
Abstract
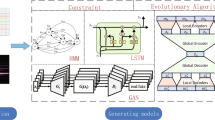
Generating expressive musical performance (EMP) is a hot issue in the field of music generation. Music played by humans is always more expressive than music produced by machines. To figure this out, it is crucial to explore the role of human performance in the production of music. This paper proposes a performance style transfer model to learn human performance style and implement EMP system. Our model is implemented using generative adversarial networks (GANs), with a multi-channel image composed of four elaborated spectrograms serving as the input to decompose and reconstruct music audio. To ensure training stability, we have designed a multi-channel consistency loss for GANs. Furthermore, given the lack of objective evaluation criteria for music generation, we propose a hybrid evaluation method that combines qualitative and quantitative methods to evaluate human-needs satisfaction. Three quantitative criteria are proposed at the feature and audio levels, respectively. The effectiveness of our method is verified on a public dataset through objective evaluation, which demonstrates its comparability to state-of-the-art algorithms. Additionally, subjective evaluations are conducted through visual analyses of both audio content and style. Finally, we conduct a musical Turing test in which subjects score the performance of the generated music. A series of experimental results show that our method is very competitive.






Similar content being viewed by others

Availability of data and materials
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Notes
https://www.piano-e-competition.com/
References
Zhang, Z., Zhou, X., Qin, M., Chen, X.: Chinese character style transfer based on multi-scale gan. Signal Image Video Process. 16(2), 559–567 (2022)
Xue, A.: End-to-end Chinese landscape painting creation using generative adversarial networks. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 3863–3871 (2021)
Muhamed, A., Li, L., Shi, X., Yaddanapudi, S., Chi, W., Jackson, D., Suresh, R., Lipton, Z.C., Smola, A.J.: Symbolic music generation with transformer-gans. Proc. AAAI Conf. Artif. Intell. 35(1), 408–417 (2021)
Isola, P., Zhu, J.-Y., Zhou, T., Efros, A. A.: Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1125–1134 (2017)
Dai, S., Zhang, Z., Xia, G.G.: Music style transfer: a position paper. (2018) arXiv:1803.06841
Oore, S., Simon, I., Dieleman, S., Eck, D., Simonyan, K.: This time with feeling: learning expressive musical performance. Neural Comput. Appl. 32(4), 955–967 (2020)
Anantrasirichai, N., Bull, D.: Artificial intelligence in the creative industries: a review. Artif. Intell. Rev., pp. 1–68 (2022)
Wiegreffe, S., Pinter, Y.: Attention is not not explanation. (2019) arXiv:1908.04626
Huang, C.-Z. A., Vaswani, A., Uszkoreit, J., Shazeer, N., Simon, I., Hawthorne, C., Dai, A. M., Hoffman, M. D., Dinculescu, M., Eck, D.: Music transformer (2018). arXiv:1809.04281
Child, R., Gray, S., Radford, A., Sutskever, I.: Generating long sequences with sparse transformers. (2019). arXiv:1904.10509
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., Salakhutdinov, R.: Transformer-xl: attentive language models beyond a fixed-length context (2019). arXiv:1901.02860
Donahue, C., Mao, H.H., Li, Y.E., Cottrell, G.W., McAuley, J.: Lakhnes: improving multi-instrumental music generation with cross-domain pre-training. (2019). arXiv:1907.04868
Engel, J., Resnick, C., Roberts, A., Dieleman, S., Norouzi, M., Eck, D., Simonyan, K.: Neural audio synthesis of musical notes with wavenet autoencoders. In: International Conference on Machine Learning. PMLR, pp. 1068–1077 (2017)
Verma, P., Smith, J.O.: Neural style transfer for audio spectograms. (2018). arXiv:1801.01589
Friberg, A., Bresin, R., Sundberg, J.: Overview of the kth rule system for musical performance. Adv. Cognit. Psychol. 2(2), 145 (2006)
Teramura, K., Okuma, H., Taniguchi, Y., Makimoto, S., Maeda, S.-i.: Gaussian process regression for rendering music performance. In: Proceedings of the 10th International Conference on Music Perception and Cognition, ICMPC, pp. 167–172 (2008)
Chacón, C.E.C., Grachten, M.: The basis mixer: a computational romantic pianist. In: Late-Breaking Demos of the 17th International Society for Music Information Retrieval Conf. (ISMIR) (2016)
Kirke, A., Miranda, E.R.: An overview of computer systems for expressive music performance. Guide Comput. Expressive Music Perform., pp. 1–47 (2012)
Grachten, M., Widmer, G.: Linear basis models for prediction and analysis of musical expression. J. New Music Res. 41(4), 311–322 (2012)
Cancino-Chacón, C.E.: Computational Modeling of Expressive Music Performance with Linear and Non-linear Basis Function Models. Johannes Kepler University, Linz (2018)
Cancino-Chacón, C.E., Gadermaier, T., Widmer, G., Grachten, M.: An evaluation of linear and non-linear models of expressive dynamics in classical piano and symphonic music. Mach. Learn. 106(6), 887–909 (2017)
Grachten, M., Krebs, F.: An assessment of learned score features for modeling expressive dynamics in music. IEEE Trans. Multimed. 16(5), 1211–1218 (2014)
Peperkamp, J., Hildebrandt, K., Liem, C.C.S.: A formalization of relative local tempo variations in collections of performances. In: Proceedings of the 18th International Society for Music Information Retrieval Conference, pp. 158–164 (2017)
Moulieras, S., Pachet, F.: Maximum entropy models for generation of expressive music. (2016). arXiv:1610.03606
Van Herwaarden, S., Grachten, M., De Haas, W.B., Wang, H.-M., Yang, Y.-H., Lee, J.H., et al. Predicting expressive dynamics in piano performances using neural networks. In: Proceedings of the 15th Conference of the International Society for Music Information Retrieval (ISMIR 2014). International Society for Music Information Retrieval, pp. 45–52 (2014)
Malik, I., Ek, C.H.: Neural translation of musical style (2017). arXiv:1708.03535
Jeong, D., Kwon, T., Kim, Y., Lee, K., Nam, J.: Virtuosonet: a hierarchical rnn-based system for modeling expressive piano performance. In: ISMIR, pp. 908–915 (2019)
Maezawa, A., Yamamoto, K., Fujishima, T.: Rendering music performance with interpretation variations using conditional variational rnn. In: ISMIR, pp. 855–861 (2019)
Shi, Z.: Computational analysis and modeling of expressive timing in Chopin’s mazurkas. In: Proceedings of the 22nd ISMIR Conference, pp. 650–656 (2021)
Zhu, J.-Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2223–2232 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1501–1510 (2017)
Jolicoeur-Martineau, A.: The relativistic discriminator: a key element missing from standard gan (2018). arXiv:1807.00734
Funding
This work is supported by the Technical Innovation Major Project of Hubei Province, China, under Grant 2020AEA010 and the Natural Science Foundation of Hubei Province, China, under Grant 2020CFA031 and Grant 2019CFB581.
Author information
Authors and Affiliations
Contributions
ZX and XC wrote the main manuscript text and LZ polished the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
I declare that the authors have no competing interests as defined by Springer, or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Ethical approval
This declaration is not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xiao, Z., Chen, X. & Zhou, L. Music performance style transfer for learning expressive musical performance. SIViP 18, 889–898 (2024). https://doi.org/10.1007/s11760-023-02788-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-023-02788-5