
Abstract
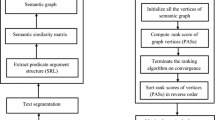
Graph model has been widely applied in document summarization by using sentence as the graph node, and the similarity between sentences as the edge. In this paper, a novel graph model for document summarization is presented, that not only sentences relevance but also phrases relevance information included in sentences are utilized. In a word, we construct a phrase-sentence two-layer graph structure model (PSG) to summarize document(s). We use this model for generic document summarization and query-focused summarization. The experimental results show that our model greatly outperforms existing work.
Similar content being viewed by others

Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.References
Wan X, Yang J. Multi-document summarization using cluster-based link analysis. In: Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Informal Retrieval. 2008, 299–306
Erkan G, Radev D. Lexrank: graph-based lexical centrality as salience in text summarization. Journal of Artificial Intelligence Research, 2004, 22: 457–479
Wan X, Yang J. Collabsum: exploiting multiple document clustering for collaborative single document summarizations. In: Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Informal Retrieval. 2007, 143–150
Radev D, Jing H, Stys M, Tam D. Centroid-based summarization of multiple documents. Information Processing and Management, 2004, 40(6): 919–938
Mihalcea R. Graph-based ranking algorithms for sentence extraction, applied to text summarization. In: Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions. 2004, 20:1–20:4
Otterbacher J, Erkan G, Radev D. Using random walks for question-focused sentence retrieval. In: Proceedings of the 2005 Conference on Human Language Technology and Empirical Methods in Natural Language Processing. 2005, 915–922
Zhao L, Wu L, Huang X. Using query expansion in graph-based approach for query-focused multi-document summarization. Information Processing and Management, 2009, 45(1): 35–41
Wan X, Yang J, Xiao J. Manifold-ranking based topic-focused multidocument summarization. In: Proceedings of the 20th International Joint Conference on Artifical Intelligence. 2007, 2903–2908
Daumé III H, Marcu D. Bayesian query-focused summarization. In: Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. 2006, 305–312
Ramanathan K, Sankarasubramaniam Y, Mathur N, Gupta A. Document summarization using wikipedia. In: Proceedings of the 1st International Conference on Intelligent Human Computer Interaction. 2009, 254–260
Kumar N, Srinathan K, Varma V. Using wikipedia anchor text and weighted clustering coefficient to enhance the traditional multidocument summarization. Computational Linguistics and Intelligent Text Processing, 2012, 7182: 390–401
Nastase V. Topic-driven multi-document summarization with encyclopedic knowledge and spreading activation. In: Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. 2008, 763–772
Erkan G, Radev D. Lexpagerank: prestige in multi-document text summarization. In: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing Chairs. 2004, 365–371
Li L, Shang Y, Zhang W. Improvement of hits-based algorithms on web documents. In: Proceedings of the 11th International Conference on World Wide Web. 2002, 527–535
Radev D, Allison T, Blair-Goldensohn S, Blitzer J. MEAD-a platform for multidocument multilingual text summarization. In: Proceedings of the 4th International Conference on Language Resources and Evaluation. 2004, 699–702
Abu-Jbara A, Radev D. Coherent citation-based summarization of scientific papers. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. 2011, 500–509
Mihalcea R. Language independent extractive summarization. In: Proceedings of the ACL 2005 on Interactive Poster and Demonstration Sessions. 2005, 49–52
Cai X, Li W, Ouyang Y, Yan H. Simultaneous ranking and clustering of sentences: a reinforcement approach to multi-document summarization. In: Proceedings of the 23rd International Conference on Computational Linguistics. 2010, 134–142
Feng J, He X, Konte B, Böhm C, Plant C. Summarization-based mining bipartite graphs. In: Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2012, 1249–1257
Alguliev R M, Aliguliyev R M, Isazade N R. CDDS: constraint-driven document summarization models. Expert Systems with Applications, 2013, 40(2): 458–465
Mukherjee S, Bhattacharyya P. Wikisent: weakly supervised sentiment analysis through extractive summarization with wikipedia. In: Proceedings of the 2012 European Conference on Machine Learning and Knowledge Discovery in Databases. 2012, 774–793
Pourvali M, Abadeh M S. Automated text summarization base on lexicales chain and graph using of wordnet and wikipedia knowledge base. International Journal of Computer Science Issues, 2012, 9(3): 343–349
Wan X. Document-based hits model for multi-document summarization. Lecture Notes in Computer Science, 2008, 5351: 454–465
Zhang Z, Ge S S, He H. Mutual-reinforcement document summarization using embedded graph based sentence clustering for storytelling. Information Processing and Management, 2012, 48(4): 767–778
Alguliev R M, Aliguliyev R M, Isazade N R. Multiple documents summarization based on evolutionary optimization algorithm. Expert Systems with Applications, 2013, 40(5): 1675–1689
Kumar N, Srinathan K. Automatic keyphrase extraction from scientific documents using n-gram filtration technique. In: Proceeding of the 8th ACM Symposium on Document Engineering. 2008, 199–208
Cui G, Lu Q, Li W, Chen Y. Mining concepts from wikipedia for ontology construction. In: Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology. 2009, 3: 287–290
Wang P, Domeniconi C. Building semantic kernels for text classification using wikipedia. In: Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2008, 713–721
Wang P, Hu J, Zeng H, Chen L, Chen Z. Improving text classification by using encyclopedia knowledge. In: Proceedings of the 7th IEEE International Conference on Data Mining. 2007, 332–341
Von Luxburg U. A tutorial on spectral clustering. Statistics and Computing, 2007, 17(4): 395–416
Carbonell J, Goldstein J. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In: Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 1998, 335–336
Xu J, Croft W. Improving the effectiveness of information retrieval with local context analysis. ACM Transactions on Information Systems (TOIS), 2000, 18(1): 79–112
Lin C. Rouge: A package for automatic evaluation of summaries. In: Text Summarization Branches Out: Proceedings of the ACL2004 WorkShop. 2004, 74–81
Hu P, Ji D, Teng C. Co-hits-ranking based query-focused multidocument summarization. Information Retrieval Technology, 2010, 6458: 121–130
Author information
Authors and Affiliations
Corresponding author
Additional information
Heng Chen currently is a PhD candidate in computer science at the School of Computer Science and Technology at Huazhong University of Science and Technology in China. His research interests include information retrieve and data mining.
Hai Jin, professor, dean of the School of Computer Science and Technology at Huazhong University of Science and Technology in China. He was awarded Excellent Youth Award from the National Science Foundation of China in 2001. Jin is the chief scientist of China-Grid, the largest grid computing project in China, and the chief scientist of National 973 Basic Research Program Project of Virtualization Technology of Computing System. Jin is a senior member of the IEEE and a member of the ACM. His research interests include computer architechture, grid computing, cluster computing, computer system virtualization, and massive data management.
Feng Zhao is currently an associate professor of Huazhong University at Science and Technology, China. His research interests include knowledge discovery, information retrieval, security, etc.
Rights and permissions
About this article
Cite this article
Chen, H., Jin, H. & Zhao, F. PSG: a two-layer graph model for document summarization. Front. Comput. Sci. 8, 119–130 (2014). https://doi.org/10.1007/s11704-013-2292-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11704-013-2292-2