads to an over-estimation of classification accuracy. Second, we discovered that most of the information contained in n-grams stem from string features that could be obtained in simpler ways. Finally, we demonstrate that n-gram features promote overfitting, even with linear models and extreme regularization.








Similar content being viewed by others

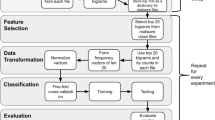
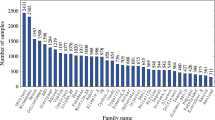
Notes
In extended testing, neither the accuracy or number of non-zeros increased when testing larger values of C.
Amusingly, we discovered one instance of malware using the non-standard “.virus” section name.
An interesting example is the MBI 0x33C9B104014C24, which we discovered is used by ClamAV as a signature (see https://github.com/eqmcc/clamav_decode/blob/master/db/daily.ndb#L363).
We did not perform an exhaustive test for consistency; this was merely a property found when testing some simple hypotheses. The true number could be much higher.
References
Abou-Assaleh, T., Cercone, N., Keselj, V., Sweidan, R.: N-gram-based detection of new malicious code. In: Proceedings of 28th annual int’l computer software & applications conference, vol. 2, pp. 41–42. IEEE (2004)
Aggarwal, C.C., Hinneburg, A., Keim, D.A.: On the Surprising Behavior of Distance Metrics in High Dimensional Spaces. In: van den Bussche, J., Vianu, V. (eds.) Proceedings of 8th international conference on database theory, pp. 420–434. Springer-Verlag (2001)
Banko, M., Brill, E.: Scaling to Very Very Large Corpora for Natural Language Disambiguation. In: Proceedings of the 39th annual meeting on association for computational linguistics, pp. 26–33 (2001)
Bellman, R.: Dynamic Programming. Princeton University Press, Princeton (1957)
Corelan Team. Exploit writing tutorial, part 11: heap spraying demystified (2011). https://www.corelan.be/index.php/2011/12/31/exploit-writing-tutorialpart-11-heap-spraying-demystified/ (visited on 05/25/2016)
Domingos, P.: A few useful things to know about machine learning. Commun. ACM 55(10), 78–87 (2012). (issn: 0001-0782)
Elovici, Y., Shabtai, A., Moskovitch, R., Tahan, G., Glezer, C.: Applying Machine Learning Techniques for Detection of Malicious Code in Network Traffic. In: Proceedings of the 30th annual German conference on advances in artificial intelligence. In: KI ’07, pp. 44–50. Springer-Verlag, Berlin, Heidelberg. isbn: 978- 3-540-74564-8 (2007)
Freund, Y., Schapire, R.: Experiments with a new boosting algorithm. In: Saitta, L. (ed.) Proceedings of the thirteenth international conference on machine learning (ICML 1996), pp. 148–156. Morgan Kaufmann (1996)
Friedman, J., Hastie, T., Tibshirani, R.: Regularization paths for generalized linear models via coordinate descent. J. Stat Softw. 33(1), 1–22 (2010)
Gong, P., Ye, J.: A modified orthant-wise limited memory quasi-Newton method with convergence analysis. In: Proceedings of 32nd international conference on machine learning, vol. 37, pp. 276–284 (2015)
Griffin, K., Schneider, S., Hu, X., Chiueh, T.-C.: Automatic generation of string signatures for malware detection. In: Lippmann, R., Clark, A. (eds.) Recent Advances in Intrusion Detection, RAID ’09 Proceedings of the 12th International Symposium on Recent Advances in Intrusion Detection, pp. 101–120 (2009)
Halevy, A., Norvig, P., Pereira, F.: The unreasonable effectiveness of data. Intell. Syst. IEEE 24(2), 8–12 (2009)
Henchiri, O., Japkowicz, N.: A Feature Selection and Evaluation Scheme for Computer Virus Detection. In: Proceedings of the 6th international conference on data mining. IEEE Computer Society, pp. 891–895. isbn: 0-7695-2701-9 (2006)
Ibrahim, A.H., Abdelhalim, M.B., Hussein, H., Fahmy, A.: Analysis of x86 instruction set usage for Windows 7 applications. In: 2nd international conference on computer technology & development, pp. 511–516 (2010)
Jain, S., Meena, Y.K.: Byte level n-gram analysis for malware detection. In: Venugopal, K.R., Patnaik, L.M. (eds.) Computer Networks and Intelligent Computing, pp. 51–59. Springer, Berlin Heidelberg (2011)
Kephart, J.O., Sorkin, G.B., Arnold, W.C., Chess, D.M., Tesauro, G.J., White, S.R.: Biologically Inspired Defenses Against Computer Viruses. In: Proceedings of the 14th international joint conference on artificial intelligence, vol. 1, pp. 985–996. Morgan Kaufmann (1995). (isbn: 1-55860-363-8)
Kolter, J.Z., Maloof, M.A.: Learning to detect and classify malicious executables in the wild. J. Mach. Learn. Res. 7, 2721–2744 (2006)
Kolter, J.Z., Maloof, M.A.: Learning to detect malicious executablesin the wild. In: Proceedings of the 2004 ACM SIGKDD international conference on knowledge discovery and data mining, pp. 470–478. ACM Press (2004)
Lo, R.W., Levitt, K.N., Olsson, R.A.: Refereed paper: MCF: a malicious code filter. Comput. Secur. 14(6), 541–566 (1995). issn: 0167-4048
Lyda, R., Hamrock, J.: Using entropy analysis to find encrypted and packed malware. IEEE Secur. Priv. Mag. 5(2), 40–45 (2007)
Masud, M.M., Khan, L., Thuraisingham, B.: A scalable multi-level feature extraction technique to detect malicious executables. Inf. Syst. Front. 10(1), 33–45 (2008)
Masud, M.M., Al-Khateeb, T.M., Hamlen, K.W., Gao, J., Khan, L., Han, J., Thuraisingham, B.: Cloudbased malware detection for evolving data streams. ACM Trans. Manag. Inf. Syst. 2(3), 1–27 (2011)
Menahem, E., Shabtai, A., Rokach, L., Elovici, Y.: Improving malware detection by applying multi-inducer ensemble. Comput. Stat. Fata Anal. 53(4), 1483–1494 (2009). issn: 0167-9473
Microsoft Portable Executable and Common Object File Format Specification Version 8.3. Tech. rep. Microsoft, p. 98 (2013)
Moskovitch, R., Stopel, D., Feher, C., Nissim, N., Japkowicz, N., Elovici, Y.: Unknown malcode detection and the imbalance problem. J. Comput. Virol. 5(4), 295–308 (2009)
Ng, A.Y.: Feature selection, \(L_{1}\) vs. \(L_{2}\) regularization, and rotational invariance. In: Proceedings of 21st international conference on machine learning, pp. 78–86 (2004)
Perdisci, R., Lanzi, A., Lee, W.: McBoost: boosting scalability in malware collection and analysis using statistical classification of executables. In: Annual computer security applications conference (ACSAC), pp. 301–310. IEEE (2008)
Quinlan, J.R.: C4.5: programs for machine learning. Vol. 1(3) of Morgan Kaufmann series in Machine Learning. Morgan Kaufmann (1993). isbn: 1558602380
Quist, D.: Open malware. http://openmalware.org/ (visited on 05/25/2016)
Reddy, D.K.S., Pujari, A.K.: N-gram analysis for computer virus detection. J. Comput. Virol. 2(3), 231–239 (2006)
Roberts, J.-M.: Virus share. https://virusshare.com/ (visited on 05/25/2016)
Santos, I., Penya, Y.K., Devesa, J., Bringas, P.G.: N-grams-based file signatures for malware detection. In: Proceedings of 11th international conference on enterprise information systems, pp. 317–320 (2009)
Schultz, M., Eskin, E., Zadok, F., Stolfo, S.: Data mining methods for detection of new malicious executables. In: Proceedings of IEEE symposium on security and privacy, pp. 38–49 (2001)
Shabtai, A., Moskovitch, R., Elovici, Y., Glezer, C.: Detection of malicious code by applying machine learning classifiers on static features: a state-of-the-art survey. Inf. Secur. Tech. Rep. 14(1), 16–29 (2009). issn: 1363-4127
Shafiq, M.Z., Tabish, S.M., Mirza, F., Farooq, M.: PE-Miner: mining structural information to detect malicious executables in realtime. In: Lippmann, R., Clark, A. (eds.) Recent Advances in Intrusion Detection, Springer, Berlin Heidelberg, pp. 121–141 (2009)
Stolfo, S.J., Wang, K., Li, W.-J.: Towards stealthy malware detection. In: Christodorescu, M., Jha, S., Maughan, D., Song, D., Wang, C. (eds.) Malware Detection, pp. 231–249. Springer, Berlin Heidelberg (2007). isbn: 978-0-387-44599-1
Tahan, G., Rokach, L., Shahar, Y.: Mal-ID: automatic malware detection using common segment analysis and meta-features. J. Mach. Learn. Res. 13, 949–979 (2012). issn: 1532-4435
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc. B 58(1), 267–288 (1994)
Verleysen, M., François, D.: The Curse of Dimensionality in Data Mining and Time Series Prediction. In: Cabestany, J., Prieto, A., Sandoval, F. (eds.) Proceedings of 8th international conference on artificial neural networks: computational intelligence and bioinspired systems, pp. 758–770 (2005)
Yuan, G.-X., Chang, K.-W., Hsieh, C.-J., Lin, C.-J.: A comparison of optimization methods and software for large-scale \(L_{1}\)-regularized linear classification. J. Mach. Learn. Res. 11, 3183–3234 (2010)
Yuan, G.-X., Ho, C.-H., Lin, C.-J.: An improved GLMNET for \(L_{1}\)-regularized logistic regression. J. Mach. Learn. Res. 13, 1999–2030 (2012)
Zhang, B., Yin, J., Hao, J., Zhang, D., Wang, S.: Malicious codes detection based on ensemble learning. In: Proceedings of the 4th international conference on autonomic and trusted computing, pp. 468–477. Springer-Verlag (2007). isbn: 3-540-73546-1
Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. R. Stat. Soc. B 67(2), 301–320 (2005)
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Group B data labels
Since the Group B data is not publicly available, we attempt to provide extra details about the contents for readers who are interested. The results of the n-gram analysis convince us that the resulting model has more utility than one constructed from Group A style data, as many prior works have done. One may wonder then how much of the generalization gap incurred by the Group B model is due to differences in the data distribution, rather than the weaknesses of byte n-grams, or potential label errors. Fully answering such a question is beyond the scope of this work, however we hope the additional details may be of use to the reader to better understand the results as a whole and dissuade any concern of label quality.
To obtain a rough estimate of label errors we ran all Group B data (goodware and malware) through ClamAV.Footnote 5 We chose ClamAV because it is freely available to everyone and usable on all operating systems. If the labels are correct, we expect to see that most goodware is not flagged by ClamAV and that most malware is. Because ClamAV is not the most advanced of anti-virus (AV) products, we upload a random sample of 50 files in which ClamAV’s output disagreed with our labels to Virus TotalFootnote 6 for further confirmation. Virus Total uses an ensemble of anti-virus systems to asses each sample it is given. This produces more reliable labels, as well as giving us a proxy for confidence in those labels: a file which is identified as malicious by 20 of Virus Total’s constituent programs is more likely to be malignant than one identified by only a single anti-virus program. While it would have been preferable to upload all of our data to Virus Total, a rate limit on the API means it would take multiple months to process the entire corpus. The results of this examination can be seen in Table 6. The first line shows the percentage of files marked as malware by ClamAV, and the remaining lines are the statistics of potentially mislabeled data sent to Virus Total.
We can see for the goodware Group B data, ClamAV marks almost all files as benign, with the test dataset having a higher conflict of 1.4 % of the data. Even if all of such data was in fact mislabeled malware, the percentage would be small enough that a robust machine learning system should be able to learn from it. From the sample sent to Virus Total, we can see that most files had no or only a handful of anti-virus systems flag the files, giving us confidence that ClamAV was throwing false positives on the goodware data it identified as malicious. We note as well that anti-virus products may, in general, throw false positives for more challenging benign samples. A benign application with more sophisticated code (e.g, for performing encryption, just-in-time compilation, or disk formatting) may seem malicious to an AV product for good reason, despite having no malicious purpose as an application. We have observed that a number of the Group B test goodware files, marked by multiple AVs, are products for encryption that do not have a clear malicious intent. We avoid explicitly naming these products due to privacy concerns.
While the Group B goodware samples sent to Virus Total are more anomalous compared to those from the training set, we are still confident in the majority of the labels since we obtained. If we assume that all samples marked by 6 or more AVs is in fact malware, then Group B’s test set goodware would contain only 0.9 % mislabeled files. The maximal change in test accuracy is thus less than one percentage point, and then would not meaningfully impact any of the results or conclusions of our work.
For the malware datasets, ClamAV fails to recognize a much higher percentage as malicious: around 19 % of files for Group B and 33 % for Group A. When uploading samples that were not caught by ClamAV, every sample was marked by at least one anti-virus. Most were marked by a plethora of products (26 or more), with only a handful being marked by less than 10. This again gives us confidence that our labels are correct, and that ClamAV is throwing false negatives.
As mentioned in our conclusion, the construction and evaluation of a high quality dataset for this task is still an open problem. We believe we have provided ample evidence that our Group B data is of a better quality than the datasets normally used (i.e., Group A type data), but there is room for improvement in validating and constructing yet larger corpora for this task.
We also look at the labels ClamAV produces for the files it does recognize as malignant in the malware data. These are shown in Table 7. We caution that the labels should not be taken as an absolute ground truth; ClamAV did not recognize a significant percentage of each dataset as malware, and anti-virus products in general do not always agree on the type of, or label for, an individual datum. It is also important to note that some of the labels are quite unexpected, indicating JavaScript, PDF, and HTML malware. We reiterate that all files in all of our datasets are valid PE files. These labels are either faulty in their designation, or an indication of our executables containing malware of a considerably different nature would be anticipated.
Looking at the Group A and B data separately, and comparing within group train and test sets, we see fairly consistent patterns. Looking across groups, we do see some distributional similarities and differences. Both Groups A and B are comprised mostly of Trojans, and do contain a significant amount of Adware. In Group B, Adware is a close second for the malware type, where Droppers make a far second for Group A. Group A seems to have, in general, a wider array of malware types. It is possible that the differences in distribution account for some portion of the decrease in generalization when applying a model trained on Group B to data from Group A. At the same time, it is also important for a model to generalize to novel data, which in this case includes malware of a type never seen before.
Appendix B: String features
We include a few examples of the string features found. We place these in the appendix as they have not yet been fully analyzed or understood for their meaning. Some were very long, and despite occurring many times in our training data are thus unlikely to occur in new novel malware. For example, the string “Cl8lgpHNMmFBrO1rzHOloWOdjXN98PMI9ink JeYt8SxmqihhSpfFj7VOP5e{BYbBZHRNwyPknt93{P3mPu CYDO6G{ewBlbc9gLOQ” occurred 175,725 times in 780 files from the Group B training malware. A number of strings were simply the full function or DLL import names that n-grams were trying to extract, such as KERNEL32.dll, Sleep, ExitProcess, and MultiByteToWideChar. We also see many strings at least claiming that the malware is appropriately signed, like 1(c) 2006 VeriSign, Inc. - For authorized use only1E0C. There are a number of variations of different strings like this, where it may have been better to select VeriSign as our feature rather than the larger strings. N-grams implicitly do select this smaller component rather than the text that happens to be around it.
There are also simpler cases of the sub-string issue. One example is the http://crl.comodoca.com/COMODOCodeSigningCA2.crl0r, which is found with several different one-character differences appended to this base URL. Another important note is that we see many full URLs in the string data, and a better solution would detect and process URLs differently. There are also instances where the differences are a simple pattern of replacement, such as protocol_not_supported versus protocol not supported. There are also many patterns where processing and removing repetition would collapse many complicated strings into one or a few base strings. For example a sequence of commas like “,,,,” occurs many times with differing amounts of repetition.

3-fold CV and test set accuracy using string features. Trained using Elastic-Net regularization from group A data

3-fold CV and test set accuracy using string features. Trained using Elastic-Net regularization from group B data
1.1 Appendix B.1: Extra string graphs
The plots using string features (Figs. 7 and 8) were relatively similar when using Elastic-Net or \(L_1\) regularization. Figures 9 and 10 show the same plots for Elastic-Net for comparison. Also included is the average number of non-zeros added to the solution as C increased (Fig. 11).

Average number of non-zero weights in solution vector based on 3-fold cross validation across regularization path. Feature space is string occurrences
Appendix C: N-gram ASCII decodings
Below we list some of the n-grams selected by models early in the regularization path. The features selected earliest in the path are those that the model found most predictive of the 200k starting set. For legibility, we remove some n-grams from some of the larger tables. The n-grams removed either had no ASCII printable tokens, or had the same ASCII printout when decoded as another n-gram. In this case, the n-grams generally differed in being shifted over one byte by the value 0x00. We depict whitespace characters using the ‘␣’ symbol. Only two tables for 4-gram models are included since they are more difficult to read and interpret (Tables 8, 9, 10, 11, 12, 13, 14).
Rights and permissions
About this article

Cite this article
Raff, E., Zak, R., Cox, R. et al. An investigation of byte n-gram features for malware classification. J Comput Virol Hack Tech 14, 1–20 (2018). https://doi.org/10.1007/s11416-016-0283-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11416-016-0283-1