
Abstract
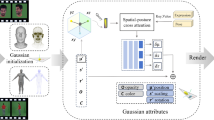
We present an animatable 3D Gaussian representation for synthesizing high-fidelity human videos under novel views and poses in real time. Given multi-view videos of a human subject, we learn a collection of 3D Gaussians in the canonical space of the rest pose. Each Gaussian is associated with a few basic properties (i.e., position, opacity, scale, rotation, spherical harmonics coefficients) representing the average human appearance across all video frames, as well as a latent code and a set of blend weights for dynamic appearance correction and pose transformation. The latent code is fed to an Multi-layer Perceptron (MLP) with a target pose to correct Gaussians in the canonical space to capture appearance changes under the target pose. The corrected Gaussians are then transformed to the target pose using linear blend skinning (LBS) with their blend weights. High-fidelity human images under novel views and poses can be rendered in real time through Gaussian splatting. Compared to state-of-the-art NeRF-based methods, our animatable Gaussian representation produces more compelling results with well captured details, and achieves superior rendering performance.
Similar content being viewed by others


References
Loper M, Mahmood N, Romero J, Pons-Moll G, Black M J. SMPL: a skinned multi-person linear model. In: Whitton M C, ed. Seminal Graphics Papers: Pushing the Boundaries, Volume 2. New York: ACM, 2023, 851–866
Allen B, Curless B, Popović Z. The space of human body shapes: reconstruction and parameterization from range scans. ACM Transactions on Graphics, 2003, 22(3): 587–594
Mildenhall B, Srinivasan P P, Tancik M, Barron J T, Ramamoorthi R, Ng R. NeRF: representing scenes as neural radiance fields for view synthesis. In: Proceedings of the 16th European Conference on Computer Vision. 2020, 405–421
Peng S, Dong J, Wang Q, Zhang S, Shuai Q, Zhou X, Bao H. Animatable neural radiance fields for modeling dynamic human bodies. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021, 14294–14303
Zhao F, Yang W, Zhang J, Lin P, Zhang Y, Yu J, Xu L. HumanNeRF: efficiently generated human radiance field from sparse inputs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, 7733–7743
Chen Y, Wang X, Chen X, Zhang Q, Li X, Guo Y, Wang J, Wang F. UV volumes for real-time rendering of editable free-view human performance. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, 16621–16631
Peng S, Zhang Y, Xu Y, Wang Q, Shuai Q, Bao H, Zhou X. Neural body: implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021, 9050–9059
Lin H, Peng S, Xu Z, Yan Y, Shuai Q, Bao H, Zhou X. Efficient neural radiance fields for interactive free-viewpoint video. In: Proceedings of the SIGGRAPH Asia 2022 Conference Papers. 2022, 39
Kerbl B, Kopanas G, Leimkuehler T, Drettakis G. 3D Gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 2023, 42(4): 139
Yang Z, Gao X, Zhou W, Jiao S, Zhang Y, Jin X. Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruction. 2023, arXiv preprint arXiv: 2309.13101
Jacobson A, Deng Z, Kavan L, Lewis J P. Skinning: real-time shape deformation (full text not available). In: Proceedings of the ACM SIGGRAPH 2014 Courses. 2014, 24
Joo H, Simon T, Sheikh Y. Total capture: a 3D deformation model for tracking faces, hands, and bodies. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2018, 8320–8329
Osman A A A, Bolkart T, Black M J. STAR: sparse trained articulated human body regressor. In: Proceedings of the 16th European Conference on Computer Vision. 2020, 598–613
Zhang C, Pujades S, Black M J, Pons-Moll G. Detailed, accurate, human shape estimation from clothed 3D scan sequences. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, 5484–5493
Guan P, Reiss L, Hirshberg D A, Weiss A, Black M J. DRAPE: dressing any PErson. ACM Transactions on Graphics, 2012, 31(4): 35
Xu F, Liu Y, Stoll C, Tompkin J, Bharaj G, Dai Q, Seidel H P, Kautz J, Theobalt C. Video-based characters: creating new human performances from a multi-view video database. In: Proceedings of the ACM SIGGRAPH 2011 Papers. 2011, 32
Habermann M, Liu L, Xu W, Zollhoefer M, Pons-Moll G, Theobalt C. Real-time deep dynamic characters. ACM Transactions on Graphics, 2021, 40(4): 94
Lombardi S, Simon T, Saragih J, Schwartz G, Lehrmann A, Sheikh Y. Neural volumes: learning dynamic renderable volumes from images. ACM Transactions on Graphics, 2019, 38(4): 65
Wu M, Wang Y, Hu Q, Yu J. Multi-view neural human rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, 1679–1688
Bagautdinov T, Wu C, Simon T, Prada F, Shiratori T, Wei S E, Xu W, Sheikh Y, Saragih J. Driving-signal aware full-body avatars. ACM Transactions on Graphics, 2021, 40(4): 143
Ma S, Simon T, Saragih J, Wang D, Li Y, De La Torre F, Sheikh Y. Pixel codec avatars. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021, 64–73
Yang G, Vo M, Neverova N, Ramanan D, Vedaldi A, Joo H. BANMo: building animatable 3D neural models from many casual videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, 2853–2863
Xu Z, Peng S, Lin H, He G, Sun J, Shen Y, Bao H, Zhou X. 4K4D: realtime 4D view synthesis at 4K resolution. 2023, arXiv preprint arXiv: 2310.11448
Xu Z, Peng S, Geng C, Mou L, Yan Z, Sun J, Bao H, Zhou X. Relightable and animatable neural avatar from sparse-view video. 2023, arXiv preprint arXiv: 2308.07903
Peng B, Hu J, Zhou J, Gao X, Zhang J. IntrinsicNGP: intrinsic coordinate based hash encoding for human NeRF. IEEE Transactions on Visualization and Computer Graphics, 2024, 30(8): 5679–5692
Zheng Z, Huang H, Yu T, Zhang H, Guo Y, Liu Y. Structured local radiance fields for human avatar modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, 15872–15882
Wang L, Zhang J, Liu X, Zhao F, Zhang Y, Zhang Y, Wu M, Yu J, Xu L. Fourier PlenOctrees for dynamic radiance field rendering in real-time. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, 13514–13524
Jiang T, Chen X, Song J, Hilliges O. InstantAvatar: learning avatars from monocular video in 60 seconds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, 16922–16932
Müller T, Evans A, Schied C, Keller A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics, 2022, 41(4): 102
Buehler C, Bosse M, McMillan L, Gortler S, Cohen M. Unstructured lumigraph rendering. In: Whitton M C, ed. Seminal Graphics Papers: Pushing the Boundaries, Volume 2. New York: ACM, 2023, 52
Davis A, Levoy M, Durand F. Unstructured light fields. Computer Graphics Forum, 2012, 31(2pt1): 305–314
Eisemann M, De Decker B, Magnor M, Bekaert P, De Aguiar E, Ahmed N, Theobalt C, Sellent A. Floating textures. Computer Graphics Forum, 2008, 27(2): 409–418
Yu A, Li R, Tancik M, Li H, Ng R, Kanazawa A. PlenOctrees for realtime rendering of neural radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021, 5732–5741
Garbin S J, Kowalski M, Johnson M, Shotton J, Valentin J. FastNeRF: high-fidelity neural rendering at 200FPS. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021, 14326–14335
Zielonka W, Bagautdinov T, Saito S, Zollhöfer M, Thies J, Romero J. Drivable 3D Gaussian avatars. 2023, arXiv preprint arXiv: 2311.08581
Li Z, Zheng Z, Wang L, Liu Y. Animatable Gaussians: learning pose-dependent Gaussian maps for high-fidelity human avatar modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2024, 19711–19722
Wang L, Zhao X, Sun J, Zhang Y, Zhang H, Yu T, Liu Y. StyleAvatar: real-time photo-realistic portrait avatar from a single video. In: Proceedings of the ACM SIGGRAPH 2023 Conference Proceedings. 2023, 67
Jena R, Iyer G S, Choudhary S, Smith B, Chaudhari P, Gee J. SplatArmor: articulated Gaussian splatting for animatable humans from monocular RGB videos. 2023, arXiv preprint arXiv: 2311.10812
Moreau A, Song J, Dhamo H, Shaw R, Zhou Y, Pérez-Pellitero E. Human Gaussian splatting: real-time rendering of animatable avatars. 2023, arXiv preprint arXiv: 2311.17113
Kocabas M, Chang J H R, Gabriel J, Tuzel O, Ranjan A. HUGS: human Gaussian splats. 2023, arXiv preprint arXiv: 2311.17910
Hu S, Liu Z. GauHuman: articulated Gaussian splatting from monocular human videos. 2023, arXiv preprint arXiv: 2312.02973
Lei J, Wang Y, Pavlakos G, Liu L, Daniilidis K. GART: Gaussian articulated template models. 2023, arXiv preprint arXiv: 2311.16099
Hu L, Zhang H, Zhang Y, Zhou B, Liu B, Zhang S, Nie L. GaussianAvatar: towards realistic human avatar modeling from a single video via animatable 3D Gaussians. 2023, arXiv preprint arXiv: 2312.02134
Xiang J, Gao X, Guo Y, Zhang J. FlashAvatar: high-fidelity digital avatar rendering at 300FPS. 2023, arXiv preprint arXiv: 2312.02214
Lin S, Ryabtsev A, Sengupta S, Curless B, Seitz S, Kemelmacher-Shlizerman I. Real-time high-resolution background matting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021, 8758–8767
Shoemake K, Duff T. Matrix animation and polar decomposition. In: Proceedings of the Conference on Graphics Interface. 1992, 258–264
Zhang R, Isola P, Efros A A, Shechtman E, Wang O. The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2018, 586–595
Ionescu C, Papava D, Olaru V, Sminchisescu C. Human3.6M: large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1325–1339
Joo H, Simon T, Li X, Liu H, Tan L, Gui L, Banerjee S, Godisart T, Nabbe B, Matthews I, Kanade T, Nobuhara S, Sheikh Y. Panoptic studio: a massively multiview system for social interaction capture. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(1): 190–204
Liu Y, Li Z, Liu Y, Wang H. TexVocab: texture vocabulary-conditioned human avatars. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, 1715–1725
Acknowledgements
This work was supported by the National Key R&D Program of China (No. 2022YFF0902302) and the National Natural Science Foundation of China (Grant Nos. 62172357 & 62322209).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests The authors declare that they have no competing interests or financial conflicts to disclose.
Additional information
Yukun Xu is a postgraduate at the State Key Lab of CAD&CG, Zhejiang University, China. His research interests include computer graphics and digital human.
Keyang Ye received the bachelor’s degree from National University of Defense Technology, China in 2022. He is currently working toward the PhD degree in the Graphics and Parallel Systems Lab of Zhejiang University, China. His research interests include animation and rendering.
Tianjia Shao is a professor in the State Key Laboratory of CAD&CG, Zhejiang University, China. Previously, he was a Lecturer in the School of Computing, University of Leeds, UK. He received his PhD in computer science from Institute for Advanced Study, Tsinghua University, and his BS from the Department of Automation, Tsinghua University, China. His research focuses on 3D modeling, digital human, and computer animation.
Yanlin Weng received the bachelor’s and master’s degrees in control science and engineering from Zhejiang University, China and the PhD degree in computer science from the University of Wisconsin - Milwaukee, USA. She is currently an associate professor with the School of Computer Science and Technology, Zhejiang University. Her research interests include computer graphics and multimedia.
Electronic supplementary material
Rights and permissions
About this article

Cite this article
Xu, Y., Ye, K., Shao, T. et al. Animatable 3D Gaussians for modeling dynamic humans. Front. Comput. Sci. 19, 199704 (2025). https://doi.org/10.1007/s11704-024-40497-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11704-024-40497-5