
Abstract
Road traffic infrastructure in a city is as essential as veins in the human body. In Romania, road infrastructure is classified based on traffic intensity into four types of streets: magistral (used for crossing the city), connection, collection, and local use. This study utilizes the TRIB crack dataset (Traffic Road Infrastructure from Bucharest crack dataset), which consists of high-quality images of various types of road cracks. The dataset can be effectively used for different computer vision tasks, such as classification, object detection, and more. To meet the diverse requirements of deep learning methods, the dataset includes images capturing different types of road cracks, such as longitudinal, transverse, block, and alligator cracks, as well as various artifacts like oil stains, road markings on asphalt, leaves, and more. The images were taken from a height of 100 centimeters above the road surface, resulting in a dataset of 137 RGB (red, green, blue) images. To make the images suitable for deep learning methods, they were divided into smaller images with a resolution of 256 × 256 pixels. Additionally, various image augmentation techniques were applied. During the splitting process, some images contained no cracks, while others included cracks. This resulted in the creation of two distinct subsets: one containing image with road cracks and another with images without cracks.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Literature review
Detection of road cracks using deep learning demonstrates that is a more efficient method than human visual inspection of road surfaces. It has the potential to reduce the time needed to inspect traffic surface within a city using less resources and being more efficient.
Using a system based on the YOLO v2 deep learning framework (Mandal et al. 2018) trained on a dataset which contains 7240 images captured with a mobile camera, in matter of accuracy metrics it was obtained the following metrics: precision 88.51%, recall 87.10% and F1 score 97.80%. This system can analyze alligator cracks and potholes with a better accuracy than other types of asphalts distress.
Using machine vision technique on a camera to obtain the pavement crack image followed by computer software to process these images (Liu et al. 2022), it was obtained accuracy of crack detection over 90%, accuracy of crack area, length and average width over 95% and area accuracy of reticulated crack 99.93%. In the matter of crack shape, the accuracy was 100%. As a conclusion, machine vision used as crack detection technology reduce the workload and improve the detection efficiency and accuracy.
Traffic Road Infrastructure from Bucharest dataset includes a variety of real-world images that encompass different types of road cracks and artifacts, making it a valuable tool for advancing research in the domain of computer vision for infrastructure analysis.
Also, my dataset includes unique characteristics, such as its diversity in road crack types, environmental conditions, and the inclusion of artifacts commonly encountered in real-world road surfaces.
Importance of the dataset created
• TRIB crack dataset was generated by the author of this study using a professional digital camera. During the data collection process, seven streets in Bucharest, the capital of Romania, were inspected at different times of the day (morning, noon, and evening). The streets selected for image capturing were categorized as local roads (with low traffic, located in a residential area) based on traffic intensity. The road layer structure of these local roads is illustrated in Fig. 1.

Layers infrastructure of local roads
Figure 1 was created using the building design software AutoCAD. The affected layer, where cracks appear on the road surface, is the first layer, specifically BA 16.
As it can be seen in Fig. 2c) the layer affected by cracks is BA16. During repairs, only this kind of material is supplied on site due to fact that is not economically to supply and lay on site BAD25 material. BA16 material can replace BAD 25 material but reversing is not possible.
BA16 - means the asphalt layer.
BAD 25 – means the support of the asphalt layer.
• TRIB crack dataset consists in various types of asphalt cracks (longitudinal, transversal, potholes, block) which makes it suitable to be used in deep learning crack detection methods as is shown in Fig. 2.

Example of TRIB crack dataset images: a longitudinal, b transversal, c pothole, d block
• TRIB crack dataset encompasses various crack detection challenges as is shown in Fig. 3 which includes: shadows, different time of the day lighting conditions, leaf, oil stains.

Example of TRIB crack dataset images challenges: a longitudinal traffic paint, b leaf, c oil stains, d lighting condition (evening).
• Beside the crack detection challenges mentioned above and detailed as examples in Fig. 3, in Fig. 4 are detailed components the road traffic infrastructure such as manholes lids and sink holes lids which are included in TRIB crack dataset.

Components of road traffic infrastructure: a manholes, lids (b) sinkholes lids
• The images part of the TRIB crack dataset were taken at 100 cm above the road surface.
Objectives
A bad road infrastructure has a negative impact to the economic development (Sihombing and Aritonang 2024) of cities. Thus, the authorities are constrained to take measures constantly to avoid these kinds of negative effects. Due to fact that cities are permanent developed and expanded, new road infrastructure is executed. But also, the existing infrastructure needs to be maintained when is needed. To do so, is necessary to be adopted solutions to supervise this infrastructure at reduced cost.
A solution adopted and commonly used in a large variety of domains (medical, transportation, agriculture and so on) which involves reduced costs is computer vision (Zhao et al. 2024). By using machine learning (ML) and neural networks from digital images are extracted meaningful information which are used to area which involve image classification or object detection.
ML methods can be divided into two main categories: deep learning and traditional machine learning (Shi et al. 2024). In case of traditional machine learning the data used for training can be labeled this being defined as a supervised learning (algorithms like support vector machine, logistic regression) and unlabeled data being defined as unsupervised learning (clustering algorithms like K-means).
Using an efficient algorithm for crack detection for the existing infrastructure can be observed and located where is necessary to be performed road repairs and at the same time it can be observed how the existing cracks presented on the road surface are performing at different time periods.
For further comparisons of cracks, it is necessary to keep the same distance to road surface to have the precession of crack width during period. Wheater conditions such freezing/defrizzing have a negative impact on cracks because water penetrate inside the cracks, it freezes causing to the respective water to turn up the volume and as the result of these freezes action parts of asphalt will be dislocated and the crack width will become wider.
TRIB dataset description
In matter of image processing deep learning methods are used to solve tasks such as image classification, feature extraction, denoising, segmentation (Archana and Jeevaraj 2024). An excellent quality of datasets used in the for deep learning it consists in a large dataset of images. This dataset will have a direct impact on deep learning models in matter of robustness, generalization capabilities and performance.
To obtain a robust and predictive model in case of machine learning is important to use or to generate datasets which can avoid underfitting and overfitting.
Underfitting occurs in the process of training data due to fact that machine learning model is too basic, and it fails to capture the underlying pattern within the provided training dataset used (Rimal et al. 2024). In case of underfitting the machine learning model fails to establish key relationships and patterns and will not interpret correctly new and unseen data. A negative impact will be seen on the following impact metrics: precision, recall, and F1 score. These values will be significantly reduced.
Overfitting, it occurs mostly when machine learning model becomes overly attuned to the training data, is excessively complex or the model memorized the training dataset (Alamri 2024). To prevent overfitting are used augmentation techniques of the dataset such as vertical flipping or horizontal flipping (Hsieh et al. 2024). As underfitting, overfitting fails to generalize to new, unseen data. A negative impact will be seen on the following impact metrics: predictive accuracy begins to be reduced when new data are used.
TRIB crack dataset contains 137 high-resolution RGB (red, green blue) images captured with a professional camera. Each image has a size of 2160 × 2160 pixels and is offering real-world assessment scenarios. The images were captured by inspecting seven streets from Bucharest suitable to be used for crack detection using segmentation or object detection.
All the algorithms used in this paper were run using MATLAB 2023b simulation environment, utilizing an Intel(R) Core (TM) i5-6200U CPU @2.30 GHz 2.40 GHz, with a 64-bit operating system, x64 based processor, and Windows 10 Pro.
Due to fact that is not possible to run in a deep neural network (DNN) images large pixel is necessary to split all the images into small images with a size of 256 × 256 pixels.
To enhance splitting of all the dataset images where each image has a size of size of 2160 × 2160 pixels into images with a side of 256 × 256 pixels, Algorithm 1 was employed for this operation.

Algorithm 1 for TRIB crack dataset splitting
After performing Algorithm 1 in the output folder were generated a number of 1863 RGB images, each image having a size of 256 × 256 pixels. To make the images suitable to be used in the process of DNN for classification the dataset resulted was divided into 2 classes: one set contains images with cracks and the other set contains images without cracks.
The dataset of images contains 791 RGB images with cracks, each image having a size of 256 × 256 pixels.
The dataset of images contains 1072 RGB images without cracks, each image having a size of 256 × 256 pixels.
In order to reduce the chances of underfitting or overfitting when deep learning models are used on a dataset to recognize patterns, different types of image augmentation techniques are used on our TRIB crack dataset.
To enhance the augmentation process by applying 90-degree rotations, Algorithm 2 was utilized. Both datasets—one containing image with cracks and the other without cracks—were augmented using this algorithm.

Algorithm 2 for image augmentation technique by 90-degree rotation
In Fig. 5 is presented the effect on original images with cracks and without cracks using augmentation technique by rotation and can be classified as a geometrical transformation (Xu et al. 2023).

Image augmentation technique by rotation: a original image, b augmented image, c original image, d augmented image
Another technique for image augmentation is using jitter. Algorithm 3 was employed for this operation.

Algorithm 3 for image augmentation technique by jittering
As it can be seen in Fig. 6 in the original image is introduce gaussian noise and is classified as color image processing.

Image augmentation technique by jittering: a original image, b augmented image
Another technique for image augmentation is called CutMix. Algorithm 4 was employed for this operation.

Algorithm 4 for image augmentation technique using CutMix
As it can be seen in Fig. 7 from the original image part of the regions were cut out and replaced with a patch from another image. and is classified as non-instance-level (Yun et al. 2019).

Image augmentation technique using CutMix: a original image, b augmented image
Other types of image augmentation were used for TRIB crack dataset to generate new images to avoid underfitting or overfitting as follows:
-
Context DA (Contextual Data Augmentation) classified as instance level (Dvornik et al. 2018);
-
GrixMix classified as non-instance-level (Baek et al. 2021). This technique splits each image into a grid of smaller patches and then mixes patches from different images creating the resulting image.
Using the above-mentioned augmentation techniques on the divided images into 256 × 256 pixels from TRIB crack dataset of 11,228 RGB images categorized into two classes as follow: “with crack” and “without crack”. In Table 1 is shown the images obtained using augmentation technique.
Using different augmentation techniques (e.g., 90-degree rotation, jittering, CutMix) further enhance the dataset’s robustness, allowing the model trained on it to generalize well across different image sources, including those captured by lower-resolution devices.
Table 2 offers a comparison between similar datasets created by other authors within the field of crack detection. Beside Cracktree200 and CFD datasets TRIB crack dataset includes supplementary accessories which are part of the traffic infrastructure: manhole lids and sink hole lids.
Method description
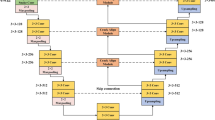
TRIB crack dataset was obtained using a digital camera model SLR Canon EOS 600D without using flashlights or zoom during the process of image capturing. The process of image capturing took place in daylight during different moments of the day, respectively in the morning, noon and evening making this to assure real-world scenarios. Other types of elements presented in the road infrastructure and captured in TRIB crack dataset to simulate enhance reliability and real-world conditions are traffic markings, manholes lids, sink holes lids, oil stains, shadows, leaf and trash. Taking into consideration all these elements presented in the road infrastructure from a city this dataset fulfilled all the necessary elements to be used by other researchers in the process of crack detection research. The workflow of the proposed method used is presented in Fig. 8.

Workflow of the proposed method
The digital camera specification used by the author to capture images which contain asphalt road cracks are presented in Table 3.
The digital camera presented in Fig. 9 was used to capture images which constitute the TRIB crack dataset being set to automatic capture at a height of 100 centimeters above the road surface.

Digital camera used for image capturing in our paper
Due to fact that deep learning (DL) can handle a large amount of data, it makes it suitable when it is used for image processing. During the process of compilation DL uses neural networks even are employed in artificial neural networks or convolutional neural networks (CNN) (Akram and Debnath 2020). CNN involves mathematical operation of convolution and ANN involves multiple layers.
CNN outperforms when is used in matter of image classification and is used intensively by researchers to solve complex tasks instead of classic Artificial Neural Networks (ANN).
In the proposed research we used for image classification on our TRIB crack dataset a CNN named DarkNet-19. The architecture of DarkNet-19 consists of 64 layers (convolution layers, pooling layers and fully connected layers).
This architecture (DarkNet-19) was specifically chosen for its balance of computational efficiency and classification accuracy, making it suitable for the diverse features present in the dataset.
To process an image in a CNN architecture it is necessary to extract the pixel values. The first layer who process the pixel values inside of a CNN architecture is convolutional layer. Thus, using a dot product between the input (pixel values = x) and the weights (Wk) will be generate k feature maps (hk) as is seen in Eq. 1:
Where: parameter bk is a parameter of the kernel k.
To evaluate the computing performance of DarkNet-19 deep neural network used the following performance indicators are used (El-khatib et al. 2023):
-
Accuracy— a commonly used metric to assess the overall performance of a road crack detection system. It measures the proportion of correctly classified images with cracks and images without cracks. However, it is important to consider other metrics to be used for road crack detection systems, due to fact that the metric accuracy may not provide a comprehensive evaluation. The metric for accuracy is computed using Eq. 2:
-
Sensitivity/Recall—Sensitivity, also known as recall or true positive rate, measures the proportion of actual road cracks correctly identified by the system. It focuses on minimizing road cracks false negatives (FN). The metric for sensitivity is computed using Eq. 3:
$$\:Recall=\frac{TP}{TP+FN}$$(3) -
Precision measures the proportion of actual road cracks correctly identified by the system. It focuses on minimizing road cracks false positives (FP). The metric sensitivity is computed using Eq. 4:
$$\:Precision=\frac{TP}{TP+FP}$$(4) -
F1 Score represents a metric that combines precision and recall. It considers both false positive (FP) crack detection and false negative (FN) crack detection and provides a balanced measure of a model’s performance. Higher F1 scores indicate better performance in terms of both precision and recall. The metric sensitivity is computed using Eq. 5:
The following parameters was set to train the network of the DarkNet-19 architecture to classify our TRIB crack dataset which consists in number of 11,228 images (with cracks and without cracks) with a size of 256 × 256 pixels: learning rate of 0.0001, “Adam” optimization method, MaxEpochs equal to 3. The result using these parameters is shown in Table 4. The image training parameter was set to 80%, testing parameter was set to 10% and validation parameter was set to 10%.
In Table 5 the confusion matrix in the case of MaxEpochs equal to 3 is presented.
Using the same parameters respectively: learning rate of 0.0001, “Adam” optimization method, but modifying the parameter MaxEpochs to 4 the accuracy metrics will increase as is shown in Table 6.
To compare the efficiency DarkNet-19 it was tested on TRIB crack dataset the transfer learning model DarkNet-53 (Rana and Bhushan et al. 2023). The architecture of DarkNet-53 consists of 53 convolutional layers but the max pool layer is missing. As in case of transfer leaning model DarkNet-19 the convolutional layer is extracting features preceded by batch normalization, leaky RELU layer, and each convolution operation.
Similar to DarkNet-19, DarkNet-53 utilizes this combination to ensure efficient feature extraction while leveraging transfer learning to adapt pre-trained weights for the specific task of crack detection.
These two appropriate architectures were selected in this manuscript to highlight how the accuracy metrics are affected if max pool layer is missing.
The evaluation metrics resulted in Table 7 were obtained using learning rate of 0.0001, “Adam” optimization method, parameter MaxEpochs equal to 3, training parameter was set to 80%, testing parameter was set to 10% and validation parameter was set to 10%.
In Table 8 the confusion matrix in the case of MaxEpochs equal to 3 is presented.
In Table 9 all the parameters used for Table 7 remained the same beside MaxEpochs which was set to 4.
To determine the severity of the cracks is necessary to determine the surface area of the cracks. This involves removing all the non-necessary information from the image. In this case the non-necessary information is represented by pixel who have a certain value. This operation can be made using image segmentation which plays an important role in the matter of image processing and patter recognition.
The segmentation algorithms can be categorized into three groups: graph-based, feature-based and region-based methods (Song et al. 2020). To measure the asphalt area with cracks is necessary to use a segmentation algorithm by splitting the image into two areas: no cracks area and area with cracks as is shown in Fig. 10. The pixels in the no cracks area are black and the pixels area with cracks area are white.

Pixel noise removal using mathematical morphology operators: a) original image, b) segmented crack image, c) noise removal
Due to fact that in the resulted images after segmentation algorithm was process is presented noise (as insolated white pixels) for an accuracy crack area detection is it necessary to remove this noise (Challa et al. 2023).
To remove this noise is used mathematical morphology operators (MMO) which are a technique form processing with geometrical structures based on lattice theory. The output images when segmentation algorithm deployed is completed are binary. Binary images constitute a specific lattice.
The are four types of MMO: dilation, erosion, opening and closing. To perform an MMO an image it is necessary to define a structural element (SE). A SE can take different sizes as shapes (line, square, circle and so on).
To used dilation operator on an image Eq. 6 is used:
To used erosion operator on an image Eq. 7 is used:
To used closing operator on an image Eq. 8 is used:
To used opening operator on an image Eq. ○ 9 is used:
Where:
A – original image with the size of M pixels and N pixels.
B – structuring element.
\(\:\oplus\:\) - dilation
\(\:\ominus\:\) - closing
To remove the noise (isolated white area pixels) resulted in the segmented image were used an algorithm constitute by 3 types of MMO: dilation (which enlarges the boundaries of detected regions, ensuring the connectivity of cracks in the segmented image), opening (which removes small noise elements that might have been introduced during dilation while preserving the shape and size of larger connected components) and erosion (which refines the segmentation by shrinking the boundaries of the detected regions to restore the accurate shape of the cracks). The MMO operators act in line: when the first operator completes the task is followed by the second and then the third. The resulted image is used for calculating the asphalt area affected by cracks.
To calculate the percentage of asphalt area covered with cracks from an image Eq. 10 is used:
In Fig. 11 is calculated the asphalt surface area affected by cracks from an image with a size of 256 × 256 pixels. The images are binary: the white zones represent the asphalt area with cracks area and the black area represent the asphalt area without cracks.

Determination of asphalt area affected by cracks
To determine the necessary BA16 material to bring the surface area to initial stage is mandatory to determine the pothole surface area. In Fig. 12 are measured the horizontal and vertical distance of the pothole.

Pothole measurement: a horizontal distance, b vertical distance
Due to fac that is technically impossible and not efficient to cut the asphalt surfaces affected by potholes in other shapes (as it can be seen in Fig. 12 the potholes have the shape of an ellipse) than square or rectangle, Eq. 11 is used to calculate the replacement area:
In Fig. 13 is highlighted with green diagonal lines the area where the asphalt reparations will be made.

Determination of replacement area affected by cracks
Next steps involve calculating the volume of BA16 material. As it can be seen in Fig. 1 the BA16 layer has a thickness of 4 centimeters (or 0.04 m). Using Eq. 12 we will obtain the weight of BA16 necessary to repair the pothole presented in the asphalt surface area:
Where:
\(\:{D}_{BA16}\) – represent the density of BA16 material which is 2250 kg per cubic meter.
Conclusions
This study presented the results of image classification for the TRIB crack dataset using two convolutional neural network architectures: DarkNet-19 and DarkNet-53. DarkNet-19 consists of 64 layers, while DarkNet-53 has 53 convolutional layers, excluding max-pooling layers. Various image augmentation techniques were employed to mitigate underfitting and overfitting during training. Segmentation and mathematical morphology operators were applied to process the images, facilitating accurate crack surface area calculations.
The performance evaluation demonstrated that the DarkNet-19 algorithm, with a learning rate of 0.0001, the “Adam” optimization method, and MaxEpochs set to 4, achieved improved metrics compared to MaxEpochs set to 3, with accuracy increasing from 93.55 to 94.01% and an F1 score from 92.05 to 93.96%. However, the increased accuracy also resulted in higher computational resource usage. Similarly, DarkNet-53 achieved high metrics with a learning rate of 0.0001 and MaxEpochs set to 3, with an accuracy of 95.17% and an F1 score of 94.98%. Adjusting MaxEpochs to 4 showed a slight increase in accuracy but a decrease in precision and recall, highlighting the trade-offs associated with parameter modifications.
The TRIB crack dataset, comprising real-world scenarios, offers a significant contribution to road crack detection research. Its diversity and high-quality annotations enable the development and evaluation of advanced algorithms for image classification and segmentation tasks. By integrating road condition assessment with surface crack analysis, the dataset paves the way for practical applications in road infrastructure monitoring and maintenance.
Future work should focus on enhancing decision-making frameworks to determine the necessity and urgency of road repairs based on detected cracks. For instance, integrating automated categorization of critical issues such as potholes, which pose risks like traffic disruptions, vehicle damage, and accidents, would significantly advance the practical applications of crack detection. Such developments could assist transportation authorities in prioritizing maintenance tasks and allocating resources efficiently.
Discussion
The TRIB crack dataset was captured with a high-resolution camera and has been developed with various preprocessing and augmentation techniques (e.g., 90-degree rotation, jittering, and CutMix) to enhance its robustness. These techniques simulate diverse imaging conditions, including variations in angle, lighting, and resolution, allowing models trained on this dataset to generalize effectively to different image sources, even those captured by lower-resolution devices.
While the dataset was collected from seven urban roads located in Bucharest, Romania, its design and augmentation steps aim to address challenges commonly encountered in road crack detection, such as varying surface textures, lighting conditions, and the presence of artifacts like shadows, oil stains, and leaves. It also included road accessories as manhole lids and sink hole lids. These characteristics suggest that models trained on the TRIB dataset can generalize to similar urban environments.
TRIB dataset provides a robust foundation for developing road crack detection algorithms and demonstrates potential for broader applicability.
Data availability
No datasets were generated or analysed during the current study.
References
Akram A, Debnath R (2020) An automated eye disease recognition system from visual content of facial image using machine learning techniques. Turk J Electr Eng Comput Sci 28(2):917–932
Alamri NM (2024) Reducing the overfitting in convolutional neural network using nature-inspired algorithm: a novel hybrid approach. Arab J Sci Eng 49:13099–13114. https://doi.org/10.1007/s13369-024-08998-4
Amhaz R, Chambon S, Idier J, Baltazart V (2014) A new minimal path selection algorithm for automatic crack detection on pavement images, In: 2014 IEEE International Conference on Image Processing (ICIP), IEEE, pp 788–792. https://doi.org/10.1109/ICIP.2014.7025158
Archana R, Jeevaraj PSE (2024) Deep learning models for digital image processing: a review. Artif Intell Rev 57:11. https://doi.org/10.1007/s10462-023-10631-z
Baek K, Bang D, Shim H (2021) Gridmix: strong regularization through local context mapping. Pattern Recognit 109:107594
Challa A, Danda S, Sagar BSD (2023) Binary Mathematical morphology. In: Daya Sagar BS, Cheng Q, McKinley J, Agterberg F (eds) Encyclopedia of Mathematical Geosciences. Springer, Cham. https://doi.org/10.1007/978-3-030-85040-1_53
Cui L, Qi Z, Chen Z, Meng F, Shi Y (2015) Pavement distress detection using random decision forests. pp 95–102. https://doi.org/10.1007/978-3-319-24474-7_14
Dvornik N, Mairal J, Schmid C (2018) Modeling visual context is key to augmenting object detection datasets, Proceedings of the European Conference on Computer Vision (ECCV), pp 364–380
El-khatib H, Ștefan A-M, Popescu D (2023) Performance improvement of Melanoma Detection using a Multi-network System based on decision Fusion. Appl Sci 13:10536. https://doi.org/10.3390/app131810536
Hsieh YA, Clark S, Yang Z et al (2024) Automated concrete pavement Slab Joint Detection using deep learning and 3D pavement surface images. Int J Pavement Res Technol 17:1112–1123. https://doi.org/10.1007/s42947-023-00290-2
Liu J, Gu J, Luo S (2022) Research on road crack detection based on machine vision. 2022 IEEE 6th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Beijing, China, pp 543–547. https://doi.org/10.1109/IAEAC54830.2022.9929645
Mandal V, Uong L, Adu-Gyamfi Y ( 2018) Automated road crack detection using deep convolutional neural networks. 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, pp 5212–5215. https://doi.org/10.1109/BigData.2018.8622327
Rana M, Bhushan M (2023) Classifying breast cancer using transfer learning models based on histopathological images. Neural Comput Applic 35:14243–14257. https://doi.org/10.1007/s00521-023-08484-2
Rimal Y, Sharma N, Alsadoon A (2024) The accuracy of machine learning models relies on hyperparameter tuning: student result classification using random forest, randomized search, grid search, bayesian, genetic, and optimal algorithms. Multimed Tools Appl 83:74349–74364. https://doi.org/10.1007/s11042-024-18426-2
Sabouri M, Sepidbar A (2023) SUT-Crack: a comprehensive dataset for pavement crack detection across all methods. Data Brief 51:109642. https://doi.org/10.1016/j.dib.2023.109642
Shi W, Yang H, Xie L et al (2024) A review of machine learning-based methods for predicting drug–target interactions. Health Inf Sci Syst 12:30. https://doi.org/10.1007/s13755-024-00287-6
Sihombing T, Aritonang R (2024) Identification of Road Pavement conditions in the Tanjung Balai City Road Section. IOP Conf Series: Earth Environ Sci 1321(012051). https://doi.org/10.1088/1755−1315/1321/1/012051
Song Y, Huang Z, Shen C, Shi H, Lange DA (2020) Deep learning-based automated image segmentation for concrete petrographic analysis. Cem Concr Res 135:1–13
Xu M, Yoon S, Fuentes A, Park DS (2023) A comprehensive survey of image augmentation techniques for deep learning. Pattern Recognit 137:0031–3203. https://doi.org/10.1016/j.patcog.2023.109347
Yun S, Han D, Oh SJ, Chun S, Choe J, Yoo Y (2019) Cutmix: regularization strategy to train strong classifiers with localizable features Proceedings of the IEEE/CVF international conference on computer vision, pp 6023–6032
Zhang L, Yang F, Daniel Zhang Y, Zhu YJ (2016) Road crack detection using deep convolutional neural network. In: 2016IEEE International Conference on Image Processing (ICIP), IEEE, pp 3708–3712. https://doi.org/10.1109/ICIP.2016.7533052
Zhao X, Wang L, Zhang Y et al (2024) A review of convolutional neural networks in computer vision. Artif Intell Rev 57:99. https://doi.org/10.1007/s10462-024-10721-6
Zou Q, Cao Y, Li Q, Mao Q, Wang S (2012) CrackTree: automatic crack detection from pavement images. Pattern Recognit Lett 33(3):227–238. https://doi.org/10.1016/j.patrec.2011.11.004
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Contributions
A.D. wrote the main manuscript text, prepared figures and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Communicated by Hassan Babaie
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abrudan, D. TRIB crack dataset: automatic recognition system for road cracks detection. Earth Sci Inform 18, 251 (2025). https://doi.org/10.1007/s12145-025-01763-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12145-025-01763-7