
Abstract
In this study, we utilize attention mechanisms to leverage the spatio-temporal information available in videos for the action recognition and collective activity recognition tasks. In this context, we explore 2D and 3D attention mechanisms and investigate their effect on capturing the related action information. To this end, we introduce a framework for incorporating 2D and 3D-attention with two distinct 3D-ConvNets architectures, which are standard 3D-ConvNets (C3D) and inflated 3D-ConvNets (I3D). We evaluate this framework on four benchmark datasets; UCF101, and HMDB51 for action recognition and CAD and C-Sports for collective activity recognition. Experimental results show that the 3D attention-based ConvNets improves the performance on all datasets when compared to the architectures that do not leverage any attention mechanism. Our results also indicate that 3D attention mechanism yields higher recognition performance compared to its 2D attention counterpart.







Similar content being viewed by others
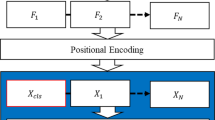
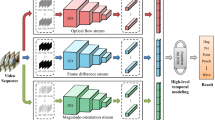
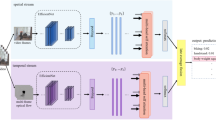
References
Addabbo, P., Bernardi, M.L., Biondi, F., Cimitile, M., Clemente, C., Orlando, D.: Gait recognition using fmcw radar and temporal convolutional deep neural networks. In: 2020 IEEE 7th International Workshop on Metrology for AeroSpace (MetroAeroSpace), pp. 171–175 (2020)
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6299–6308 (2017)
Chen, Q., Zhang, W., Lou, Y.: Forecasting stock prices using a hybrid deep learning model integrating attention mechanism, multi-layer perceptron, and bidirectional long-short term memory neural network. IEEE Access 8, 117365–117376 (2020)
Cheng, L.C., Huang, Y.H., Wu, M.E.: Applied attention-based lstm neural networks in stock prediction. In: 2018 IEEE International Conference on Big Data (Big Data), pp. 4716–4718. IEEE (2018)
Cheng, Y.: Semi-supervised learning for neural machine translation. In: Joint Training for Neural Machine Translation, pp. 25–40. Springer (2019)
Choi, W., Shahid, K., Savarese, S.: What are they doing?: Collective activity classification using spatio-temporal relationship among people. In: EEE International Conference on Computer Vision Workshops (ICCV Workshops), pp. 1282–1289. IEEE (2009)
Fukui, H., Hirakawa, T., Yamashita, T., Fujiyoshi, H.: Attention branch network: Learning of attention mechanism for visual explanation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10705–10714 (2019)
Hara, K., Kataoka, H., Satoh, Y.: Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6546–6555 (2018)
He, D., Li, F., Zhao, Q., Long, X., Fu, Y., Wen, S.: Exploiting spatial-temporal modelling and multi-modal fusion for human action recognition. arXiv preprint arXiv:1806.10319 (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. CVPR (2016)
Ji, S., Xu, W., Yang, M., Yu, K.: 3d convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 35(1), 221–231 (2013)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS, pp. 1097–1105 (2012)
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: HMDB: a large video database for human motion recognition. In: Proceedings of the International Conference on Computer Vision (ICCV) (2011)
Lei, J., Jia, Y., Peng, B., Huang, Q.: Channel-wise temporal attention network for video action recognition. In: 2019 IEEE International Conference on Multimedia and Expo (ICME), pp. 562–567. IEEE (2019)
Li, H., Shen, Y., Zhu, Y.: Stock price prediction using attention-based multi-input lstm. In: Asian conference on machine learning, pp. 454–469. PMLR (2018)
Li, L., Gan, Z., Cheng, Y., Liu, J.: Relation-aware graph attention network for visual question answering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2019)
Lin, W., Mi, Y., Wu, J., Lu, K., Xiong, H.: Action recognition with coarse-to-fine deep feature integration and asynchronous fusion. arXiv preprint arXiv:1711.07430 (2017)
Liu, J., Rojas, J., Liang, Z., Li, Y., Guan, Y.: A graph attention spatio-temporal convolutional network for 3d human pose estimation in video. arXiv preprint arXiv:2003.14179 (2020)
Liu, M., Li, L., Hu, H., Guan, W., Tian, J.: Image caption generation with dual attention mechanism. Inf. Process. Manage. 57(2), 102178 (2020)
Liu, R., Shen, J., Wang, H., Chen, C., Cheung, S.c., Asari, V.: Attention mechanism exploits temporal contexts: Real-time 3d human pose reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5064–5073 (2020)
Liu, R., Shen, J., Wang, H., Chen, C., Cheung, S.C., Asari, V.K.: Enhanced 3d human pose estimation from videos by using attention-based neural network with dilated convolutions. Int. J. Comput. Vis. 129(5), 1596–1615 (2021)
Martin, P.E., Benois-Pineau, J., Péteri, R., Morlier, J.: 3d attention mechanism for fine-grained classification of table tennis strokes using a twin spatio-temporal convolutional neural networks. In: 2020 25th International Conference on Pattern Recognition (ICPR), pp. 6019–6026. IEEE (2021)
Sharma, S., Kiros, R., Salakhutdinov, R.: Action recognition using visual attention. In: Neural Information Processing Systems (NIPS) Time Series Workshop (2015)
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Adv. Neural. Inf. Process. Syst., pp. 568–576 (2014)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (2015)
Soomro, K., Zamir, A.R., Shah, M.: Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in neural information processing systems, pp. 3104–3112 (2014)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems, pp. 5998–6008 (2017)
Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., Wang, X., Tang, X.: Residual attention network for image classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3156–3164 (2017)
Williams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 8(3–4), 229–256 (1992)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: Neural image caption generation with visual attention. In: International conference on machine learning, pp. 2048–2057 (2015)
Yan, S., Xie, Y., Wu, F., Smith, J.S., Lu, W., Zhang, B.: Image captioning via hierarchical attention mechanism and policy gradient optimization. Signal Process. 167, 107329 (2020)
Yang, Z., He, X., Gao, J., Deng, L., Smola, A.: Stacked attention networks for image question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 21–29 (2016)
You, Q., Jin, H., Wang, Z., Fang, C., Luo, J.: Image captioning with semantic attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4651–4659 (2016)
Zalluhoglu, C., Ikizler-Cinbis, N.: Collective sports: A multi-task dataset for collective activity recognition. Image and Vision Computing p. 103870 (2020)
Zhou, Y., Mishra, S., Gligorijevic, J., Bhatia, T., Bhamidipati, N.: Understanding consumer journey using attention based recurrent neural networks. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 3102–3111 (2019)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zalluhoglu, C., Ikizler-Cinbis, N. Comparison of 2D and 3D attention mechanisms for human (collective) activity recognition. SIViP 16, 865–872 (2022). https://doi.org/10.1007/s11760-021-02028-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-021-02028-8