
Abstract
In this paper, we show that a robotic system can learn online to recognize facial expressions without having a teaching signal associating a facial expression with a given abstract label (e.g., ‘sadness’, ‘happiness’). Moreover, we show that recognizing a face from a non-face can be accomplished autonomously if we imagine that learning to recognize a face occurs after learning to recognize a facial expression, and not the opposite, as it is classically considered. In these experiments, the robot is considered as a baby because we want to understand how the baby can develop some abilities autonomously. We model, test and analyze cognitive abilities through robotic experiments. Our starting point was a mathematical model showing that, if the baby uses a sensory motor architecture for the recognition of a facial expression, then the parents must imitate the baby’s facial expression to allow the online learning. Here, a first series of robotic experiments shows that a simple neural network model can control a robot head and can learn online to recognize the facial expressions of the human partner if he/she imitates the robot’s prototypical facial expressions (the system is not using a model of the face nor a framing system). A second architecture using the rhythm of the interaction first allows a robust learning of the facial expressions without face tracking and next performs the learning involved in face recognition. Our more striking conclusion is that, for infants, learning to recognize a face could be more complex than recognizing a facial expression. Consequently, we emphasize the importance of the emotional resonance as a mechanism to ensure the dynamical coupling between individuals, allowing the learning of increasingly complex tasks.
















Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Notes
The symbol grounding problem is related to the problem of how symbols (words) get their meanings (without a human expert providing the knowledge).
Measure of the object conductivity: \(R = 1 K\Omega \) for positive objects, \(R = 0\,\mathrm{K}\Omega \) for negative objects and \(R > 10\,\mathrm{K}\Omega \) for neutral objects (usual objects) with no hidden resistor.
To be precise, this scenario can involve only low-level resonance and perhaps sympathy because, according to Decety and Meyer, empathy is “a sense of similarity in the feelings experienced by the self and the other, without confusion between the two individuals” [8].
The standard PAL camera provides a \(720 \times 580\) color image used only for grey levels.
Heaviside function:
$$\begin{aligned} H_\theta (x) = \left\{ \begin{array}{ll} 1 &{}\quad \text{ if } \theta <x\\ 0 &{}\quad \text{ otherwise } \end{array} \right. \end{aligned}$$Fig. 5 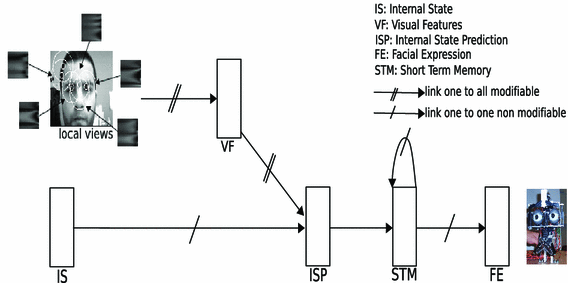
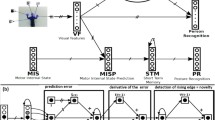
The architecture for facial expression recognition and imitation. The visual processing allows for the sequential extraction of the local views. The \(internal\) \(state\) \(prediction\) (\(ISP\) group) learns the association between the local views and the internal state (\(IS\) group).
Kronecker function:
$$\begin{aligned} {\delta _j}^{k} = \left\{ \begin{array}{ll} 1 &{}\quad \text{ if } j=k\\ 0 &{}\quad \text{ otherwise } \end{array} \right. \end{aligned}$$Since the human partner is supposed to be imitating the robot head, the label of the robot facial expression should be the correct label of the image. We will see later it is not always the case because of the human reaction time and because of some misrecognition from the human partners.
Problems can occur with pale faces and dark airs since they can induce a lot of focus points with a high value around the face reducing the probability to select focus points really on the face. One solution is to increase the number of selected focus points to be sure to take focus points on the face but then the exploration time increases and the frame rate is reduced. In future works, we plan to use this simple solution as a bootstrap mechanism for a spatial attentional mechanism to focus on the face in order next to come back to a fast image analysis in the selected area.
The weak point of this technique is that the DOG size must fit the resolution of the objects to analyze. With a standard PAL camera, this constraint is clearly not a problem because there is not much choice if the size of the face must be large enough to allow a correct recognition (for an HD camera, a multi-scale approach would be necessary). For more general applications, a multi-scale decomposition could be performed (for example using 3 scales).

References
Abboud B, Davoine F, Dang M (2004) Facial expression recognition and synthesis based on an appearance model. Signal Process Image Commun 19:723–740
Andry P, Gaussier P, Moga S, Banquet JP, Nadel J (2001) Learning and communication in imitation: an autonomous robot perspective. IEEE Trans Syst Man Cybern Part A 31(5):431–444
Asada M, Hosoda K, Kuniyoshi Y, Ishiguro H, Inui T, Yoshikawa Y, Ogino M, Yoshida C (2009) Cognitive developmental robotics: a survey. Auton Mental Dev IEEE Trans 1(1):12–34
Banquet JP, Gaussier P, Dreher JC, Joulain C, Revel A, Günther W (1997) Space-time, order, and hierarchy in fronto-hippocampal system: a neural basis of personality. In: Matthews Gerald (ed) Cognit Sci Perspect Personal Emot, vol 124. North Holland, Amsterdam, pp 123–189
Boucenna S, Gaussier P, Hafemeister L (2013) Development of first social referencing skills: emotional interaction as a way to regulate robot behavior. IEEE Trans Autonom Mental Dev 6(1):42–55
Boucenna S, Gaussier P, Hafemeister L, Bard K (2010) Autonomous development of social referencing skills. In: From Animals to animats 11, volume 6226 of Lecture Notes in Computer Science, pp 628–638
Breazeal C, Buchsbaum D, Gray J, Gatenby D, Blumberg B (2005) Learning from and about others: towards using imitation to bootstrap the social understanding of others by robots. Artif Life 11(1–2):31–62
Decety J (2011) Dissecting the neural mechanisms mediating empathy. Emot Rev 3:92–108
Devouche E, Gratier M (2001) Microanalyse du rythme dans les échanges vocaux et gestuels entre la mère et son bébé de 10 semaines. Devenir 13:55–82
Ekman P, Friesen WV (1978) Facial action coding system: a technique for the measurement of facial movement. Consulting Psychologists Press, Palo Alto, CA
Ekman P, Friesen WV, Ellsworth P (1972) Emotion in the human face: guide-lines for research and an integration of findings. Pergamon Press, New York
Franco L, Treves A (2001) A neural network facial expression recognition system using unsupervised local processing. 2nd international symposium on image and signal processing and analysis. Cogn Neurosci 2:628–632
Gaussier P (2001) Toward a cognitive system algebra: a perception/action perspective. In: European workshop on learning robots (EWRL), pp 88–100
Gaussier P, Boucenna S, Nadel J (2007) Emotional interactions as a way to structure learning. epirob, pp 193–194
Gaussier P, Moga S, Quoy M, Banquet JP (1998) From perception–action loops to imitation processes: a bottom-up approach of learning by imitation. Appl Artif Intell 12(7–8):701–727
Gaussier P, Prepin K, Nadel J (2004) Toward a cognitive system algebra: application to facial expression learning and imitation. In Iida F, Pfeiter R, Steels L, Kuniyoshi Y (Eds) Embodied artificial intelligence. Published by LNCS/LNAI series of Springer, pp 243–258
Gergely G, Watson JS (1999) Early socio-emotional development: contingency perception and the social-biofeedback model. In: Rochat P (Ed) Early social cognition: understanding others in the first months of life. Erlbaum, Mahwah, NJ, pp 101–136
Giovannangeli C, Gaussier P (2010) Interactive teaching for vision-based mobile robots: a sensory-motor approach. IEEE Trans Syst Man Cybern Part A Syst Humans. 40(1):13–28
Giovannangeli C, Gaussier P, Banquet J-P (2006 jun) Robustness of visual place cells in dynamic indoor and outdoor environment. Int J Adv Robot Syst 3(2):115–124
Grossberg S (1987) Competitive learning: from interactive activation to adaptive resonance. Cogn Sci 11:23–63
Gunes H, Schuller B, Pantic M, Cowie R (2011) Emotion representation, analysis and synthesis in continuous space: a survey. In: 2011 IEEE international conference on automatic face gesture recognition and workshops (FG 2011), pp 827–834
Harnad S (1990) The symbol grounding problem. Phys D 42:335–346
Hasson C, Boucenna S, Gaussier P, Hafemeister L (2010) Using emotional interactions for visual navigation task learning. In: International conference on Kansei engineering and emotion research KEER2010, pp 1578–1587
Hsu RL, Abdel-Mottaleb M, Jain AK (2002) Face detection in color images. Pattern Anal Mach Intell IEEE Trans 24:696–706
Izard C (1971) The face of emotion. Appleton Century Crofts, New Jersey
Jenkis JM, Oatley K, Stein NL (1998) Human emotions, chapter the communicative theory of emotions. Blackwell, New Jersey
Kanungo T, Mount DM, Netanyahu NS, Piatko CD, Silverman R, Wu AY (2002) An efficient k-means clustering algorithm: analysis and implementation. IEEE Trans Pattern Anal Mach Intell 24:881–892
Kohonen T (1989) Self-organization and associative memory, 3rd edn. Springer, Berlin
LeDoux JE (1996) The emotional brain. Simon & Schuster, New York
Lee JK, Breazeal C (2010) Human social response toward humanoid robot’s head and facial features. In: CHI ’10 extended abstracts on human factors in computing systems, CHI EA ’10, pp 4237–4242, New York, NY, USA, 2010. ACM
Liang D, Yang J, Zheng Z, Chang Y (2005) A facial expression recognition system based on supervised locally linear embedding. Pattern Recogn Lett 26:2374–2389
Littlewort G, Bartlett MS, Fasel I, Kanda T, Ishiguro H, Movellan JR (2004) Towards social robots: automatic evaluation of human–robot interaction by face detection and expression classification, vol 16. MIT Press, Cambridge, pp 1563–1570
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis 2:91–110
Lungarella M, Metta G, Pfeifer R, Sandini G (2003) Developmental robotics: a survey. Connect Sci 15(4):151–190
Maillard M, Gapenne O, Hafemeister L, Gaussier Ph (sep 2005) Perception as a dynamical sensori-motor attraction basin. In: Capcarrere et al (eds) Advances in artificial life (8th European conference, ECAL), volume LNAI 3630 of Lecture Note in Artificial Intelligence. Springer, Berlin, pp 37–46
Masahiro M (1970) The uncanny valey. Energy 7:33–35
Mataruna HR, Varela FJ (1980) Autopoiesis and cognition: the realization of the living. Reidel, Dordrecht
Muir D, Nadel J (1998) Infant social perception. In: Slater A (ed) Perceptual development. Psychology Press, Hove, pp 247–285
Murray L, Trevarthen C (1985) Emotional regulation of interaction between two-month-olds and their mother’s. In: Norwood NJ (ed) Social perception in infants. Ablex, New York, pp 177–197
Nadel J, Simon M, Canet P, Soussignan P, Blancard P, Canamero L, Gaussier P (2006) Human responses to an expressive robot. In: Epirob 06
Nadel J, Simon M, Canet P, Soussignan R, Blanchard P, Canamero L, Gaussier P (2006) Human responses to an expressive robot. In: Epirob 06
Nicolaou MA, Gunes H, Pantic M (2012) Output-associative rvm regression for dimensional and continuous emotion prediction. Image Vis Comput 30(3):186–196
Papez JW (1937) A proposed mechanism of emotion. Arch Neurol Psychiatry 38(4):725–743
Plutchick R (1980) A general psychoevolutionary theory of emotion. In: Plutchik R, Kellerman H (eds) Emotion: theory, research and experience, vol 1. Theories of emotion. Academic press, New York, pp 3–31
Rowley HA, Baluja S, Kanade T (1998) Neural network-based face detection. IEEE Trans Pattern Anal Mach Intell 20:23–38
Rumelhart DE, Zipser D (1985) Feature discovery by competitive learning. Cogn Sci 9:75–112
Sénéchal T, Rapp V, Salam H, Seguier R, Bailly K, Prevost L (2012) Facial action recognition combining heterogeneous features via multi-kernel learning. IEEE Trans Syst Man Cybern Part B 42(4):993–1005
Thirioux B, Mercier MR, Jorland G, Berthoz A, Blanke O (2010) Mental imagery of self-location during spontaneous and active self other interactions: an electrical neuroimaging study. J Neurosci 30(21):7202–7214
Thorpe S, Fize D, Marlot C (1996) Speed of processing in the human visual system. Nature 381:520–522
Viola P, Jones M (2004) Robust real-time face detection. Int J Comput Vis 57:137–154
Widrow B, Hoff M (1960) Adaptive switching circuits. In: IRE WESCON, New York. Convention Record, pp 96–104
Wiskott L (1991) Phantom faces for face analysis. Pattern Recogn 30:191–586
Wu T, Butko NJ, Ruvulo P, Bartlett MS, Movellan JR (2009) Learning to make facial expressions. Int Conf Dev Learn 0:1–6
Yu J, Bhanu B (2006) Evolutionary feature synthesis for facial expression recognition. Pattern Recogn Lett 27(11):1289–1298
Zeng Z, Pantic M, Roisman GI, Huang TS (2009) A survey of affect recognition methods: audio, visual, and spontaneous expressions. Pattern Anal Mach Intell IEEE Trans 31(1):39–58
Acknowledgments
The authors thank J. Nadel, M. Simon and R. Soussignan for their help to calibrate the robot facial expressions and P. Canet for the design of the robot head. Many thanks also to L. Canamero for the interesting discussions on emotion modeling. This study is part of the European project “FEELIX Growing” IST-045169 and also the French Region Ile de France (DIGITEO project) and ANR INTERACT. P. Gaussier thanks also the Institut Unisersitaire de France for its support.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Visual Processing
The visual attention is controlled by a reflex mechanism that allows the robot to focus its gaze on potentially interesting regions. The focus points are the result of a local competition performed on the convolution between a DOG (difference of Gaussians) filter and the norm of the gradient of the input image (we use the same architecture for place and object recognition [19, 35]). This process allows the system to focus more on the corners and ends of the lines in the image (e.g., eyebrows, corners of the lips). The main advantages of this process over the SIFT (Scale Invariant Feature Transform) [33] method are its computational speed and a smaller number of extracted focus points. The intensity of the focus points is directly linked to their level of interest. Through a recurrent inhibition of the already selected points, a sequence of exploration is defined (a scan path). A short-term memory allows maintaining the inhibition of the already explored points. This memory is reset after each new image acquisition.Footnote 9
To reduce the computational load (and to simplify the recognition), the image is sub-sampled from \(720 \times 580\) to \(256 \times 192\) pixels. For each focus point in the image, a local view centered on the focus point is extracted: either a log-polar transform or Gabor filters are applied (Fig. 18) to obtain an input image or a vector that is more robust to the rotations and distance variations. In our case, the log-polar transform has a radius of 20 pixels and projects to a \(32 \times 32\) input image. The Gabor filtering is used to extract the mean and the standard deviation for the convolution of the 24 Gabor filters (see “Appendix”). Hence, the input vector obtained from the Gabor filter has only 48 components. It is a smaller vector than the result of the log-polar, which transform induces an a priori better generalization but also has a lower discrimination capability (Figs. 17, 19, 20, 21).

Visual processing: this visual system is based on a sequential exploration of the image focus points. A gradient extraction is performed on the input image (\(256 \times 192\) pixels). A convolution with a Difference Of Gaussian (DOG) provides the focus points. Last, the local views are extracted around each focus point

Visual features: a the local log-polar transform increases the robustness of the extracted local views to small rotations and scale variations (a log-polar transform centered on the focus point is performed to obtain an image that is more robust to small rotations and distance variations. Its radius is 20 pixels). b Gabor filters are applied to obtain a signature that is more robust than a log-polar transform (the Gabor filters are \(60 \times 60\)); the features extracted for each convolution with a Gabor filter are the mean and the standard deviation

A Gabor filter with these parameters \(\sigma =8, \gamma =3\), and \(\theta =\pi /3\)

Gabor filters for different frequencies and orientations

Result of the convolution with 24 Gabor filters (different frequencies and orientations)
1.2 Gabor Filters
A Gabor filter has the following equation:
1.3 Model for the Rhythm Prediction
The neural network uses three groups of neurons. The Derivation Group (\(DG\)) receives the input signal, and the Temporal Group (\(TG\)) is a battery of neurons (15 neurons) with different temporal activities. The Prediction Group (\(PG\)) learns the conditioning between \(DG\) (the present) and \(TG\) (the past) information. In this model (Fig. 13), a \(PG\) neuron learns and also predicts the delay between two events from \(DG\). A \(DG\) activation sets to zero the \(TG\) neurons because of the links between \(DG\) and \(TG\). The neuronal activity (\(DG\)) involves instantaneous modifications in the weights between \(PG\) and \(TG\). After each reset (set to zero) by \(DG\), the \(TG\) neurons have the following activity:
\(l\) corresponds to the cell subscript, \(m\) is a time constant, \(\sigma \) is the standard deviation, and \(t\) is the time. The \(TG\) activity presents an activity trace \(DG\) (of the past). \(PG\) receives the \(PG\) and \(TG\) links, and the \(TG\) information corresponds to the elapsed time since the last event, whereas the \(DG\) information corresponds to the instant of the appearance of a new event. \(PG\) sums the \(TG\) and \(DG\) inputs with the following equation:
\(Act^{TG}_{l}\) is the \(l\) cells activity of \(TG, W_{pg}^{tg(l)}\) are the weight values between \(TG\) and \(PG, Act^{DG}\) is the \(DG\) neuron activity and \(W_{pg}\) is the weight value between \(DG\) and \(PG\). The \(PG\) activation is triggered by the maximal value detection of its potential (the maximal value is equal to the potential’s derivative when it is equal to zero):
Finally, only the \(W_{PG}^{TG}\) are learned, and we perform a one-shot learning process. The learning rule is the following:
Thereby, the \(PG\) is activated if and only if the \(TG\) cells’ activity sum is equal to that of learning.
Rights and permissions
About this article

Cite this article
Boucenna, S., Gaussier, P., Andry, P. et al. A Robot Learns the Facial Expressions Recognition and Face/Non-face Discrimination Through an Imitation Game. Int J of Soc Robotics 6, 633–652 (2014). https://doi.org/10.1007/s12369-014-0245-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12369-014-0245-z