
Abstract
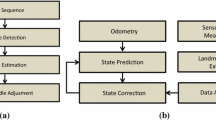
We present a new approach that combines spoken language and visual object detection to produce a depth image to perform metric monocular SLAM in real time and without requiring a depth or stereo camera. We propose a methodology where a compact matrix representation of the language and objects, along with a partitioning algorithm, is used to resolve the association between the objects mentioned in the spoken description and the objects visually detected in the image. The spoken language is processed online using Whisper, a popular automatic speech recognition system, while the YOLOv8 network is used for object detection. Camera pose estimation and mapping of the scene are performed using ORB-SLAM. The full system runs in real time, allowing a user to explore the scene with a handheld camera, observe the objects detected by YOLOv8, and provide depth information of these objects with respect to the camera via a spoken description. We have performed experiments in indoor and outdoor scenarios, comparing the resulting camera trajectory and map obtained with our approach against that obtained when using RGB-D images. Our results are comparable to those obtained with the latter without losing real-time performance.




Similar content being viewed by others


Notes
The “singularise()” method from words-inflection in TextBlob was used. https://textblob.readthedocs.io/en/dev/quickstart.html#words-inflection-and-lemmatization.
The POS tagger from NLTK was used. https://www.nltk.org/book/ch05.html.
References
2086341682@qq.com: coco128 dataset. (2021).https://universe.roboflow.com/2086341682-qq-com/coco128-xilzt Visited on 2023-03-15
Anderson P, Wu Q, Teney D, Bruce J, Johnson M, Sünderhauf N, Reid ID, Gould S, van den Hengel A (2017) Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. CoRR arXiv:abs/1711.07280. Accessed 15 Mar 2023
Arun, K.S., Huang, T.S., Blostein, S.D.: Least-squares fitting of two 3-d point sets. IEEE Trans. Pattern Anal. Mach. Intell. 5, 698–700 (1987)
Auty D, Mikolajczyk K (2022) ObjCAViT: Improving Monocular Depth Estimation Using Natural Language Models And Image-Object Cross-Attention. 10.48550/ARXIV.2211.17232. arXiv:2211.17232. Accessed 15 Mar 2023
Chan W, Park D, Lee C, Zhang Y, Le Q (2021) Norouzi, M.: Speechstew: Simply mix all available speech recognition data to train one large neural network. arXiv preprint arXiv:2104.02133. Accessed 15 Mar 2023
Davison, A.J., Reid, I.D., Molton, N.D., Stasse, O.: MonoSLAM: real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 29(6), 1052–1067 (2007)
Driess D, Xia F, Sajjadi MSM, Lynch C, Chowdhery A, Ichter B, Wahid A, Tompson J, Vuong Q, Yu T, Huang W, Chebotar Y, Sermanet P, Duckworth D, Levine S, Vanhoucke V, Hausman K, Toussaint M, Greff K, Zeng A, Mordatch I, Florence P (2023) PaLM-E: An Embodied Multimodal Language Model. In: arXiv preprint arXiv:2303.03378. Accessed 15 Mar 2023
Gadre SY, Wortsman M, Ilharco G, Schmidt L, Song S (2022) CLIP on Wheels: Zero-Shot Object Navigation as Object Localization and Exploration. arXiv:abs/2203.10421. Accessed 15 Mar 2023
Gu J, Stefani E, Wu Q, Thomason J, Wang X (2022) Vision-and-language navigation: A survey of tasks, methods, and future directions. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 7606–7623. Association for Computational Linguistics, Dublin, Ireland. https://doi.org/10.18653/v1/2022.acl-long.524. https://aclanthology.org/2022.acl-long.524. Accessed 15 Mar 2023
Huang C, Mees O, Zeng A, Burgard W (2022) Visual language maps for robot navigation. arXiv preprint arXiv:2210.05714. Accessed 15 Mar 2023
Jia C, Yang Y, Xia Y, Chen Y, Parekh Z, Pham H, Le QV, Sung Y, Li Z, Duerig T (2021) Scaling up visual and vision-language representation learning with noisy text supervision. CoRR arXiv:abs/2102.05918
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common Objects in COntext. In: Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, New York (2014)
Loianno, G., Brunner, C., McGrath, G., Kumar, V.: Estimation, control, and planning for aggressive flight with a small quadrotor with a single camera and IMU. IEEE Robot Autom Lett 2(2), 404–411 (2016)
McGuire, K., De Wagter, C., Tuyls, K., Kappen, H., de Croon, G.C.: Minimal navigation solution for a swarm of tiny flying robots to explore an unknown environment. Sci. Robot. 4(35), eaaw9710 (2019)
Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: ORB-SLAM: a versatile and accurate monocular SLAM system. IEEE Trans. Rob. 31(5), 1147–1163 (2015)
Park, S., Bokijonov, S., Choi, Y.: Review of microsoft hololens applications over the past five years. Appl. Sci. 11(16), 7259 (2021)
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, Krueger G, Sutskever I (2021) Learning Transferable Visual Models From Natural Language Supervision. In: Meila, M., Zhang, T.: (eds.) Proceedings of the 38th International Conference on Machine Learning, Proceedings of Machine Learning Research. PMLR. 139: 8748–8763.
Rascon, C., Meza, I.: Localization of sound sources in robotics: a review. Robot. Auton. Syst. 96, 184–210 (2017)
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 779–788
Ultralytics: YOLOv8 object detection. https://ultralytics.com/yolov8 (2021). Accessed 14 Mar 2023
Zhang R, Zeng Z, Guo Z, Li Y (2022) Can language understand depth? In: Proceedings of the 30th ACM International Conference on Multimedia MM ’22. Association for Computing Machinery, New York. pp 6868-6874
Acknowledgements
L. Oyuki Rojas-Perez and Aldrich Ca-brera-Ponce are thankful to Consejo Nacional de Ciencia y Tecnologia (CONACYT) for their scholarship No. 924254 and No 802791, respectively. We also thank Haydee Michelle Cortez-Coyotl for her assistance during the experiments.
Author information
Authors and Affiliations
Contributions
JMC: idea conceptualization, implementation, and writing. DIHF: implementation and writing. LORP: implementation, writing and figure design, and preparation. AACP: implementation. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Martinez-Carranza, J., Hernández-Farías, D.I., Rojas-Perez, L.O. et al. Language meets YOLOv8 for metric monocular SLAM. J Real-Time Image Proc 20, 59 (2023). https://doi.org/10.1007/s11554-023-01318-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11554-023-01318-3