
Abstract
Affine transform is widely used in the high speed image processing systems. This transform plays an important role in various high speed applications like Optical quadrature microscopy (OQM), image stabilisation in digital camera and image registration etc. In these applications, transformations of image consume most of the execution time. Hence, for high speed imaging systems, acceleration of Affine transform is very much sought for. In this paper, the pipelined architecture implementation of a proposed inherent parallel algorithm for Affine transform has been presented. The acceleration of the image transformation will help in reducing the processing time of high speed imaging systems. The architecture is mapped in Field programmable gate array (FPGA) and the result shows that the proposed algorithm is almost 4 times faster than the conventional algorithm while retaining the image quality. Using the proposed algorithm, an image of size 1,920 × 1,080 can be transformed with a frame rate of 540 frames per second and the multiplane image synthesis for image stabilisation on the same digital image can be performed with a frame rate of 65 fps.












Similar content being viewed by others


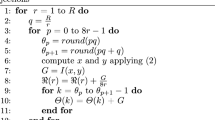
References
Badawy, W., Bayoumi, M.: A multiplication-free algorithm and a parellel architecture for affine transformation. J VLSI Signal Process 31, 173–184 (2002)
Bentum, M., Samsom, M., Slump, C.: A multi-ASIC real-time implementation of the two dimensional affine transform with a bilinear interpolation scheme. J VLSI Signal Process 10, 261–273 (1995)
Bhandakar, S., Yu, H.: VLSI implementation of real-time image rotation. In: Proceedings of International Conference on Image Processing, vol. 2, pp. 1015–1018 (1996)
Biswal, PK., Banerjee, S.: An embedded solution of 2D fast affine transform for biomedical imaging systems. In: Proceddings of VLSI Design and Test Symposium (VDAT 2009), Bangalore, India, pp. 259–270 (2009)
Biswas, G., Dutta, P., Krishna, P., Sengupta, I.: Cellular architecture for affine transforms on raster images. IEE Proc Comput Digi Tech 143(2), 103–110 (1996)
Crookes, D., Boyle, K., Miller, P., Gillan, C.: GPU implementation of the affine transform for 3D image registration. 13th International Conference on Machine Vision and Image Processing (2009)
Das, A., Hazra, A., Banerjee, S.: An efficient architecture for 3-D discrete wavelet transform. IEEE Trans Circ Syst Video Technol 20(2), 286–296 (2010)
Eadie, D., Shevlin, F., Nisbet, A.: Correction of geometric image distortion using FPGAs. SPIE Conference on Optical Metrology, Imaging, and Machine Vision, Galway, IRL (2002)
Fraser, D.: Comparison at high spatial frequencies of two-pass and one-pass geometric transformation algorithms. Comput Vision Graph Image Process 46, 267–283 (1989)
Ghosh, I., Majumdar, B.: VLSI implementation of an efficient ASIC architecture for real time rotation of digital images. Int J Pattern Recognition Artif Intell 9, 449–462 (1995)
Gonzalez, R.C., Woods, R.E.: Digital Image Processing, 3rd edn. Prentice Hall, Upper Saddle River (2008)
Iakovidou, C., Vonikakis, V., Andreadis, I.: FPGA implementation of a real-time biologically inspired image enhancement algorithm. J Real-Time Image Process 3, 269–287 (2008)
Jiang, XG., Zhou, JY., Shi, JH., Chen, HH.: FPGA implementation of image rotation using modified compensated CORDIC. In: 6th International Conference On ASIC (ASICON 2005), vol. 2, pp. 752–756 (2005)
Lacassagne, L., Manzanera, A., Denoulet, J., Merigot, A.: High performance motion detection: some trends toward new embedded architectures for vision systems. J Real-Time Image Process 4, 127–146 (2009)
Lee, S., Lee, G., Jang, ES., Kim, WY.: Fast affine transform for real-time machine vision applications. In: ICIC 2006, Springer, Berlin, Lecture Notes in Computer Science 4113, pp. 1180–1190 (2006)
Lindoso, A., Entrena, L.: High performance FPGA-based image correlation. J Real-Time Image Process 2, 223–233 (2007)
Maharatna, K., Banerjee, S.: CORDIC based array architecture for affine transformation of images. In: International Conference on Communications, Computers and Devices (2000)
Mistry, P., Braganza, S., Kaeli, D., Leeser, M.: Accelerating phase unwrapping and affine transformations for optical quadrature microscopy using CUDA. In: Proceedings of 2nd Workshop on General Purpose Processing on Graphics Processing Units, ACM, New York, NY, USA, GPGPU-2, pp. 28–37 (2009)
Pailoor, R., Bartusek, J.: Implementation of affine warp using TI DSP. Application Report, Texas Instruments (2010)
Sarawadekar, K., Banerjee, S.: An efficient pass-parallel architecture for embedded block coder in JPEG 2000. IEEE Trans Circ Syst Video Technol 21(6), 825–836 (2011)
Shams, R., Sadeghi, P., Kennedy, R., Hartley, R.: A survey of medical image registration on multicore and the GPU. IEEE Signal Process Mag 27(2), 50–60 (2010)
Sony (2010) Development of an imaging system that creates a high-speed imaging world. http://www.sony.net/Products/SC-HP/cx_news/vol55/pdf/ featuring55, accessed on December, 2010
Suchitra, S., Lam, S., Clarke, C., Srikanthan, T.: Accelerating rotation of high-resolution images. IEE Proc Vision Image Signal Process 153(6), 815–824 (2006)
Tsuchida, N., Yamada, Y., Ueda, M.: Hardware for image rotation by twice skew transformations. IEEE Trans Acoustics Speech Signal Process 35(4), 527–532 (1987)
Unser, M., Thevenaz, P., Yaroslavsky, L.: Convolution based interpolation for fast, high quality rotation of images. IEEE Trans Image Process 10(4), 1371–1381 (1995)
Acknowledgments
The authors would like to thank Ministry of HRD, Govt. of India, for supporting this research work.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Biswal, P.K., Mondal, P. & Banerjee, S. Parallel architecture for accelerating affine transform in high-speed imaging systems. J Real-Time Image Proc 8, 69–79 (2013). https://doi.org/10.1007/s11554-011-0233-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11554-011-0233-6