
Abstract
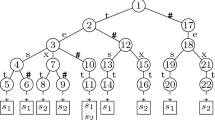
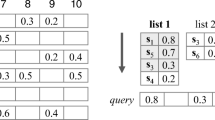
Set queries are an important topic and have attracted a lot of attention. Earlier research mainly concentrated on set containment queries. In this paper we focus on the T-Overlap query which is the foundation of the set similarity query. To address this issue, unlike traditional algorithms that are based on an inverted index, we design a new paradigm based on the prefix tree (trie) called the expanded trie index (ETI) which expands the trie node structure by adding some new properties. Based on ETI, we convert the TOverlap problem to finding query nodes with specific query depth equaling to T and propose a new algorithm called TSimilarity to solve T-Overlap efficiently. Then we carry out a three-step framework to extend T-Overlap to other similarity predicates. Extensive experiments are carried out to compare T-Similarity with other inverted index based algorithms from cardinality of query, overlap threshold, dataset size, the number of distinct elements and so on. Results show that T-Similarity outperforms the state-of-the-art algorithms in many aspects.
Similar content being viewed by others

References
Helmer S, Moerkotte G. A performance study of four index structures for set-valued attributes of low cardinality. The VLDB Journal, 2003, 12(3): 244–261
Helmer S. Index structures for databases containing data items with set-valued attributes. Technical Report 2/97, University at Mannheim, http://pi3.informatik.uni-mannheim.de
Helmer S, Aly R, Neumann T, Moerkotte G. Indexing set-valued attributes with a multi-level extendible hashing scheme. In: Proceedings of DEXA. 2007, 98-108
Agrawal P, Arasu A, Kaushik R. On indexing error-tolerant set containment. In: Proceedings of SIGMOD Conference. 2010, 927-938
Morzy M, Morzy T, Nanopoulos A, Manolopoulos Y. Hierarchical bitmap index: an efficient and scalable indexing technique for setvalued attributes. In: Proceedings of ADBIS. 2003, 236–252
Terrovitis M, Passas S, Vassiliadis P, Sellis T K. A combination of trietrees and inverted files for the indexing of set-valued attributes. In: Proceedings of CIKM. 2006, 728–737
Hossain S, Jamil H M. A hybrid index structure for set-valued attributes using item set tree and inverted list. In: Proceedings of DEXA. 2010, 349–357
Arasu A, Ganti V, Kaushik R. Efficient exact set-similarity joins. In: Proceedings of VLDB. 2006, 918–929
Chaudhuri S, Ganti V, Kaushik R. A primitive operator for similarity joins in data cleaning. In: Proceedings of ICDE. 2006
Xiao C, Wang W, Lin X, Yu J X, Wang G. Efficient similarity joins for near duplicate detection. ACM Transactions on Database Systems (TODS), 2008, 36(3): 15
Hoad T C, Zobel J. Methods for identifying versioned and plagiarized documents. Journal of the American Society for Information Science and Technology, 2003, 54(3): 203–215
Bayardo R J, Ma Y, Srikant R. Scaling up all pairs similarity search. In: Proceedings of the 16th International Conference on World Wide Web. 2007, 131–140
Ribeiro L, Härder T. Efficient set similarity joins using min-prefixes. In: Proceedings of ADBIS. 2009, 88–102
Li C, Lu J, Lu Y. Efficient merging and filtering algorithms for approximate string searches. In: Proceedings of ICDE. 2008, 257–266
Han J, Pei J, Yin Y, Mao R. Mining frequent patterns without candidate generation: a frequent-pattern tree approach. Data Mining and Knowledge Discovery, 2004, 8(1): 53–87
Agrawal R, Imielinski T, Swami A N. Mining association rules between sets of items in large databases. In: Proceedings of SIGMOD Conference. 1993, 207-216
Wang J N, Feng J H, Li G L. Trie-join: efficient trie-based string similarity joins with edit distance constraints. Proceedings of the VLDB Endowment, 2010, 3(1–2): 1219–1230
Sarawagi S, Kirpal A. Efficient set joins on similarity predicates. In: Proceedings of SIGMOD Conference. 2004, 743–754
Bay S D, Kibler D, Pazzani M J, Smyth P. The UCI KDD archive of large data sets for data mining research and experimentation. ACM SIGKDD Explorations Newsletter, 2000, 2(2): 81–85
Author information
Authors and Affiliations
Additional information
Lianyin Jia is currently a PhD student in the School of Computer Science and Engineering at the South China University of Technology and is also a lecturer of the Yunnan Agricultural University. His research activities cover databases, data mining, parallel computing, and web services.
Jianqing Xi is a professor of Computer Science and Engineering at the South China University of Technology. His current research interests include databases and data warehouses, P2P distributed systems, software development techniques.
Mengjuan Li is a librarian at Yunnan Normal University. She obtained her master degree in technology of computer apllications in 2008 from Kunming University of Science and Technology. Her research interests focus on databases, information retrieval, and parallel computing.
Yong Liu is currently a PhD candidate in the School of Computer Science and Engineering, South China University of Technology and is a lecturer at Guangxi University for Nationalities. His current research interests include databases and GPU based parallel computing.
Decheng Miao is currently a PhD candidate in the School of Computer Science and Engineering, South China University of Technology. He is a lecturer in the School of Mathematics and Information Science, Shaoguan University. His current research interests include software system formal theory, formal semantics, databases, and network computing.
Rights and permissions
About this article
Cite this article
Jia, L., Xi, J., Li, M. et al. ETI: an efficient index for set similarity queries. Front. Comput. Sci. 6, 700–712 (2012). https://doi.org/10.1007/s11704-012-1237-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11704-012-1237-5