
Abstract
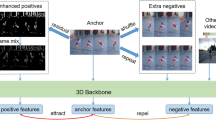
Self-supervised video representation learning attempts to extract latent spatiotemporal semantic information from unlabeled data that will be used for downstream visual understanding tasks. However, we found that in mainstream video datasets, the same actions may be marked as inconsistent categories in different environments. Therefore, it is crucial to concentrate on motion features and background areas while extracting the spatial and temporal characteristics of the video. This paper presents a self-supervised action recognition framework to learn the dynamic–static features of video by combining the pretext task with cross-view contrastive learning. Specifically, we first introduce a video cloze procedure pretext task that exploits temporally strong correlations to obtain prediction categories for further supervised information generation. Next, multi-view contrastive learning is proposed to extract motion characteristics and global semantic information from consecutive video frames. Through joint optimization of the pretext task and multiple contrast losses, our method demonstrates that the recognition accuracy on the UCF101 and HMDB51 datasets is 1.2% and 0.8% higher than the highest accuracy obtained by using residual contrastive and 1.3% and 0.4% higher than that obtained by using RGB contrastive only. Experimental results with different datasets and backbone networks demonstrate that our proposal can significantly increase the generalization and robustness of the model.



Similar content being viewed by others


Availability of data and materials
The datasets generated during and/or analyzed during the current study are available in the network.
References
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 7794-7803 (2018)
Mouatasim, El.: A. Fast gradient descent algorithm for image classification with neural networks. Signal, Image Video Process 14, 1565–1572 (2020)
Huang, Q., Zhou, F., Qin, R., Zhao, Y.: View transform graph attention recurrent networks for skeleton-based action recognition. Signal, Image Video Process 15, 599–606 (2021)
Krizhevsky, A., Sutskever, L., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. Commun. ACM. 60, 84–90 (2017)
Carreira, J., Zisserman, A.: action recognition? a new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299-6308 (2017)
Noroozi, M., Favaro, P.: Unsupervised learning of visual representations by solving jigsaw puzzles. In: European Conference on Computer Vision. pp. 69-84 (2016)
Kim, D., Cho, D., Kweon, IS.: Self-supervised video representation learning with space-time cubic puzzles. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 8545-8552 (2019)
Wu, Z., Xiong, Y., Yu, S., Lin, D.: Unsupervised feature learning via non-parametric instance discrimination. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3733-3742 (2018)
Misra, I., Maaten, L.: Self-supervised learning of pretext-invariant representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6707-6717 (2020)
Luo, D., Liu, C., Zhou, Y., Yang, D., Ma, C.: Video cloze procedure for self-supervised spatiotemporal learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 11701-11708 (2020)
Zhang, R., Isola, P., Efros, AA.: Colorful image colorization. In: European Conference on Computer Vision. pp. 649-666 (2016)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9729-9738 (2020)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International Conference on Machine Learning. pp. 1597-1607 (2020)
Chen, X., He, K.: Exploring simple siamese representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15750-15758 (2021)
Lee, HY., Huang, JB., Singh, M., Yang, MH.: Unsupervised representation learning by sorting sequences. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 667-676 (2017)
Yao, Y., Liu, C., Luo, D., Zhou, Y., Ye, Q.: Video playback rate perception for self-supervised spatiotemporal representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6548-6557 (2020)
Qian, R., Meng, T., Gong, B., Yang, MH., Wang, H., Belongie, S., Cui, Y.: Spatiotemporal contrastive video representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6964-6974 (2021)
Dave, I., Gupta, R., Rizve, M.: Tclr: Temporal contrastive learning for video representation. Comput. Vis. Image Underst. (2022). https://doi.org/10.1016/j.cviu.2022.103406
Han, T., Xie, W., Zisserman, A.: Self-supervised co-training for video representation learning. Adv. Neural. Inf. Process. Syst. 33, 5679–5690 (2020)
Tao, L., Wang, X., Yamasaki, T.: Self-supervised video representation learning using inter-intra contrastive framework. In: Proceedings of the 28th ACM International Conference on Multimedia. pp. 2193-2201 (2020)
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 4489-4497 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 770-778 (2016)
Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6450-6459 (2016)
Zhang, Z., Crandall, D.: Hierarchically decoupled spatial-temporal contrast for self-supervised video representation learning. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 3235-3245 (2022)
Wang, J., Jiao, L., Bao, S., He, W., Liu, Y.: Self-supervised video representation learning by uncovering spatiotemporal statistics. IEEE Trans. Pattern Anal. Mach. Intell. (2021). https://doi.org/10.1109/TPAMI.2021.3057833
Liu, C., Yao, Y., Luo, D., Zhou, Y., Ye, Q.: Self-Supervised Motion Perception for Spatiotemporal Representation Learning. In: IEEE Transactions on Neural Networks and Learning Systems. pp. 1-15 (2022)
Chen, P., Huang, D., He, D., Long, X., Zeng, R., Wen, S., Gan, C.: RSPNET: Relative speed perception for unsupervised video representation learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, 35. pp. 1045-1053 (2022)
Bi, S., Hu, Z., Zhao, M., Li, S., Sun, Z.: Spatiotemporal consistency enhancement self-supervised representation learning for action recognition. Signal, Image Video Process. (2022). https://doi.org/10.1007/s11760-022-02357-2
Guo, S., Xiong, Z., Zhong, Y., Wang, L., Guo, X., Han, B., Huang, W.: Cross-architecture self-supervised video representation Learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19270-19279 (2022)
Liu, Y., Wang, K., Liu, L., Lan, H., Lin, L.: TCGL: temporal contrastive graph for self-supervised video representation learning. IEEE Trans. Image Process. 31, 1978–1993 (2022)
Funding
This work was supported by the National Natural Science Foundation of China under Grants 62001413 and the National Natural Science Foundation of Hebei Province under Grants F2020203064.
Author information
Authors and Affiliations
Contributions
Shuai Bi and Zhengping Hu prepared the first draft of the manuscript and Mengyao Zhao contributed significantly to analysis and manuscript preparation, Hehao Zhang and Jirui Di helped perform the analysis with constructive discussions, Zhe Sun reviewed the manuscript and checked some grammar. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflicts of interest to this work.
Ethics approval and consent to participate
All the experimental subjects in this study do not include any animals or people and do not violate ethics.
Consent for publication
All the authors agreed to publish the article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bi, S., Hu, Z., Zhao, M. et al. Self-supervised pretext task collaborative multi-view contrastive learning for video action recognition. SIViP 17, 3775–3782 (2023). https://doi.org/10.1007/s11760-023-02605-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-023-02605-z