
Abstract
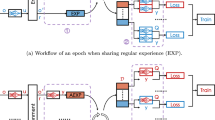
In transfer learning (TL) for multiagent reinforcement learning (MARL), most popular methods are based on action advising scheme, in which skilled agents directly transfer actions, i.e., explicit knowledge, to other agents. However, this scheme requires an inquiry-answer process, which quadratically increases the computational load as the number of agents increases. To enhance the scalability of TL for MARL when all the agents learn from scratch, we propose an experience sharing based memetic TL for MARL, called MeTL-ES. In the MeTL-ES, the agents actively share implicit memetic knowledge (experience), which avoids the inquiry-answer process and brings highly scalable and effective acceleration of learning. In particular, we firstly design an experience sharing scheme to share implicit meme based experience among the agents. Within this scheme, experience from the peers is collected and used to speed up the learning process. More importantly, this scheme frees the agents from actively asking for the states and policies of other agents, which enhances scalability. Secondly, an event-triggered scheme is designed to enable the agents to share the experiences at appropriate timings. Simulation studies show that, compared with the existing methods, the proposed MeTL-ES can more effectively enhance the learning speed of learning-from-scratch MARL systems. At the same time, we show that the communication cost and computational load of MeTL-ES increase linearly with the growth of the number of agents, indicating better scalability compared to the popular action advising based methods.












Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Anschel O, Baram N, Shimkin N (2017) Averaged-dqn: Variance reduction and stabilization for deep reinforcement learning. In: International conference on machine learning. PMLR, pp 176–185
Baliarsingh SK, Ding W, Vipsita S, Bakshi S (2019) A memetic algorithm using emperor penguin and social engineering optimization for medical data classification. Appl Soft Comput 85:105773
Barto AG, Sutton RS, Watkins CJ (1989) Learning and sequential decision making. In: Learning and computational neuroscience. Citeseer, pp 539–602
Chen X, Ong YS, Lim MH, Tan KC (2011) A multi-facet survey on memetic computation. IEEE Trans Evolut Comput 15(5):591–607. https://doi.org/10.1109/tevc.2011.2132725
Chernova S, Veloso M (2009) Interactive policy learning through confidence-based autonomy. J Artif Intell Res 34:1–25. https://doi.org/10.1613/jair.2584
Chugh R (2015) Do australian universities encourage tacit knowledge transfer?. In: Proceedings of the international joint conference on knowledge discovery, knowledge engineering and knowledge management. pp 128–135
Da Silva FL, Costa AHR (2019) A survey on transfer learning for multiagent reinforcement learning systems. J Artif Intell Res 64:645–703
Da Silva FL, Glatt R, Costa AHR (2017) Simultaneously learning and advising in multiagent reinforcement learning. In: Proceedings of the 16th conference on autonomous agents and multiagent systems. pp 1100–1108
Da Silva FL, Glatt R, Costa AHR (2019) Moo-mdp: An object-oriented representation for cooperative multiagent reinforcement learning. IEEE Trans Cybern 49(2):567–579. https://doi.org/10.1109/tcyb.2017.2781130
Dawkins R (1976) The selfish gene. Oxford University Press, Oxford, U.K
Gupta A, Ong YS (2018) Memetic computation: the mainspring of knowledge transfer in a data-driven optimization era, vol 21. Springer, Berlin
Gupta A, Ong YS (2019) The memetic automaton. In: Memetic computation. Springer, pp 47–61
Hou Y, Feng L, Ong Y (2016) Creating human-like non-player game characters using a Memetic Multi-Agent System. In: 2016 International joint conference on neural networks (IJCNN), pp 177–184. https://doi.org/10.1109/IJCNN.2016.7727196
Hou Y, Ong YS, Feng L, Zurada JM (2017) An evolutionary transfer reinforcement learning framework for multiagent systems. IEEE Trans Evolut Comput 21(4):601–615. https://doi.org/10.1109/tevc.2017.2664665
Hou Y, Ong YS, Tang J, Zeng Y (2019) Evolutionary Multiagent Transfer Learning With Model-Based Opponent Behavior Prediction. IEEE Trans Syst Man Cybern Syst pp. 1–15
Hou Y, Zeng Y, Ong YS (2016) A Memetic Multi-Agent Demonstration Learning Approach with Behavior Prediction. In: Proceedings of the 2016 international conference on autonomous agents & multiagent systems. International Foundation for Autonomous Agents and Multiagent Systems, Singapore, Singapore, pp 539–547
Mnih V, Kavukcuoglu K, Silver D et al (2015) Human-level control through deep reinforcement learning. Nature 518(7540):529–533
Pan SJ, Yang Q (2010) A survey on transfer learning. IEEE T Knowl Data En 22(10):1345–1359. https://doi.org/10.1109/tkde.2009.191
Qu X, Ong YS, Hou Y, Shen X (2019) Memetic evolution strategy for reinforcement learning. In: 2019 IEEE congress on evolutionary computation (CEC). IEEE, pp 1922–1928
Qu X, Zhang R, Liu B, Li H (2017) An improved tlbo based memetic algorithm for aerodynamic shape optimization. Eng Appl Artif Intel 57:1–15. https://doi.org/10.1016/j.engappai.2016.10.009
Reagans R, Argote L, Brooks D (2005) Individual experience and experience working together: Predicting learning rates from knowing who knows what and knowing how to work together. Manag Sci 51(6):869–881. https://doi.org/10.1287/mnsc.1050.0366
Sasaki T, Biro D (2017) Cumulative culture can emerge from collective intelligence in animal groups. Nat Commun 8:15049
Shapley LS (1953) Stochastic games. P Natl Acad Sci 39(10):1095–1100
Sutton RS, Barto AG (2018) Reinforcement learning: an introduction. The MIT Press, Cambridge
Tan AH, Lu N, Xiao D (2008) Integrating temporal difference methods and self-organizing neural networks for reinforcement learning with delayed evaluative feedback. IEEE T Neural Netw 19(2):230–244
Tan M (1993) Multi-agent reinforcement learning: Independent vs. cooperative agents. In: Proceedings of the tenth international conference on machine learning. pp 330–337
Taylor A, Dusparic I, Gueriau M, Clarke S (2019) Parallel Transfer Learning in Multi-Agent Systems: What, when and how to transfer? In: International Joint Conference on Neural Networks (IJCNN), pp 1–8. https://doi.org/10.1109/ijcnn.2019.8851784
Torrey L, Taylor M (2013) Teaching on a budget: Agents advising agents in reinforcement learning. In: Proceedings of the 2013 international conference on Autonomous agents and multi-agent systems. pp 1053–1060
Van Hasselt H, Guez A, Silver D (2016) Deep reinforcement learning with double Q-Learning. In: 30th AAAI conference on artificial intelligence. AAAI 2016, pp 2094–2100
Wang H, Wang X, Hu X, Zhang X, Gu M (2016) A multi-agent reinforcement learning approach to dynamic service composition. Inform Sci 363:96–119. https://doi.org/10.1016/j.ins.2016.05.002
Watkins CJCH, Dayan P (1992) Q-learning. Mach Learn 8(3–4):279–292
Yasuda T, Ohkura K (2018) Collective behavior acquisition of real robotic swarms using deep reinforcement learning. In: 2018 Second IEEE international conference on robotic computing (IRC). pp 179–180. https://doi.org/10.1109/irc.2018.00038
Zeng Y, Chen X, Ong YS, Tang J, Xiang Y (2016) Structured memetic automation for online human-like social behavior learning. IEEE Trans Evolut Comput 21(1):102–115
Zimmer M, Viappiani P, Weng P (2014) Teacher-Student Framework: A Reinforcement Learning Approach. https://matthieu-zimmer.net/publications/ARMS2014.pdf
Acknowledgements
This work was funded by the National Natural Science Foundation of China under Grants 62076203 and 61473233.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, T., Peng, X., Jin, Y. et al. Experience Sharing Based Memetic Transfer Learning for Multiagent Reinforcement Learning. Memetic Comp. 14, 3–17 (2022). https://doi.org/10.1007/s12293-021-00339-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12293-021-00339-4