
Abstract
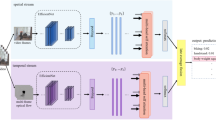
In this paper, we propose a Three-stream Inception Former-based Action Recognition Network, called TIFAR-Net to recognize actions in Infrared (IR) videos. It consists of two major stages. First, fine-tuning and feature extraction using a Inception Transformer (IFormer) network, and second, feature fusion and classification using Multi-Head Self-Attention (MHSA) network. Specifically, input IR videos are converted into compact yet effective representations referred to as Optical Flow Motion Images, Optical Flow Dynamic Images and Infrared Motion Images. The first two types of images are constructed using optical flow fields, while the third type of image is computed directly from raw IR frames. These image-based representations enable us to fine-tune a three-stream IFormer network, which is a hybrid Convolution Neural Network and Vision Transformer model. Features extracted from each stream are concatenated and passed through MHSA module to prune unimportant information and capture key global information from input images. Finally, classification is performed using fully connected and Softmax layers. Through extensive ablation experiments, we verified that our proposed TIFAR-Net improves the performance of IR action recognition and achieves state-of-the-art results on InfAR dataset (88.5%), IITR-IAR dataset (77.93%) and UNISV dataset(97.08%).










Similar content being viewed by others

Data Availability
No datasets were generated or analysed during the current study.
References
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., Schmid, C.: Vivit: A video vision transformer. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 6836–6846 (2021)
Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: International Conference on Machine Learning 2, 4 (2021)
Bilen, H., Fernando, B., Gavves, E., Vedaldi, A., Gould, S.: Dynamic image networks for action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 3034–3042 (2016)
Brox, T., Bruhn, A., Papenberg, N., Weickert, J.: High accuracy optical flow estimation based on a theory for warping. In: European Conference on Computer Vision, pp. 25–36. Springer (2004)
Bulat, A., Perez Rua, J.M., Sudhakaran, S., Martinez, B., Tzimiropoulos, G.: Space-time mixing attention for video transformer. Adv. Neural. Inf. Process. Syst. 34, 19594–19607 (2021)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 6299–6308 (2017)
Chen, X., Gao, C., Li, C., Yang, Y., Meng, D.: Infrared action detection in the dark via cross-stream attention mechanism. IEEE Trans. Multimedia 24, 288–300 (2021)
Chen, Y., Zhang, Z., Yuan, C., Li, B., Deng, Y., Hu, W.: Channel-wise topology refinement graph convolution for skeleton-based action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 13359–13368 (2021)
Feichtenhofer, C.: X3d: Expanding architectures for efficient video recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 203–213 (2020)
Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recognition. In: IEEE International Conference on Computer Vision, pp. 6202–6211 (2019)
Feichtenhofer, C., Pinz, A., Zisserman, A.: Convolutional two-stream network fusion for video action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1933–1941 (2016)
Feng, Z., Wang, X., Zhou, J., Du, X.: Mdj: A multi-scale difference joint keyframe extraction algorithm for infrared surveillance video action recognition. Digital Signal Processing 148, 104469 (2024)
Gao, C., Du, Y., Liu, J., Lv, J., Yang, L., Meng, D., Hauptmann, A.G.: Infar dataset: Infrared action recognition at different times. Neurocomputing 212, 36–47 (2016)
Hatamizadeh, A., Heinrich, G., Yin, H., Tao, A., Alvarez, J.M., Kautz, J., Molchanov, P.: Fastervit: Fast vision transformers with hierarchical attention. arXiv preprint arXiv:2306.06189 (2023)
Hinton, G., Van Der Maaten, L.: Visualizing data using t-sne. J. Mach. Learn. Res. 9, 2579–2605 (2008)
Hou, Y., Yu, H., Zhou, D., Wang, P., Ge, H., Zhang, J., Zhang, Q.: Local-aware spatio-temporal attention network with multi-stage feature fusion for human action recognition. Neural Comput. Appl. 33, 16439–16450 (2021)
Imran, J., Raman, B.: Deep residual infrared action recognition by integrating local and global spatio-temporal cues. Infrared Physics & Technology 102, 103014 (2019)
Imran, J., Raman, B.: Evaluating fusion of rgb-d and inertial sensors for multimodal human action recognition. J. Ambient. Intell. Humaniz. Comput. 11(1), 189–208 (2020)
Jiang, Z., Rozgic, V., Adali, S.: Learning spatiotemporal features for infrared action recognition with 3d convolutional neural networks. In: IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 115–123 (2017)
Lamghari, S., Bilodeau, G.A., Saunier, N.: Actar: Actor-driven pose embeddings for video action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 399–408 (2022)
Li, K., Wang, Y., Zhang, J., Gao, P., Song, G., Liu, Y., Li, H., Qiao, Y.: Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 45(10), 12581–12600 (2023)
Li, Y., Hu, J., Wen, Y., Evangelidis, G., Salahi, K., Wang, Y., Tulyakov, S., Ren, J.: Rethinking vision transformers for mobilenet size and speed. In: IEEE International Conference on Computer Vision, pp. 16889–16900 (2023)
Liu, Y., Lu, Z., Li, J., Yang, T., Yao, C.: Global temporal representation based cnns for infrared action recognition. IEEE Signal Process. Lett. 25(6), 848–852 (2018)
Liu, Y., Lu, Z., Li, J., Yao, C., Deng, Y.: Transferable feature representation for visible-to-infrared cross-dataset human action recognition. Complexity 2018(1), 5345241 (2018)
Nie, J., Yan, L., Wang, X., Chen, J.: A novel 3d convolutional neural network for action recognition in infrared videos. In: International Conference on Information Communication and Signal Processing, pp. 420–424 (2021)
Sharir, G., Noy, A., Zelnik-Manor, L.: An image is worth 16x16 words, what is a video worth? arXiv preprint arXiv:2103.13915 (2021)
Si, C., Yu, W., Zhou, P., Zhou, Y., Wang, X., Yan, S.: Inception transformer. Adv. Neural. Inf. Process. Syst. 35, 23495–23509 (2022)
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Advances in Neural Information Processing Systems, pp. 568–576 (2014)
Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 6450–6459 (2018)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in Neural Information Processing Systems 30 (2017)
Wang, L., Gao, C., Yang, L., Zhao, Y., Zuo, W., Meng, D.: Pm-gans: Discriminative representation learning for action recognition using partial-modalities. In: European Conference on Computer Vision, pp. 384–401 (2018)
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., Van Gool, L.: Temporal segment networks: Towards good practices for deep action recognition. In: European Conference on Computer Vision, pp. 20–36. Springer (2016)
Yang, C., Xu, Y., Shi, J., Dai, B., Zhou, B.: Temporal pyramid network for action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 591–600 (2020)
Author information
Authors and Affiliations
Contributions
All authors made substantial contributions to the concept and design of the paper. Methodology was done by JI and ASR, software development was done by JI and RV, and project administration/supervision was done by JI and ASR. All the authors read and approved the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Imran, J., Rajput, A.S. & Vashisht, R. Tifar-net: three-stream inception former-based action recognition network for infrared videos. SIViP 19, 192 (2025). https://doi.org/10.1007/s11760-024-03796-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11760-024-03796-9