
Abstract
In real-world applications, robots should adapt to users and environments; however, users may not know how to teach new tasks to a robot. We studied whether participants without any experience in teaching a robot would become more proficient robot teachers through repeated kinesthetic human–robot teaching interactions. An experiment was conducted with twenty-eight participants who were asked to kinesthetically teach a humanoid robot different cleaning tasks in five repeated sessions, each session including four tasks. Throughout the sessions, participants’ gaze patterns, methods of manipulating the robot’s arm, their perceived workload, and some physical properties of the demonstrated actions were measured. Our data analyses revealed a diversity in non-experts’ human–robot teaching styles in repeated interactions. Three clusters of human teachers were identified based on participants’ performance in providing the demonstrations. The majority of participants significantly improved their success and speed of kinesthetic demonstrations by performing multiple rounds of teaching the robot. Overall, participants gazed less often at the robot’s hand and perceived less effort over repeated sessions. Our findings highlight how non-experts adapt to robot teaching by being exposed repeatedly to human–robot teaching tasks, without any formal training or external intervention, and we identify the characteristics of successful and improving human teachers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Social robots are designed to achieve goals in diverse applications such as education, healthcare, entertainment, and collaborative tasks, and may one day support humans in their daily lives [14]. However, it is still challenging to use robots in real-world settings, such as in a home environment [36], because habits, needs, and preferences of robot users, as well as environmental factors (e.g., lighting, layout of the homes, etc.) vary and may even change over time. Without the ability to adapt to new environments and different individuals and their differing and changing needs, a robot cannot fulfill its purpose when it has to rely only on its pre-programmed capabilities. To address this problem, one solution is teaching robots new skills [7]. Several methods for robot learning have been developed to date, most notably imitation learning [9, 55] and learning from demonstration [7], which reduce the need of robot teachers to possess specialized technical knowledge. Learning from demonstration techniques generally attempt to make the teaching process as natural as possible and, therefore, enable even non-experts to teach robots to use them more effectively in real-life environments [50]. Kinesthetic teaching, a technique whereby a human physically guides a robot through a task, e.g., by grasping onto it and moving its arms, is one example of these more natural techniques of teaching a robot [17].
Even though these techniques for teaching robots are helpful in making robots accessible to everyone, many people who can potentially benefit from the support of social robots may have little or no knowledge and experience of how to program robots to perform new tasks, or how to tailor them to new environments. In realistic settings, users who are not familiar with how to teach tasks to a robot may face various challenges, such as presenting non-smooth and inefficient trajectories [51] and failing to provide sufficient sub-task abstraction [26], while teaching the robot (details will be discussed in Sect. 2.1). Thus, a variety of strategies have been proposed and tested to improve how non-expert humans teach robots, including real-time generation of teaching guidance by the robot [16], or providing human teachers with instructional materials [15]. Still, it may be difficult to easily access instructions on robot teaching. Novice users may find themselves in situations where the only available option to learn how to instruct a robot is simply exploring robot teaching on their own, without any additional instructional tools.
Considering a scenario that might happen in the real world, in this work, we study whether/how inexperienced participants who had never taught a task to a robot can adapt to the kinesthetic teaching of a robot by gradually gaining robot teaching experience. Unlike previous work, participants in our study are not formally instructed on how to perform the teaching or how to refine their demonstrations. Rather, over five sessions, they kinesthetically teach a humanoid robot multiple tasks through unsupervised interactions, i.e., without the presence of an experimenter, which might otherwise have influenced the results [25], and without being given any detailed feedback on their performance. In each session, the robot first provides basic verbal explanations of the teaching tasks to the participants, asking them to grasp onto its arm and show the robot how it can carry out four cleaning tasks. During the teaching process, joint positions of the robot’s arm, the gaze direction of participants, and videos of them teaching the robot are recorded, along with questionnaires asking participants to self-reflect on the workload of each session.
Overall, there was a significant increase in the speed of teaching and in the success of demonstrations for a majority of participants as they gained more experience in kinesthetically teaching the robot. These findings, derived from a preliminary analysis, were previously published in [6]. The present paper significantly extends this work. Here, we looked deeper at the teaching performance of participants individually and found that non-expert teachers could be divided into three clusters: high-achievers, improving, and low-achievers. Teaching performance and behavioural characteristics showed unique patterns for each cluster in our dataset. Taking into account different aspects of human–robot teaching, we observed significant shifts in participants’ gaze patterns and their behavioural characteristics. For instance, during teaching, participants overall spent less time looking at the robot’s hand and, those who improved their success, used both hands more often after demonstrating more tasks to the robot. According to workload measures, it was significantly less effort for participants to teach the robot in later sessions overall.
To the best of our knowledge, there has been no previous study that investigated potential changes in the behaviour of human teachers for robots over time when providing multiple kinesthetic task demonstrations without any external support. Our investigation answers the questions of whether or not inexperienced and unsupervised human teachers can gradually become more proficient robot teachers through repeated teaching interactions with humanoid robots, as well as how this might happen, in terms of the physical properties of movements and behaviours of the human teachers.
This study contributes to this long-term research direction reporting on some unique characteristics of high-achievers, low-achievers, and improving teachers. If a more advanced future robot could, by itself, capture the behavioural data that is analyzed in this work (discussed in Sect. 6.5.3), then it could use those characteristics to identify skilful human teachers (i.e., high-achievers) to achieve better human–robot teaching outcomes (discussed in Sect. 6.5.4). More generally, our scientific quest is to find an answer to the question of ‘who to imitate’ from a robot’s point of view [20], to fully utilize imitation learning for robots. This is to enable robots to distinguish between different teachers, and to identify and choose the most effective teachers when several teachers are available (e.g., in a home setting). To do so, some metrics for evaluating the teachers should be established first. Based on those metrics, a robot may then determine who to imitate.
2 Related Work
In this study, kinesthetic teaching, defined by Billard et al. as a technique “where the robot is physically guided through the task by the human” [10], is used as the method of robot teaching. Among major robot teaching interfaces, including remotely recording human motions, tele-operation of a robot, and teaching through having a conversation with it, kinesthetic teaching simplifies teaching by allowing the user to demonstrate a skill in a robot’s own environment, and through its own capabilities [10]. Other advantages of kinesthetic teaching, e.g., speed of demonstrations, high sense of control, and ease of use, are highlighted in [18, 23, 30, 50] (also see [1] for a review of different methods for teaching robots).
The remainder of this section first discusses potential issues related to robot teaching by demonstrations for human teachers who are not familiar with how to teach tasks to a robot. We review different approaches proposed in the literature on how to improve the performance of non-expert users when teaching robots. Following that, a brief review of studies concerning the behaviours of human teachers while teaching robots is presented. We conclude this section by highlighting how the present work is supported by and adds to the reviewed literature.
2.1 Non-expert Humans Teaching Robots
As noted earlier, human demonstrations for teaching robots, particularly those provided by non-experts, are not always optimal. There are several possible causes of sub-optimal performance in teaching robots by demonstration. To begin with, non-experts may exhibit unnecessary, superfluous actions that do not contribute to achieving the ultimate goal of the task when providing demonstrations to a robot [33]. Such actions, if learned, may lead to over-imitation (see [31] for a review). Second, incorrect or unsuccessful teaching attempts may happen that could impact the effectiveness of the demonstrations [33]. As a side note, a system proposed by Grollman and Billard can use those failed demonstrations to determine what went wrong and to avoid repeating the teacher’s mistake [27]. Moreover, there may be unmotivated actions in the demonstration that cannot be learned by the robot due to the lack of sensors for recording relevant data [33]. Lastly, a demonstrated trajectory might not be safe for the robot, e.g., it could cause self-collisions (i.e., different parts of the robot colliding with each other during the demonstration), or the trajectory could contain singularity points (e.g., when a few links of a robotic arm are aligned so that the robot is unable to move any further) [23]. Another example of an unsafe demonstration is applying too much pressure when holding or moving robot parts that might harm the robot [23].
To date, different strategies have been proposed and employed to help human teachers generate more effective demonstrations when teaching robots. Cakmak and Takayama have experimented with a set of instructional materials to assist participants in teaching a PR2 robot to fold a towel by demonstration, using a learning framework based on dialogues [15]. Three conditions were tested: providing (1) a user manual containing the voice commands the system was capable of working with, and, in addition to the user manual, either (2) a written tutorial instructing how to teach an example task to the robot step-by-step, or (3) an instructional video showing another person teaching the robot an example task. Providing novice users with guidance through video was found to be the most effective method. The two other conditions were not as successful, mainly because participants were unlikely to read the user manual entirely, and the tutorial was unreliable due to the high degree of uncertainty as a result of speech recognition errors in the teaching process. More recent discussions of this topic can be found in [26, 42].
Focusing on the kinesthetic teaching of a robotic arm, Sakr et al. tested three training methods intended to improve non-expert human demonstrations: (1) Discovery method, in which participants could learn to teach the robot through trial-and-error and evaluating their previous demonstrations, (2) Observational method, when participants watched an expert teaching the robot, and (3) Kinesthetic method, which involved participants holding the robot’s gripper passively while a trajectory taught by an expert is being performed by the robot [51]. By comparing the performance of participants teaching a robotic arm how to press a few buttons placed in holes, prior to and immediately after training, results showed that all three tested training methods improved human teachers’ performance. In particular, the observational method was the most effective approach for reducing the teaching time [51]. In another study, Orendt et al evaluated a kinesthetic teaching system in terms of ease of use and robustness in task completion [46]. They compared brief verbal instructions with a graphical tutorial when instructing two groups of users consisting of both robotics experts and non-experts. These two types of instruction, however, did not affect teaching success.
Some computational approaches have also been used to improve humans’ teaching of robots and facilitate their learning from non-expert users [16, 33, 37, 62]. For instance, Cakmak and Thomaz developed a system that enabled a robot to give real-time instructions to participants when teaching it a classification task, and to guide the participants toward providing more effective examples [16]. The framework developed by Schrum et al. allowed a driving simulator to produce feedback by the system to improve the quality of sub-optimal human teachers’ demonstrations [56]. Several researchers have also noted the importance of social learning, i.e., learning through social interaction, for robots [13, 43]. By including social and communication cues that convey a robot’s learning process or internal states to its human teachers, the robot can proactively improve the quality of teaching.
The performance of participants as teachers for robots has been evaluated in the literature reviewed above with a number of metrics. These include the success of guiding the robot through the task [15], time spent on providing the demonstrations [15, 16, 51], the accuracy of learning, if the system was capable of actually learning from the participants [16], path-length and smoothness of the demonstrations [51], how strongly teachers grasp objects and how consistently they perform teaching [47], and, in case participants could ask for help, the number of help requests [15, 16]. Note, there has been some work specifically on quantifying teaching behaviour in robot learning scenarios, but mainly focused on the use of machine learning (e.g., [52, 57]). Sakr et al. conducted a two-sessions experiment to validate their proposed computational framework for assessing the quality of kinesthetic demonstrations [52]. In their experiment, 12 out of 27 participants (called ‘fast-adapters’) consistently provided high-quality demonstrations from the start. However, it took some time and practice for the rest of the participants (referred to as ‘slow-adapters’) to adapt to robot teaching so that they provided high-quality demonstrations only in the second session [52].
2.2 Human Teachers’ Behaviour When Teaching Robots
A number of human-centred studies have explored aspects of participants’ behaviours and mental models when teaching robots. For example, Kaochar et al. studied teaching styles and behavioural patterns of participants [34]. Participants used a computer-based interactive teaching framework for teaching an unmanned aerial vehicle in a simulated environment by giving demonstrations of actions. The majority of human teachers used all three available modes for teaching the robot: labelling objects, defining procedures, and providing feedback. Researchers then identified different patterns used by participants to switch between teaching and testing of the robot, as well as different teaching styles, depending on how organized the teacher’s instructions were [34]. Khan et al. also worked on understanding human teaching strategies, in the context of teaching a robot whether an object is graspable or not, by assigning binary labels to pictures of the objects [35]. The participants in their study were found to employ three major teaching approaches: (a) starting from extremely graspable or non-graspable objects and moving towards marginal examples, (b) teaching objects as per their original order, or (c) focusing only on graspable examples [35]. Strategies of human participants when teaching a simulated agent how to sort some blocks, particularly in terms of the communication of intent and execution of actions, have also been analyzed by Ramaraj et al. [49]. This study found that participants were teaching the system new concepts by instantiating and/or describing them, expanding or correcting previous knowledge of the system, evaluating its learning progress, and revising their own instructions. In another work, researchers have studied participants’ emotional experience and their perception of the robot and compared teaching some basic arm movement tasks visually to a robotic character with watching the robot self-learning [21]. Compared to watching the robot self-learning, teaching the robot boosted participants’ perception of trust, but did not affect their perception of the robot’s competency. Hedlund et al. investigated human teachers’ reactions to robot failure, mainly in terms of trust and workload, when participants employed kinesthetic teaching, tele-operation, or motion capture for robot teaching [30]. Participants rated motion capture as the least difficult of the three instructional methods and tele-operation as the most difficult, in terms of workload.
Still, there exist only a few studies that have taken into account the actual kinesthetic teaching of a robot for exploring human teachers’ behaviours. In social interactions, eye gaze is an important nonverbal cue that can be used to infer others’ intentions [22]. Saran et al. have studied gaze patterns of novice and expert human participants during kinesthetic demonstration of two tasks on a robotic manipulator: pouring pasta from a cup into an empty bowl and placing a spoon on a table with respect to other objects [53]. According to their results, both groups of users tended to fixate almost entirely on objects being manipulated or objects with which manipulation occurred during teaching. However, the gaze pattern of users with varying robot experiences showed some differences: novice robot users attended more to the robot’s gripper than expert users, possibly because they often struggled to manipulate the robot’s arm. Saran et al. later investigated the speech patterns of human teachers during kinesthetic or video-based teaching of multi-step manipulation tasks to a robotic manipulator, namely box-opening and fruit-cutting tasks [54]. Participants were asked to include speech in their instructions, either explicitly or implicitly. It was found that users conveyed similar semantic concepts through spoken words regardless of the modality of teaching. However, participants as teachers were more expressive during kinesthetic teaching, but talked less often when performing actions themselves for video-based teaching [54].
Situating this work with respect to the literature: In the present work, we study potential changes in kinesthetic teaching of non-expert participants as they gradually become more experienced robot teachers, with no external or formal training provided. This approach is comparable to the discovery method used in [51] in terms of allowing for trial-and-error; however, in our study, we have repeated interactions over multiple sessions and used a naturalistic unsupervised setup without external intervention into how teaching should occur (e.g., without asking participants to self-reflect on their performance as done in [51]). We also provide a more comprehensive analysis of different aspects of participants’ behaviour during kinesthetic robot teaching, compared to the literature reviewed above, and identify different clusters of non-expert teachers, to help address the unresolved problem of ‘who to imitate’ from a robot’s perceptive.Footnote 1 This includes an analysis of strategies used for manipulating the robot’s arm (specifically, the placement of participants’ hands on the arm of the robot when physically guiding the motions) and human teachers’ workload, as well as an investigation of their gaze behaviour during kinesthetic teaching tasks, which was also conducted in [53]. Compared to [52], our study focuses specifically on non-expert participants and studies broader aspects of their performance and behaviours over more sessions. Our general approach to evaluating the success of participants guiding the robot through the tasks and time spent on providing the demonstrations are based on [15, 16, 42, 51]. Motivated by the literature reviewed above, the next section presents our research questions for the current study.
3 Research Questions
Our study aims to answer the following research questions:
-
Over multiple sessions of non-experts kinesthetically teaching cleaning tasks to a humanoid robot,
- RQ1:
-
How does the success of teaching change over time?
- RQ2:
-
How does the teaching duration change over time?
- RQ3:
-
How do participants’ gaze patterns change over time?
- RQ4:
-
How does the method used for manipulating the robot’s arm change over time?
- RQ5:
-
How do different aspects of perceived workload change over time?
The study is exploratory and does not test any formal hypotheses based on previous literature with regard to the RQs, due to lack of studies, except for RQ3. For RQ3, we hypothesize that as participants become more experienced in robot teaching, they gaze less often at the robot’s hand (H1), in line with the study of Saran et al. [53] (See Sect. 2.2).
As noted before, some results related to demonstration success (RQ1) and duration (RQ2) were previously presented in [6]. Here, we extend our previous work and provide a more comprehensive analysis of previously published results by employing statistical models that account for a number of confounding factors. The importance of these confounding factors will be demonstrated in the statistical analyses. In addition, we present previously unpublished results regarding three additional research questions (RQ3, RQ4, and RQ5). When reporting the results, we discuss different characteristics of non-expert human teachers within three identified clusters, when repeatedly providing kinesthetic demonstrations.
4 Methodology
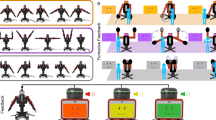
The experiment reported in this article involved repeated sessions where study participants attended five in-person sessions each. In all sessions, participants kinesthetically guided a Pepper humanoid robot [4] through four cleaning tasks by grasping onto and physically guiding the motions of its left arm. ‘Cleaning’ tasks were selected among other types of tasks because they are part of almost everyone’s daily routine, so most people are familiar with them. In Tasks 1 and 2, Pepper asked the participants to teach it how to clear different pieces/particles from cutting boards fixed onto a table. The next two tasks, Tasks 3 and 4, were to teach Pepper how to clear different whiteboard marker patterns from specific areas of a whiteboard. These tasks are illustrated in Fig. 1. A sponge was attached to Pepper’s left hand for cleaning the surfaces (see Fig. 2). The areas to be cleaned were expanded in the second task of cleaning the table and the whiteboard, i.e., in Tasks 2 and 4, to introduce additional challenges.Footnote 2 To accommodate individual differences, participants in this study were allowed to move the robot’s arm and teach it using any approach they wanted, with no time limit given. They ended teaching when they felt they were not able to guide the robot through the task any further because the robot always asked the participants to teach it how to perform the task ‘as much as it could.’ Participants received no direct instructions about the trajectories and how to provide the demonstrations. More details about the experimental design and procedure are presented in Sect. 4.2.
The purpose of our experiment was to understand how people’s teaching strategies and their behaviours and attitudes change over time when they repeatedly get involved in the kinesthetic teaching of a humanoid robot. Therefore, the robot in our experiment was only observing the demonstrations and ‘giving the impression of learning’, without having any learning capabilities (similar to [34, 35, 49]). However, we designed certain aspects of the experiment to make the human–robot teaching experience more realistic and to give participants the impression that the robot had learned something in the sessions, in order to keep participants motivated:
-
After completing all four tasks, and before the end of each session, the robot cleaned the same particles as in Task 1 located on a different table (see Session conclusion in Fig. 1), just to show that it could perform a similar task by itself after being taught the four tasks by the participant. The performance of the robot changed and depended on the participants’ success in teaching Tasks 1 and 2. This was done by executing one of three pre-recorded motion patterns, decided by the experimenter during the session based on the outcome of the participant’s table cleaning demonstrations in Tasks 1 and 2. More detail is presented in Sect. 4.2, under Session conclusion.Footnote 3
-
The material on the cutting boards and patterns drawn on the whiteboard were different in each of the five sessions for each participant, Footnote 4 to make participants feel that each session was dedicated to teaching something new to the robot. The materials and patterns for each session of each participant were counterbalanced with a Latin square design.

Layout and sequence of the experimental setup (right) and two examples of participants teaching cleaning tasks to the robot (left). At the location indicated as Session opening, Pepper greeted the participants and gave them information about the teaching session. The robot followed the path marked on the picture with dashed lines to interact with participants and receive demonstrations of four tasks at four different locations (Tasks 1–4). In Session conclusion, the robot showed the participant how it could clear the table on its own, and then asked them to pick up the tablet located on the table to complete the ending questionnaire. One-way mirrors to the adjacent room, where the experimenter was observing the scenario, are visible in the top right corner of the image
4.1 Robotic Implementation
A Pepper robot (by Aldebaran Robotics) [4] was used in this experiment. This robot was selected as it was able to move around the experimental room on its own and was sufficiently capable to be used in an unsupervised setting, i.e., without the presence of an experimenter in the room. The robot has been used in multiple settings and is safe for human participants. Moreover, as a humanoid and social robot, it seemed very suitable for a human–robot teaching task simulating home or office environments. The robot’s behaviours in the sessions were semi-autonomous: Pepper greeted the participant, provided the necessary instructions, and asked participants to carry out teaching in different locations, as well as to complete a questionnaire, by using scripted actions. The experimenter remained in a room adjacent to the experimental room to oversee the session through one-way mirrors, and remotely issued additional commands for the robot when needed. These commands were intended for relocating the robot after its own autonomous navigation or selecting a behaviour among different options. The experimenter was not visible to the participants who carried out the session on their own in the experimental room.
During the experimental sessions, the robot needed to position itself at specific locations for learning in front of a table and a whiteboard, and also performing a task in front of another table. To ensure consistency of recorded data and the played trajectories, only a few millimetres of error in the position of the robot were acceptable after navigating into these positions. Although all the manoeuvres of the robot were pre-planned with respect to the fixed setup in the experimental room, the robot’s navigation abilities failed to meet that expectation. To address the issue, the experimenter needed to remotely ‘nudge’ the robot after every autonomous navigation, i.e., correct the positioning error of the robot. This was necessary in case of a large navigation error or when a participant shifted the position of the robot’s base during teaching. However, visually verifying the precise location of the robot by the experimenter looking through one-way mirrors was challenging because the bottom part of the Pepper robot had a rounded shape and a high ground clearance. To overcome that obstacle, we attached three pieces of 3D printed white cylindrical shapes to the bottom of the robot which stayed only 1–2 mm above the ground and also marked circular signs on the floor corresponding to the position of those attachments when the robot was precisely at a given location. To adjust the position of the robot, the experimenter issued slow movement commands with the goal of matching the marks on the floor with two of the cylinders that were visible for each task (as pictured in Fig. 2).
To control the robot, two pieces of software were developed. We used Choregraphe, an application for creating and testing behaviours for NAO and Pepper robots [3], to program behaviours needed for running the sessions. These behaviours had slight variations in the robot’s dialogues to account for different materials to be cleaned and also to skip some conversations in later sessions.Footnote 5 To let the experimenter send additional commands to the robot when one of the Choregraphe behaviours was running, another program was developed using Python. A block of Python code to receive external commands was put in multiple places within the Choregraphe behaviours, e.g., before and after every movement of the robot to allow the experimenter to correct navigation errors. These blocks, when triggered, could pause the behaviour and read a character from a text file stored in the robot’s memory to move the robot accordingly in four directions, rotate it clockwise or counter-clockwise, or choose between any set of behavioural options. Another Python code running on the controlling computer was utilized to modify that text file, based on keyboard input, through an SSH connection with the robot. The resulting outcome was that after starting a session, the robot was autonomously operating and interacting with the participant until one of the above-noted blocks was triggered, i.e., when there was a need to choose an action based on the experimenter’s confirmation or the robot needed to be moved. As soon as the necessary commands were sent and executed, the robot continued autonomously. It is worthwhile mentioning that we tried to allow approximately 15 min between the sessions of different participants to let the robot cool down, to minimize Pepper’s faults and breakdowns.

The Pepper robot used in this experiment. A Areas on the robot’s arm parts for encoding participants’ hand placement during teaching, B five main joints (degrees of freedom) of the robot’s arm used for kinesthetic teaching are marked, C the sponge attached to the left hand of the robot for performing the cleaning tasks is shown, D the attachments used for precisely locating the robot in the experimental room are shown, showing the situation where they are aligned with the marks on the ground meaning the robot is at the correct location
4.2 Procedure
Ahead of their first visit, participants completed an online module running on our lab server to give consent, confirm their participation eligibility (based on criteria listed in Sect. 4.4), and answer a few demographic questions. Participants also received instructions on how to safely access our lab and follow COVID regulations.
Upon arrival for a session, in a room different from the study room where Pepper was located, the participants put on eye-tracking glasses with the experimenter’s assistance. To ensure an ideal fit of the glasses, the most suitable nose tip for every participant was selected before the first session. Once the eye tracker had been calibrated, participants entered the experimental room together with the experimenter. After the participant was located in a suitable location in front of the robot, the experimenter left the room and observed the experiment from an adjacent room through one-way mirrors. As visualized in Fig. 1, the procedure used for the experiment consisted of the following steps:
Session opening: Each experimental session was initiated by the robot greeting the participant and explaining their role as a robot teacher. The robot also informed participants of two potential issues, harmful to the robot, that could come up in such kinesthetic demonstrations, by asking them to avoid excessive arm extension and to avoid hitting any of the robot’s body parts with its arm. More specifically, the robot said: “I need you to teach me how to perform some cleaning tasks by grabbing my arm and showing movements that I need to do.... Before we move on, I want to remind you a few important things. Although I have multiple degrees of freedom in my arm, I have certain limitations. I may not be able to reach for objects that are too far or too close. Therefore, to provide useful instructions for me, please avoid stretching my arm too much. Also, be careful to perform actions in such a way that my arm doesn’t collide with any part of my body.” Only in the first session, the robot asked the participant to freely move its left elbow and then, its whole left arm, after turning the corresponding motors off, to let them experience the feeling of physical interaction with a robot before their first kinesthetic teaching task to minimize novelty effect.
Tasks 1 and 2 (Cleaning the table): To receive the demonstration of the first task group (i.e., cleaning the table, Tasks 1 and 2), the robot followed the path indicated in Fig. 1 to position itself in front of a table with its left arm on it. Note that the paths for the robot navigation were defined in a way that it usually moved away from the participant, so the participant could follow the robot safely around the experimental room. After arriving at the desired position, the robot explained more about the current teaching task: “I want to clear the [paper clips] from this blue area of this table, as much as I can. After the beep, I will let you grab and move my left arm to show me how should I do this. Please try your best not to shift my position in the entire experiment.” The robot then played a beep sound and turned off the motors in its left arm to allow kinesthetic teaching. While participants were teaching the robot, the robot was actively gazing at its left hand to appear attentive to the task, as suggested in [5]. Once the participant said “done”, as they were instructed, and gave up the robot arm (the experimenter also had to remotely approve this), the robot turned on its motors again, thanked them, slightly lifted its left arm, and moved to the second task. For Task 2, the same procedure was followed for receiving another kinesthetic instruction of cleaning an area of a table.
Tasks 3 and 4 (Clearing the whiteboard): The robot moved itself to the front of the whiteboard for receiving kinesthetic instructions for the next group of tasks (i.e., cleaning the board; Tasks 3 and 4). It rested its left hand on the whiteboard tray and then, asked the participant to come closer and teach it how to clear the area in front of it, similar to Tasks 1 and 2. All other details of the procedure were the same as above.
Session conclusion: After the participant provided all the demonstrations, the robot approached another table, placed its left arm on it, and said: “I will show you how I can now clear the [paper clips] from the table!” At that time, the experimenter selected a pre-defined cleaning behaviour of {no cleaning at all, partially cleaning, or full cleaning}, that came closest to the participant’s maximum success in teaching Tasks 1 and 2 during that session, in order for the robot to perform cleaning on its own, simulating robot learning. The behaviour selection was based on the experimenter’s observation of each participant’s behaviour in teaching Tasks 1 and 2, specifically their level of success of demonstrations. For those whose performance fell between two categories, the one with lower success in cleaning was selected. For no cleaning at all behaviour, the robot repeatedly and slightly moved its left hand, by rotating only a single elbow joint, to rub the sponge against the table. For partially cleaning the table, the robot utilized the same behaviour, yet exhibiting a wider range of motion, to effectively move some particles to the side of the cutting board. Full cleaning behaviour was programmed with movements in three degrees of freedom of the robot, to cover the full surface of the cutting board, including areas closer to the right side of its tablet. After showing its own performance, the robot asked the participants to answer the ending questionnaire, asking about the workload of each teaching session (NASA-TLX [29], discussed in Sect. 4.3.4), on a tablet that was already located on the table. Following the completion of the questionnaire, the robot thanked and said goodbye to the participant. The experimenter entered the room at that point and helped the participant remove the eye-tracking glasses. In case of the fifth, final session, the experimenter debriefed the participant about the real purpose of the study. Otherwise, the experimenter scheduled their next visit. Participants did not have two sessions on the same day.Footnote 6 Note, in order to prevent participants from becoming too self-conscious about their behaviour, it was not stated until the debriefing at the end of the study that the purpose of the experiment was to understand the ‘behaviours of human teachers’. The study had the rather general title of “human–robot Teaching Study”.
4.3 Data Collection and Analysis
We recorded and analyzed the (a) time-stamped positions of the joints in the robot’s left arm, (b) participants’ gaze data, (c) videos of participants teaching the robot, as well as (d) initial and ending questionnaires.
4.3.1 Time-Stamped Positions of the Joints in the Robot’s Left Arm
To capture the physical properties of the demonstrated cleaning behaviours, we saved position encoder values of all the five degrees of freedom in the left arm of the robot while participants were teaching the robot, at a frequency of 10 Hz. The recording of this data for each task began after the beep and ended when the participant verbally indicated that their teaching was finished. Using programmed Python blocks in Choregraphe, we saved that data as text files in the robot’s computer so they could be downloaded later. The data was then computationally processed to calculate the time spent on providing the demonstrations and the robot’s joints range of motions in demonstrations, and to estimate the amount of task space covered in the participants’ demonstrations. This last component is an estimate of how successful the cleaning demonstrations were and is therefore called success of demonstrations (estimated computationally).
To estimate to what extent the provided demonstrations covered the task spaces, the following automatic post-processing procedure was performed:
-
The joint positions were first converted to the trajectory of the end-effector, i.e., the left hand of the robot, by computing forward kinematics relative to a fixed frame attached to the robot’s base, using the NAOqi Cartesian control API [2]. In this frame, the x-axis points to the robot’s front, the y-axis points to the robot’s left, and the z-axis points upwards.
-
Trajectories of the robot’s left hand were examined along axes orthogonal to the surfaces being cleaned, i.e., the z-axis for clearing the table and the x-axis for cleaning the whiteboard, allowing the distance between the robot’s hand and the surfaces being estimated, to identify sponge-surface touching points. To obtain a smooth and continuous estimation of the distance between the sponge and the surface over time, a spline of degree 5 with smoothing factor s was fit on the orthogonal component versus time.
-
Touching points were found based on two parameters: (a) the second derivative of the spline was larger than a threshold \(h\ge 0\) at those points (which could reflect contact and separation), and (b) points were closer to the surface than the starting point plus a small tolerance \(t>0\) (to account for sponge compression during contact). An illustration of this procedure is shown in Fig. 3B for an example demonstration. In this case, the sponge appears to be periodically in contact with the table to push the particles.
-
Next, the algorithm approximated the sponge’s orientation at each touching point based on the first derivative of the trajectory projected on the cleaning surfaces, determined by its two adjacent neighbour points.
-
Lastly, points on rectangular grids (corresponding to cutting boards or writing areas of the whiteboard presented in the inverse kinematic frame) that were covered by placing the sponge at the touching points areas were marked as clean.
Figure 3C shows the trajectory and the estimated cleaned area of the previous example. We set the parameters \(s=0.003\), \(h=0.01\), and \(t=5\) mm for Tasks 1 and 2, and \(s=0.002\), \(h=0\), and \(t=5\) mm for Tasks 3 and 4, in order to obtain accurate estimations by testing multiple combinations. This computational approach does not require any vision system, which could, in future studies, allow the robot to automatically track human teachers’ success in real-world teaching situations (as discussed in Sect. 6.5.1).

Illustration of the computational method to estimate the success of demonstrations, showing an example from Task 2. A Picture of the partially cleaned task space, i.e., the yellow cutting board on the table with binder clips partially cleared, B The vertical z-component of the robot’s end-effector positions versus demonstration time, as well as the fit spline for determining touching points, C The demonstrated trajectory from the top (projected on the x–y plane) and the yellow board on the table. The computational algorithm estimated that 53.4% of the cutting board, highlighted in green, has been cleaned. The subjective estimate (i.e., rated by an experimenter and verified by a second rater) of the cleaned task space in this example, based on the picture of the task space, is 60%
4.3.2 Participants’ Gaze Data
Participants’ eye gaze was recorded using Tobii Pro Glasses 2 [61] at a frequency of 120 Hz during all the sessions. Gaze data were represented by points mapped on the glasses ‘scene camera video’, i.e., the video of what was seen by the participants, taken using the camera embedded in the glasses. To process the data, the moments when each teaching task began and ended were first manually annotated on the scene camera videos. Then, the pixel coordinates of participants’ eye gaze at each recording time step and the type of eye movement (Fixation or Saccade) were exported from the Tobii Pro Lab software for our analysis. We created a Python code to help measure the amount of participants’ gaze fixations on important regions related to the teaching tasks within their field of view, namely the robot’s hand, for all the tasks and cutting boards for Tasks 1 and 2. Ultimately, each fixation gaze data point was determined to be inside or outside of the defined regions.
By applying basic image processing techniques on the scene camera videos of Tasks 1 and 2, our algorithm automatically found dynamic quadrilateral regions corresponding to the cutting boards. To do so, the program carried out colour thresholding based on a given range of pixel values in the HSV colour space, using OpenCV [12], and found a mask corresponding to the blue or the green cutting boards. An opening morphological transformation with an \(8\times 8\) elliptical/circular kernel was then applied to the mask to remove noise. In the end, the cutting board was represented by a quadrilateral contour with four edges.
In addition, for all the tasks, dynamic regions corresponding to the sponge attached to the robot’s hand were identified. The process was semi-automated, with a researcher involved to correct any tracking errors. The program displayed the first frame of each teaching task from the scene camera videos, randomly and without any label. A circle had to be drawn by the researcher around the sponge, on top of the robot’s hand, in that frame of the video in order for the CSRT Tracking API [45] of OpenCV (which uses the discriminative correlation filter from [40]) to start tracking the sponge within an initial bounding box set based on the drawn circle. Afterwards, the video was played. The researcher could pause the video and draw another circle around the sponge to define a new reference bounding box in case poor tracking accuracy was detected. Figure 4 shows two snapshots of the processed scene camera videos of participants teaching Task 1, with the regions corresponding to the robot’s hand and the cutting board, both marked on the pictures.
Considering the cutting boards in the analyses of participants’ gaze was meant to help examine whether their visual attention to task-related areas apart from the robot’s hand showed any change after they became more experienced. In fact, the cutting boards were fixed to the table and therefore, no teaching action needed to be done on them directly. In a preliminary evaluation of our data, we observed no patterns in terms of the amount of fixations on the cutting boards or cutting boards combined with the robot’s hand, which only were available for Tasks 1 and 2 throughout the sessions. Thus, the analysis of human teachers’ gaze data presented in this work only includes the amount of gaze fixations on the robot’s hand, to test our hypothesis outlined in Sect. 3.

Two snapshots of the processed scene camera video obtained from Tobii Glasses 2 gaze recording device. The images show two participants’ own views while teaching the robot Task 1. Black circles drawn on the images locate the robot’s hand, purple quadratic regions represent the cutting board, and green dots indicate participants’ gaze fixation targets
4.3.3 Videos of Participants Teaching the Robot
In order to investigate the methods and strategies used by participants to manipulate the robot’s arm for kinesthetic teaching, we video-recorded all the sessions using two cameras. It was necessary to have two cameras as our experimental design required participants to face different directions to teach multiple tasks. To minimize distractions, the camera in the experimental room was on a small tripod inside a closet and the other one was behind one of the one-way mirrors in the adjacent room.
Using BORIS event-logging software [24], a researcher reviewed all the videos to encode the participants’ hand positions during teaching as well as different participant behaviours, related to the tasks but not contributing to the movements, observed during demonstrations (e.g., anthropomorphic behaviours and comparisons between themselves and the robot). The position of each hand of participants was labelled as lying {nowhere, on the table, on the robot’s hand, on the robot’s forearm, robot’s upper arm, or robot’s shoulder}. The exact location of different robot arm parts, i.e., hand, forearm, upper arm, and shoulder is shown in Fig. 2. These markers were then used to calculate the amount of the usage of both hands, guiding the robot’s upper arm with at least one of their hands, and not guiding the robot’s hand while teaching each task, as percentages showing the duration of those events compared over the entire teaching duration. The number of changes in teaching strategy during teaching each task, counting any change in the placement of each hand of a participant during teaching, was also derived from the annotated videos. For example, if a participant was guiding the robot’s upper arm with their right hand and then used that hand to move the robot’s forearm, one change in their teaching strategy was counted.
The four features noted above were selected because we noticed some trends in our preliminary evaluation of the data and identified those as worth checking in detail: teaching with both hands and holding the robot’s upper arm could imply adapting a teaching strategy by non-experts for safer/easier robot arm manipulation (based on what experts may do while performing same tasks). Furthermore, instances when teachers were not guiding the robot’s hand while demonstrating tasks could mean adjusting the joint of the robot’s arm, without contributing to the task directly, and finally, changes in teaching strategy could help understand to what extent non-experts try new methods for robot teaching.
With the videos of participants teaching the robot, a researcher also evaluated the success of demonstrations (estimated subjectively), i.e., the percentage of cleaned areas in the demonstrations based on screenshots showing the task spaces after the sessions. Using a Python script, the coder was presented with cropped images containing only the teaching workspaces, in random order and with no label, to minimize biases. The percentage of subjective success was entered with a precision of 5%. These estimates were equivalent to the success of demonstrations estimated computationally with the method described in Sect. 4.3.1.
4.3.4 Initial and Ending Questionnaire
The initial questionnaire, completed prior to participants coming to the first session gathered data on participants’ demographics. This demographic questionnaire asked participants about their (a) age, (b) gender, (c) occupation, and (d) handedness, as well as (e) whether they had ever programmed any robot, interacted with a human-like robot, or a Pepper robot in particular, and (f) if they have ever participated in a study related to human–robot teaching, to control for potential confounds. At the end of each session, we asked participants to answer a NASA-TLX workload questionnaire. The NASA-TLX is a widely-used assessment tool that allows participants to perform subjective workload assessments, on six scales of mental demand, physical demand, temporal demand, performance, effort, and frustration [29]. Our approach in this study, which is a common variation to NASA-TLX [28], was to capture and analyze sub-scale ratings of workload rather than a single overall workload score. This way, we studied workload from a number of different aspects, e.g., mental and physical. This questionnaire was answered on a tablet that could locally store the data. Answers to each scale of the questionnaire were recorded on a continuous scale ranging from 0 to 1000, with 1000 being the highest workload score on the NASA-TLX sub-scales.
4.4 Participants
In total, 28 volunteers completed our study. As outlined in the study recruitment flyer, the eligibility criteria were: (a) not being a roboticist or an HRI researcher, (b) being able to see close distances without glasses (so that eye-tracking glasses could be worn without lenses attached), and (c) meeting requirements regarding participants’ potential safety risks.Footnote 7 The participants were all University of Waterloo students, between the age of 18 and 31 (M=21.54, SD=2.55). 12 self-identified as female, 15 as male, and one who did not disclose their gender. All participants except one were right-handed. Seven participants had previously programmed a robot, mainly during high school activities, but none had ever interacted with a human-like robot. The study received full ethics clearance from the University of Waterloo Human Research Ethics Board.
4.5 Data Reliability
All subjective data obtained from videos of participants teaching the robot, i.e., the success of demonstrations and their hand positioning during teaching, was verified by another researcher coding a small portion of the data. For the subjective estimates of the success of demonstrations derived from images of the tasks, one researcher coded all and another researcher coded 25% of the data (140 picture evaluations). We then performed an inter-rater reliability analysis. Ratings of the random subset of data that had been coded twice produced an intra-class correlation coefficient of 0.95 (95% CI: 0.88 to 0.97, \(F(139,18.6)=45.4,p<.0014\)), confirming good to excellent reliability of the subjective approach for reporting the success of demonstrations [38].
Positions of participants’ hands during teaching were similarly coded, and 10% of the videos of the sessions (54 tasks) were also coded by another researcher to verify the calculated measures. Intra-class correlation coefficients of 1.00 (95% CI: 0.99 to 1.00, \(F(53,53.7)=410,p<.0014\)), 0.99 (95% CI: 0.98 to 1.00, \(F(53,53)=152,p<.0014\)), 0.73 (95% CI: 0.56 to 0.83, \(F(53,45.9)=6.69,p<.0014\)), and 0.75 (95% CI: 0.59 to 0.84, \(F(53,53.1)=6.64,p<.0014\)), for the usage of both hands, guiding robot’s upper arm, not guiding robot’s hand, and changes in teaching strategy, respectively. These numbers confirm the excellent reliability of the first two measures and the moderate to good reliability of the last two [38].
To remove noise from the data collected for all 560 tasks over the 140 sessions, the following procedure was carefully followed:
-
(a)
Time spent on providing the demonstrations was adjusted for a total of 20 tasks due to special circumstances occurring during teaching that increased the recorded time. These events included re-alignment of the sponge in the robot’s hand (13 instances), eye-tracking glasses re-calibration (2 instances), and participant asking a question during teaching (1 instance).
-
(b)
To ensure consistency, the success of demonstrations data for 12 tasks (estimated both computationally and subjectively) were removed, because the robot was either not at the right position when receiving demonstrations or was moved considerably by the participant during teaching, as detected in the videos of participants teaching the robot.
-
(c)
Gaze data were not included in case fewer than 70% of all the possible data points when teaching each task had been recorded, to ensure that the calculated fractions of fixations represent almost the entire duration of each task. This factor led to the omission of gaze data for 66 tasks.Footnote 8
Due to technical errors, there was one experimental session during which position data of the joints in the robot’s left arm was not recorded and another session during which video recording was not saved. In two of the experimental sessions, NASA-TLX questionnaires were not recorded. Errors in recording or processing of participants’ gaze data also led to missing gaze data for 13 tasks.
4.6 Data Analysis and Statistical Modelling
To look deeper into participants’ individual characteristics and potentially identify more suitable teachers for robots based on their achievements in providing physical demonstrations, we looked into the average success of Tasks 1 and 2, i.e., cleaning on the table, in each session.Footnote 9 Taking the five success averages as the features, we applied a k-means clustering algorithm to categorize the participants into different clusters [39, 48]. \(k=3\) produced the most reasonable clustering. Accordingly, we introduced a factor named cluster, assigned to every participant (more details are presented in Sect. 5.1).
To answer our research questions, we used Linear Mixed-effects Models (LMMs) [8] and analyzed the changes in obtained measures as participants taught the robot over multiple sessions with participant and task nature (the robot being taught at the table or at the whiteboard) as random effects: a random intercept for each participant, and a random slope for task nature. The considered factors for the analysis of different categories of data to study each research question are as follows:
-
For success of the demonstrations (RQ1):
-
Session number and task order Footnote 10 as numeric variables ranging from 1 to 5 and 1 to 4, respectively, to account for between-sessions and within-sessions progress of participants in teaching the robot.
-
Age and gender of participants as possible confounding factors.
-
Amount of gaze fixations on the robot’s hand, usage of both hands, guiding the robot’s upper arm, not guiding the robot’s hand, and changes in teaching strategy as confounding behavioural variables that could have influenced teaching time and success.
-
-
For time spent on providing the demonstrations (RQ2):
-
Session number and task order, plus amount of gaze fixations on the robot’s hand, usage of both hands, guiding the robot’s upper arm, not guiding the robot’s hand, and changes in teaching strategy for the same reasons as above.
-
Participants’ assigned cluster, as well as age and gender of participants as possible confounding factors.
-
-
For amount of gaze fixations on the robot’s hand (RQ3):
-
Session number and task order, plus age and gender of participants, for the same reasons as above.
-
Participants’ assigned cluster, to identify potential differences in their behaviours and see if they are correlated with high/low achievements.
-
Usage of both hands, guiding robot’s upper arm, not guiding robot’s hand, and changes in teaching strategy for taking into account the possibility of the methods used for manipulating the robot’s arm influence the gaze patterns.
-
-
For the behavioural data on manipulation and teaching strategy, i.e., amount of usage of both hands, guiding robot’s upper arm, not guiding robot’s hand, and changes in teaching strategy (RQ4):
-
Session number and task order, plus age and gender of participants, for the same reasons mentioned earlier.Footnote 11
-
-
For NASA-TLX workload items (RQ5):
-
Session number, and age and gender of participants, for the same reasons mentioned earlier.
-
Average time spent on providing the demonstrations, average success of the demonstrations, average gaze fixations on robot’s hand, average usage of both hands, and average amount of guiding robot’s upper arm as possible confounding factors, since NASA-TLX workload questionnaires had been collected after each session (not for each task).
-
The factors listed above were initially included in the models. We then kept only a subset of those to minimize the Akaike’s Information Criterion (AIC) [11]. After checking the interaction effects, we gained the final models presented in the Results section. We also visually checked if the assumptions for the usage of LMMs were met, namely the residuals having constant variance and are independent and normally distributed, using histogram and Q-Q (quantile-quantile) plot for the residuals and scatter plot of residuals against the fitted values. If not, we applied a transformation to our data (the only case was the analysis with regards to RQ1, Sect. 5.1). Note, the baseline category for participants’ assigned cluster is ‘high-achievers’ and for gender is ‘female’, in all presented models.
5 Results
In this section, we explain how success of the demonstrations, time spent on providing the demonstrations, amount of gaze fixations on robot’s hand, behavioural data on manipulation and teaching strategy, and NASA-TLX workload items were impacted by participants’ repeated teaching interactions with the robot, both between the sessions and within the sessions, to answer RQ1–5. We also report how the confounding factors taken into account affected these measures and explore the characteristics of participants who achieved different success rates in teaching.
5.1 Success of Demonstrations—RQ1

Success of demonstration of each task estimated using two methods of subjective and computational over five sessions. 95% confidence intervals are shown
We initially observed that participants were able to move some joints of the robot within a wider range overall. For example, in teaching Task 1, the ElbowYaw joint in the left arm of Pepper was moved on average within 40.57 degrees (SD = 30.19 degrees) in Session 1, 57.58 degrees (SD = 37.81 degrees) in Session 2, and 65.66 degrees (SD = 38.61 degrees) in Session 3. These trends suggested that the overall area covered by the demonstrations may have increased over time.
The percentage of covered areas (i.e., cleaned areas) in the demonstrations, indicating the success of demonstrations, was estimated using two approaches: subjective (described in Sect. 4.3.3) and computational (described in Sect. 4.3.1). Figure 5 shows the average success of demonstrations over the sessions, estimated using both methods. As seen in the figure, computational evaluations of success were noticeably lower than subjective evaluations in Tasks 1 and 2. However, computational estimates had high positive correlations with the subjective estimates in all the tasks according to Pearson correlation analyses: \(r(136)=.744,p<.001\) in Task 1, \(r(137)=.837,p<.001\) in Task 2, \(r(136)=.861,p<.001\) in Task 3, and \(r(136)=.907,p<.001\) in Task 4. The trends observed in Fig. 5 also show that both subjective and computational approaches undergo changes in a correlated manner. All these findings support the validity of the computational method for revealing variations in the success of demonstrations.
For the rest of the statistical analyses presented in this article, only the ‘subjective’ estimates of demonstrations’ success are taken into account, since they are more accurate estimates, in the sense that they are derived from a human observer’s ratings that could be considered as a ground truth. As shown in Fig. 5 and in line with the increase in range of motion in individual robot’s joints, the provided demonstrations in later sessions covered larger areas overall. The average success rate of participants, across all four tasks, was 78.5% (SD=27.21%) in Session 1, 85.22% (SD=23.98%) in Session 2, 89.72% (SD=20.02%) in Session 3, 89.12% (SD=20.51%) in Session 4, and 91.18% (SD=18.30%) in Session 5. In Tasks 1 and 2, participants, on average, improved their teaching success over the few first sessions. The success of providing the demonstrations of Tasks 3 and 4 was generally higher than that for Tasks 1 and 2. We previously presented the aforementioned results in [6]. In this work, we continue the analysis of demonstration success by exploring the data more deeply and at an individual level, highlighting the impacts of some confounding factors.

Average success of demonstration of Tasks 1 and 2 for each cluster of participants over five sessions. 95% confidence intervals are shown
As described earlier in Sect. 4.6, we looked at the teaching success of participants in Tasks 1 and 2 and categorized non-expert teachers into three clusters. As shown in Fig. 6, participants in each of the three clusters shared a unique characteristic in terms of average success in providing demonstrations for Tasks 1 and 2 over the sessions. We therefore called them high-achievers, improving, and low-achievers, as explained below:
-
The ‘high-achievers’ were 9 participants who showed high teaching success from the first session. In this cluster, the average success of Tasks 1 and 2 for each participant was at least 80% in every session. 44 out of 90 total provided demonstrations of Tasks 1 and 2 were fully successful. According to Fig. 6, high-achievers also improved slightly over the sessions. The small confidence interval observed for the average demonstration success in Session 5 implies that high-achievers became consistently successful eventually.
-
The ‘improving’ participants were the biggest cluster consisting of 15 participants whose average teaching success of Tasks 1 and 2 was not high at the beginning, but later improved. As seen in Fig. 6, the improvement was more prominent over the first three sessions. Each participant in this cluster provided table cleaning demonstrations of at least 87.5% successful in a session after Session 1.
-
The ‘low-achievers’ cluster consisted of 4 participants who less successfully demonstrated the table cleaning tasks without showing any noticeable improvement over the sessions. For these participants, the most effective demonstration of table cleaning tasks in a session was only 67.5% successful.
An LMM fit on the transformed data showing the success of demonstration is presented in Table 1. To fit the LMM, subjective estimates of the success of participants’ demonstrations in each task are divided by 20 and transformed exponentially, so the model meets the assumptions. In this model, the effect of Session is studied within each cluster. Both high-achievers and improving participants demonstrated the tasks more successfully as they moved forward in the sessions (\(p<.001\)). Overall, as participants proceeded with tasks within the sessions, i.e., from tasks 1 to 4, the success of their demonstration was improved too (\(p<.001\)). Male participants, on average, provided significantly more successful demonstrations than female participants (\(p<.05\)). The percentage of gaze fixations at the robot’s hand was another significant factor positively affecting the success of demonstrations (\(p<.01\)). The model also revealed that increased usage of both hands for teaching led to more successful demonstrations (\(p<.05\)).
5.2 Time Spent on Providing the Demonstrations—RQ2

Average time spent on teaching each task to the robot over five sessions. 95% confidence intervals are shown
Figure 7 shows the average time spent on providing demonstrations of each task over the five sessions. The results indicate a steady decrease in demonstration time for Tasks 1 and 2 over the five sessions. There is also a decrease in Tasks 3 and 4 demonstration times, but most noticeably when comparing only Session 1 with other sessions. These results were previously presented in [6], but here, for a more detailed analysis of demonstration times, we consider possible confounding factors. Table 2 shows the results of an LMM fit on the data. According to this model, as participants proceeded through the sessions, they spent less time teaching the robot (\(se=0.388,t=-8.405,p<.001\)). Using both hands for teaching slightly increased the teaching time (\(se=0.027,t=3.097,p<.01\)). Moreover, teaching time was positively affected by the number of changes in teaching strategy (\(se=0.351,t=7.371,p<.001\)).
5.3 Amount of Gaze Fixations on Robot’s Hand—RQ3
The average percentage of gaze fixations on the robot’s hand over all gaze fixations while teaching each task is illustrated in Fig. 8 for the five sessions. As can be seen in the figure, participants spent less time looking at the robot’s hand when teaching Task 2 compared with other tasks. An overall decreasing trend is also visible in Fig. 8, mostly when looking at Tasks 3 and 4. As indicated by the LMM fit on this data (see Table 3), the fixations on the robot’s hand decreased as the participants proceeded through the sessions (\(se=0.371,t=-3.919,p<.001\)), which confirms H1. There was also a decrease in the fixations on the robot’s hand in successive tasks within the same session (\(se=0.912,t=-4.824,p<.001\)). Participants’ age was found to be significantly affected by the fixations on the robot’s hand: younger participants looked more often at the robot’s hand when teaching (\(se=0.463,t=-3.074,p<.01\), keeping in mind that participants were all university students and therefore had a narrow age range). The final model did not include any behavioural characteristics of participants for the robot’s arm manipulation, meaning that none of the usage of both hands, guiding the robot’s upper arm, guiding the robot’s hand, and changes in teaching strategy were found to be affected by participants’ gaze allocation patterns.

Average percentage of participants’ gaze fixations on the robot hand during teaching each task (compared to all gaze fixations during teaching) over the five sessions. 95% confidence intervals are shown
5.4 Behavioural Data on Manipulation and Teaching Strategy—RQ4

Average percentage of the time when (A) participants used both hands, (B) the robot’s upper arm was guided, and (C) the robot’s hand was not guided, as well as (D) the average number of changes in the teaching strategies, during kinesthetic teaching over five sessions, for each cluster of participants. 95% confidence intervals are shown
Figure 9 illustrates the trends in the data on the robot’s arm manipulation and teaching strategy derived from the analysis of video recordings of the sessions. This figure includes the average percentage of duration when participants used both hands, participants held the robot’s upper arm, and the robot’s hand was not guided during kinesthetic teaching of each task over five sessions, as well as the average number of changes in the teaching strategies (i.e., placement of participants’ hands on robot’s arm) for each participant cluster. As can be seen in Fig. 9A, B, there was an increase in the average time teaching using both hands and guiding the robot’s upper arm over the sessions, for improving participants. This increase was most pronounced in the early sessions. For high-achievers, there is also an increasing trend of guiding the robot’s upper arm when teaching over the sessions. Low-achievers used both hands for teaching around three times less than the other two clusters. Low-achievers barely guided the robot’s upper arm when providing their kinesthetic demonstrations. In fact, no participant in that cluster ever touched the robot’s upper arm in Session 3 when teaching any task to the robot. As seen in Fig. 9C, compared to other clusters, low-achievers spent more time teaching without guiding the robot’s hand. From Fig. 9D, it can be seen that in later sessions the majority of participants were more consistent in the number of changes in their teaching strategies (smaller confidence intervals). In every session, high-achievers made the highest average number of changes in their way of guiding the robot’s arm when teaching it. Improving participants made slightly fewer changes than high-achievers. Low-achievers made considerably fewer changes compared to the other two clusters, especially in the first four sessions.
The LMMs investigating the behavioural data on manipulation and teaching strategy of improving participants are presented in Table 4. Improving participants used both hands at the same time for teaching and guided the robot’s upper arm at least with one hand more frequently as they gained more experience over the sessions (\(se=0.789,t=6.030,p<.001\) and \(se=0.907,t=7.465,p<.001\), respectively), and within the sessions (\(se=1.028,t=4.068,p<.001\) and \(se=1.376,t=3.562,p<.01\), respectively). The models also suggest that the percentages of times when the improving participants were not guiding the robot’s hand decreased with their progress within sessions (\(se=0.282,t=-5.945,p<.001\)). Improving participants changed their teaching strategy less often in later sessions in the experiment (\(se=0.056,t=-2.851,p<.01\)) and when progressing within the sessions (\(se=0.103,t=-3.186,p<.01\)). As noted before, we do not provide further statistical analyses concerning the other two clusters due to a lack of data (too few participants fell into these clusters) and their data did not follow a normal distribution.
5.5 NASA-TLX Workload Items—RQ5
Figure 10 shows results for the NASA-TLX workload questionnaire items answered after teaching all the tasks in each session. While the average perceived mental demand and physical demand seem to remain unchanged over the different sessions (Fig. 10A, B), the average perceived effort appears to decline over the sessions (Fig. 10E). There are also drops in the average perceived temporal demand and frustration in the final Session 5 (Fig. 10C, F). The average perceived performance seems to increase after Session 1 (Fig. 10D).
According to the LMMs fit on the NASA-TLX questionnaire data (see Table 5), session number only affected the perceived effort of participants, which significantly decreased with repeated experience in multiple sessions (\(se=7.382,t=-2.508,p<.05\)). Spending more time on providing the demonstrations was also correlated with a higher perceived mental demand and effort (\(se=0.768,t=2.361,p<.05\) and \(se=0.989,t=3.335,p<.01\), respectively), but less positive evaluation of performance (\(se=1.137,t=-2.700,p<.01\)). With more successful demonstrations, participants rated their own performance more positively (\(se=1.187,t=3.851,p<.001\) ).

Average ratings of NASA-TLX questionnaire items over the five sessions
5.6 Other Observations
When reviewing videos of the teaching sessions, we noticed five participants who exhibited interesting behaviours toward the robot during or after teaching tasks (they will be called Participants A, B, C, D, and E here). While these observations are anecdotal, we are documenting them here since they might inspire future work. Participant A communicated their instructions verbally during kinesthetic teaching of some tasks in the first three sessions. Participant B verbally repeated the robot’s instructions, e.g., about not moving its position, while teaching it. Participant C put a hand on the robot’s back after finishing teaching and Participant D gave thumbs-up and petted the robot, following the teaching. Participant E tested the movements on their own body before teaching the robot, to see how their arm joints may move to achieve a certain motion. All five participants referred to here belonged to the improving cluster, except for participant A, who was among the low-achievers.
The average age of the high-achiever participants was 20.78 (SD = 2.10) and three of them had programmed a robot before. Participants in the improving cluster had an average age of 21.93 (SD = 2.89). Among them, four had previously programmed a robot. The low-achiever participants were on average 21.75 years old (SD = 0.83) and none had programmed a robot before.
6 Discussion
This study was conducted to understand whether and how inexperienced human teachers may gradually become more skilled robot teachers through repeated unsupervised kinesthetic teaching of a humanoid robot, with only limited instructions and with no detailed, direct feedback provided on their kinesthetic teaching approach. They only received, after each teaching session, coarse-level feedback on their overall teaching performance in Tasks 1 and 2, via the robot providing one out of three pre-defined demonstrations of a similar task. When participants experienced kinesthetic teaching of a robot in a set of cleaning tasks in multiple sessions, we studied the success of demonstrations, changes in the time it takes them to provide their demonstrations, their gaze pattern, aspects of how they manipulate the robot’s arm, and their perceived workload.
6.1 Teaching Success and Duration—RQ1,2
According to the patterns observed in the success of demonstrations of table-cleaning tasks throughout the sessions, we discovered that our non-expert participants could be categorized into three clusters. For 15 out of 28 participants, i.e., improving participants, after they taught the robot more tasks over the five sessions, their demonstrations covered significantly larger areas, which was more effective, as a result of them using a larger range of the robot arm’s movements. 9 out of 28 participants, i.e., high-achievers, could provide successful demonstrations from the start and so showed only small improvements over the sessions. The presence of ‘improving’ and ‘high-achiever’ participants in kinesthetic teaching based on certain measures of teaching success was also observed in the study of Sakr et al. [52], referred to as ‘slow-adapters’ and ‘fast-adapters’, respectively. In our study, 4 out of 28 of the non-expert participants, i.e., low-achievers, consistently failed to provide highly successful kinesthetic demonstrations during the five sessions. Such a cluster was not found in [52]. Note that in our study, all the participants were non-expert robot users (although some had experienced basic robot programming, e.g., in high-school), whereas in [52] participants had different levels of robotics expertise. Here, all the low-achievers were from the participants who did not have any experience with robots.
Overall, the majority of participants in this study achieved higher success in demonstrating the tasks while they spent less time teaching the tasks. The success of teaching was improved even within the sessions when teaching the robot four tasks. According to these findings, which address RQ1 and RQ2, the majority of participants in our study were able to teach robots more efficiently in terms of success and duration as they gained more experience. A high level of adaptation to robot teaching was observed in 15 out of 19 participants who were not successful in teaching the robot at first (both low-achievers and improving participants), despite the fact that teaching the robot was done in an unsupervised setting and participants did not receive any detailed, direct feedback on each teaching task. It should be noted that those conclusions could be limited to the sample we studied, as discussed later in Sect. 7.
Regarding the considered confounding variables, teaching time was positively affected by the number of changes in the manner in which participants manipulated the robot’s arm and how much they used both their hands for teaching. The first effect could be expected, since every change in the teaching strategy may take time for participants to reflect upon, not only for repositioning the arms but also for thinking of a new manipulation strategy. Yet, one might expect that using both hands at the same time should lead to easier robot arm manipulation and therefore shorter demonstration times, contrary to what we observed. A possible explanation could be that after participants used both their hands more, they were more careful in moving the robot’s arm and, therefore spent more time providing the demonstrations. This is in line with another finding of ours that suggested more usage of both hands led to more successful demonstrations. An alternative explanation could be that, as participants might have been moving multiple joints when using both hands, and since the robot had earlier asked them to be careful about not colliding its body parts, they performed the task more carefully, thus increasing the time of demonstration. Future studies may uncover how and why the speed of providing physical demonstrations of tasks may be influenced by the usage of both hands for teaching.
Note, given that the usage of both hands was found to positively affect teaching time, it might seem contradictory that over the sessions, participants spent less time teaching, when they used both hands more for teaching. In fact, all the significant factors included in the LMMs jointly affect teaching time. In this case, because the negative effect of session number on teaching time reported in Table 2 has a much greater magnitude compared to the positive effect of the usage of both hands, affected negatively by session number and positively by the usage of both hands combined, teaching time decreased in later sessions.
6.2 Human Gaze Patterns During Teaching—RQ3
To test our hypothesis with regards to RQ3, we analyzed the percentage of participants’ gaze fixations that were directed at the robot’s hand. The data shows that participants gazed less often at the robot’s hand overall, with gaining more experience in teaching the cleaning tasks to the robot, both over different sessions and within single sessions. These findings are in line with [53], where expert users spend less time fixating on the robot’s gripper when kinesthetically teaching a robot how to pour pasta from a cup into a bowl. Our hypothesis H1 is therefore confirmed.
A possible explanation for the observed decline in the percentage of fixations on the robot’s hand with repeated teaching can be that participants paid more visual attention to other parts of the robot, e.g., to the robot’s joints to monitor its motions to produce more useful trajectories, or to the robot body’s parts in order not to cause self-collisions, after gaining more experience. In the present study, the gaze target of the participants was not examined further to determine where exactly human teachers looked when they paid less attention to the robot’s hand, as this highly time-consuming analysis was not a focus of the study. For a more in-depth gaze analysis, the main challenge was to localize more regions in view in dynamic scene camera videos. Here, we implemented a method to track the robot’s hand, which was easier due to its special shape that was not changing during teaching. Other parts of the robot’s arm, e.g., forearm, upper arm, and shoulder (see Fig. 2), were all white, may have been occluded by the participant’s own arm during teaching, and may have looked very different from various angles observed by participants during teaching, thereby making them difficult to track computationally. In alternative studies, one could attach trackable labels to different robot parts to use with computer vision systems, but that could introduce bias by shifting participants’ attention and, therefore, was avoided in our study. In light of this, the gaze data collected in our study may be further examined using more advanced computer vision techniques in future studies.
There were also other interesting observations with regards to the gaze behaviour of human teachers. As illustrated in Fig. 8, a lower average gaze at the robot’s hand was detected during teaching Task 2 as compared to the other tasks. If the above-mentioned assumption is true, which suggests participants paying less attention to the robot’s hand implies checking the joints’ motions more to avoid self-collisions, then our observation might be justified. Task 2 was one of the challenging tasks, as can be noticed by the lower average success of teaching compared to Tasks 3 and 4 (see Fig. 5) and its task space was extended compared to Task 1. Those challenges and also the extent of the task may have required participants to look more at the joints or at the body parts of the robot, and not at the robot’s hand, during teaching. This could also suggest that the participants were able to adjust their strategies themselves based on the nature of the tasks, without any instruction or feedback on their performance.
6.3 Behavioural Data on Manipulation and Teaching Strategy—RQ4
The analyses of data extracted from videos of participants teaching the robot (addressing RQ4) suggested that improving participants were more likely to use both hands for teaching and more often guided the robot’s upper arm as they got more robot teaching experience. These findings suggest that participants whose success was substantially improved over the sessions changed their strategies and adapted to robot teaching in an unsupervised setting in terms of their method of physically guiding the arm of the robot. Manipulating the robot’s arm with both hands and moving the robot’s upper arm itself could possibly improve teaching performance as it enables teachers to cover a larger area in their physical demonstrations, which seems to have been discovered by the participants after they gained experience, as noted in Sect. 6.1.
It was also observed that as improving participants gained more experience in kinesthetic robot teaching within the sessions, they were more likely to hold the robot’s hand during teaching. Some instances when teachers were not guiding the robot’s hand while demonstrating how to perform a physical task are when improving participants might have simply been adjusting the joint of the robot’s arm, without contributing to the task directly. Therefore, as not guiding the robot’s arm decreased in the sessions, improving participants might have spent less time merely repositioning joints in the robot’s arm as they taught the robot more and more tasks in a short period of time.
In our experiment, participants employed many different strategies to physically manipulate the robot’s arm, and we therefore could not cluster human physical behaviours while teaching into a few types (as was done in [34, 35]). However, in our study, significantly fewer changes in the teaching strategy of improving participants, in terms of how they manipulated the robot’s arm, were observed in later sessions, and in later tasks within the sessions. This implies that after teaching more tasks, improving participants came up with more consistent teaching strategies and employed them from that point onwards in future robot teaching tasks in the experiment.
In this study, we found certain differences among the three clusters and observed patterns in the behaviours of high-achievers and improving participants that might have contributed to the success and effectiveness of teaching the robot, which also suggested that the majority of participants could learn how to adapt their strategies after exploring robot teaching without any detailed, external feedback on their behaviour. Low-achievers mostly used only one hand for kinesthetic teaching and did not guide the robot’s upper arm as much as the other participants. Plus, they seemed to have changed their teaching strategy less often than others in the initial teaching tasks. We need to raise some caution with the interpretation of the data regarding some of the clusters, especially low-achievers, since fewer participants fell into this cluster compared to improving participants (see Sect. 7 for discussion on this limitation).
6.4 Human Teacher’s Workload—RQ5
To study RQ5, we asked participants to self-evaluate their workload for each of the five teaching sessions. We used the NASA-TLX workload index for this purpose. The only scale that was found to be affected by the experience of participants over the sessions was the perceived effort. Our results show that by experiencing robot teaching in multiple sessions, the tasks were perceived as less effortful for the participants: participants felt that it was easier to accomplish the tasks in later sessions. This could be expected because when we practise a certain type of task repeatedly over time, we tend to perceive less effort doing it, so the task will require a lower cognitive load [60]. It is also noteworthy that temporal demand was not affected by the average time spent on providing the demonstrations, thereby supporting that participants actually did not perceive any time limit was imposed on their demonstration. This was expected as the participants were not given any time limits, they could spend as much time as they wished on their teaching.
There were a few confounding factors that affected certain dimensions of human teachers’ workload when teaching tasks to the robot. Achieving a higher success rate in demonstrations led to a higher performance rating by the participants. This shows that participants’ own evaluation of their performance in the teaching tasks was consistent with external evaluations (i.e., evaluation of success through pictures).
Moreover, by spending more time teaching the robot, participants reported higher perceived effort and mental demand. The same effect on physical demand was also close to being statistically significant (\(p=.055\)). All these trends could be expected, as time spent on performing a task may influence perceived effort and demand, e.g., by increasing fatigue. We also observed that with using both hands more often for teaching, demonstration times increased. Using both hands, which can be more mentally and physically demanding, might have led to an increase in the above-mentioned scales of participants’ workload. Contrary to those trends, we found that longer demonstrations led to a lower evaluation of performance, perhaps because it indicates less efficiency in performing a task. An effect approaching significance (\(p=.061\)) of teaching time on perceived frustration was also observed which might suggest that participants became more frustrated as they spent more time teaching. All these observations can be investigated further in future experiments with greater statistical power, as they may suggest trade-offs between time and success of demonstrations and perceived workload and effort. The effect of participants’ fatigue on the reported workload measures can be further examined in future research.
6.5 Other Reflections
6.5.1 Measuring Teaching Success Through Robot’s Joint Data
The success of demonstrations included in our analyses was estimated subjectively, based on a researcher’s evaluation of pictures of the tasks after teaching was completed, to determine how much of the surfaces were cleared by participants’ kinesthetic demonstrations. However, we explored the possibility of estimating demonstrations’ success obtained from a computational approach which was based on automatically processing the robot’s joint motion data. Although the computational estimates were highly correlated with the subjective success of the demonstrations, they were noticeably lower than the subjective evaluations in Tasks 1 and 2. It is possible that this difference is due to the computational estimates not accounting for particle interactions (interactions among those particles involved in Tasks 1 and 2) and the three-dimensional nature of the tasks, thus affecting only those tasks. For example, a few pieces of paper could be pushed aside easily at once if they were close together. Because there were no particles involved in cleaning the whiteboard, the sponge could only clean the areas that came into contact with the whiteboard when enough force was applied. Despite this shortcoming, which suggests that the accuracy of the proposed computational method could be affected by the nature of the task, the computational method still allows tracking teachers’ progress and success automatically and reliably by the robot itself, despite the possibility of underestimating the success of demonstrations. Thus, this method could be useful in future experiments, applications, and/or field studies, as it does not require manual coding of data. This method can be useful, particularly in realistic settings that lack an accurate vision system, where varying and unpredictable lighting conditions exist (e.g, in a real home, healthcare, or work setting) or when a vision system is not desirable due to privacy considerations, such as in a home.
6.5.2 Cleaning Tasks Used in this Experiment
Some of the reported results suggest specific differences between the tasks that involved cleaning the whiteboard (Tasks 3 and 4) and those that involved cleaning an area of a table (Tasks 1 and 2), as reflected in (a) the higher success rates of Tasks 3 and 4, even in the early sessions, (b) a lower percentage of fixations on the robot’s hand when teaching Tasks 1 and 2 in a majority of sessions, and (c) more frequent changes in the teaching strategies when teaching Tasks 1 and 2 compared to Tasks 3 and 4 in early sessions. This implies that participants might have found it harder to come up with a successful way of teaching Tasks 1 and 2. Teaching cleaning tasks on the table might have been more challenging than on the whiteboard, possibly due to differences between the same tasks done on horizontal versus vertical surfaces. Because the order of the tasks was fixed, another possibility for easier teaching of Tasks 3 and 4 could be that participants got used to teaching the robot the first two tasks before moving on to the other two tasks.
6.5.3 Data Collection by the Robot Itself
Data analyzed in this experiment (excluding the questionnaires) were obtained from two primary sources aside from the robot: eye-tracking glasses to record participants’ gaze targets and videos of the sessions to identify the location of participants’ hands on the arm of the robot and also the success of demonstrations. However, a remote gaze-estimation system [58], if installed on a robot, e.g. [59], could replace eye tracking glasses to evaluate the gaze direction of a human teacher. The robot may then compare that gaze direction with the location of its hand, to detect how long the teacher has fixated on the robot’s hand during teaching. A robot equipped with touch-sensitive skin [32] on its arm, e.g., an updated iCub robot [41], could detect if two areas of its arm are touched, to track the usage of both hands, and sense if its upper arm is guided, or its hand is not guided, while being kinesthetically taught by a human teacher. This would eliminate the need to have a camera and manually annotate videos to obtain data on manipulation strategies, while also gathering information that can be informative for understanding performance and behaviour change of non-expert teachers. For the success of demonstrations, we offered here a computational alternative to subjective evaluations of snapshots of the tasks. Sensing and analyzing the data presented in this work by a robot itself would enable it to track the progress of its teachers during teaching, and this information might be useful for learning selectively from available teachers.
6.5.4 The Question of Who to Imitate
As noted early in the paper, the ultimate goal of our line of research is to identify who is a good teacher for robots. Preferably, the evaluation and selection of good human teachers would be done by the robot itself. In order to accomplish this, we investigated our data at a more individual level and identified three clusters of high-achievers, improving, and low-achievers, based on participants’ success in teaching two of the challenging tasks in our experiment, i.e., how to clean areas of a table. According to this diversity in teaching styles for our cleaning tasks, a human teacher who uses both their hands for teaching, guides the robot’s upper arm (and even more frequently after repeated interactions), and dynamically adjusts their way of holding a robot’s arm is more likely to belong to a high-achiever cluster and thus provide successful task demonstrations. As discussed in Sect. 6.5.3, a robot may be able to capture those data to make inferences and potentially identify better human teachers.
7 Limitations
The presented work had several limitations. To begin with, while recruiting participants for such a multiple-session HRI study is challenging, the study could benefit from the participation of the general public rather than recruiting university students only, who might have been positively biased toward using robots and who are generally more familiar with new technologies. As previously pointed out, most of the participants in our study were of a certain age range (i.e., university students between the ages of 18 and 31). This might have contributed to the result that only a few participants were in the low-achievers cluster. If the same study had been conducted on a different population, the composition of clusters could have been different. The inclusion of people other than university students could address this issue and more accurately reveal the possible effects of age and background differences on the behaviours and performance of human teachers for robots.
There is also a limitation that the robot in our experiment had no actual learning mechanism. If the robot had not given any feedback after participants taught the 4 tasks, the experiment could have been boring for participants, especially since they had to participate in five sessions. For this reason, the robot was pre-programmed to provide coarse-level feedback to participants by executing a single task at the end of every session with the purpose of giving the impression that their demonstrations had an impact on the robot. In this situation, the robot’s behaviour did not match exactly each participant’s demonstration skills during the session, despite being selected by the experimenter based on the participants’ performance. After being told in the debriefing stage that the robot was not actually learning, a few participants mentioned they had suspicions about the learning capabilities of the robot. According to them, this was mainly due to the fact that the robot’s performance was not exactly the same as their demonstrations. However, this might be the case even with a real robot learning system: the resulting learned robot behaviour would likely be based on a set of demonstrations and therefore, the learned behaviour would be different from one’s own instructions. Still, if the robot in our experiment had been capable of actual learning in between sessions and providing feedback based on what was learned from participants’ teaching in the previous session, this feedback would have affected how participants would teach the robot in subsequent teaching sessions. Such a system could help participants gain a better understanding of how their instructions help the robot improve its performance.
This study also had limitations regarding data analysis. There might be a risk of bias in the self-reported data used for assessing participants’ workload. Moreover, as noted in Sect. 4.3.2, the gaze recordings of participants were only processed according to the amount of time they fixated on the hand of the robot. Localizing other areas of interest, e.g., the arm and body of the robot, could allow a more comprehensive analysis of human teachers’ gaze during robot teaching. The behavioural data on manipulation and teaching strategy could also be analyzed more precisely, by considering multiple states for the placement of the human teacher’s hand. To improve these aspects in the future, computational data processing using artificial intelligence techniques may be required instead of manual coding of the data, which presented its own challenges (e.g., being a lengthy process, ensuring sufficient agreement between two raters, etc.).
In the present experiment, one type of task was considered: wiping surfaces as part of cleaning tasks. While we included both vertical and horizontal surfaces and varied the difficulty of the tasks and types of particles that needed to be cleaned, different types of teaching tasks may produce different results. Studies in the future may explore teaching a robot other tasks with a wider range of motions and multiple actions, as needed to be carried out in more realistic settings, such as in a kitchen (e.g., preparing a meal or drink).
8 Future Work
In this study, we discovered that the majority of our inexperienced and unsupervised participants could gradually become more proficient robot teachers by repeatedly teaching a humanoid robot, and we explained how this might happen, based on the physical characteristics of the actions and behaviours of the human teachers. Future studies may recruit participants with various levels of experience with robots to study how exposure to robots and different participant backgrounds could affect teaching behaviours.
Including actual robot learning in such a work is an important topic to study in the future, which was not the focus of our present experiment. Involving a robot equipped with machine learning could further explore the relationship between a robot learning while being taught skills by human teachers, and how the human teachers’ teaching changes over time. When using a real learning robot, it may be necessary to reconsider some aspects of the present study. For instance, some other metrics for evaluating the success of demonstrations, mostly concerning machine learning aspects, e.g., [19, 57], could be used. Moreover, due to a lack of precision in sensing and actuation, the Pepper robot might not be the best choice for learning fine motor skills including forces. However, there is a trade-off between using a robot, such as Pepper, suitable to be used safely in realistic, unsupervised scenarios, as compared to more sophisticated and capable robots, possibly with more degrees of freedom or non-human-like configuration of the joints, that cannot be used safely and reliably in settings other than laboratory and/or highly supervised environments. The adaptation of non-experts when teaching different types of robots can be explored in future research.
The robot in our study only provided minimal instructions to participants on how to teach it and the behavioural feedback it gave included prerecorded actions (although they were matched with the participant’s performance by the experimenter). In future work, such feedback can be generated based on what has been learned, in case a robot is capable of actually learning. In the absence of robot learning, prerecorded actions for the behavioural feedback could be selected by the robot itself, e.g., by automatically assessing the number of particles cleaned from the tasks. Efforts can also be made in the future to improve humans teaching robots by utilizing certain strategies, e.g., by means of the robot providing social and communicative feedback to the teachers (e.g. using verbal and/or non-verbal cues), or enabling social learning through feedback that communicates the robot’s learning process or internal states [13]. A robot could adjust its strategies according to the type of user among the identified clusters it believes it is interacting with.
We took our first step towards addressing the problem of ‘who to imitate’ in kinesthetic robot teaching, which is a complex and multi-faceted challenge. We presented findings from a sample of 28 human teachers in the specific context of teaching a robot how to clean surfaces. To continue research direction in future, many aspects will need to be considered. In particular, context and domain should be considered when determining whether a human teacher is a good choice for a robot to learn from. People might have strengths and weaknesses in certain domains, and therefore, show varied performances when teaching robots different tasks. Personality, education, and other individual characteristics might play a role, too.
9 Conclusion
This study targeted human participants who had no previous experience teaching robots and examined how repeated human–robot interactions in physically teaching a robot can affect the speed and success of teaching, human teachers’ gaze behaviour, manipulative strategies, and perceived workload. In other words, we asked if non-experts can adapt their strategies and learn how to teach robots through repeated kinesthetically teaching of a robot. Based on our results, the answer is: the majority of non-experts can. While nearly one-third of our non-expert participants were good at teaching our tasks to the robot from the start, our results showed that it was not too difficult for a majority of the other participants to adapt to robot teaching and improve their teaching without being given any formal training, but rather by experiencing robot teaching on their own over a few sessions of unsupervised teaching.
Although we know from the literature that it is possible to train human teachers explicitly in order to improve robot teaching [15, 51], we demonstrated that allowing participants to explore the teaching task and adapt to a robot over time is effective as an implicit, unsupervised strategy of training human teachers. Allowing users to explore robot teaching, rather than being trained on how to do it, might be a good option in certain settings and applications, particularly where safety risks for both humans and robots are low. We further illustrated how exactly changes in multiple aspects of human teachers’ teaching behaviour might occur as they became more experienced robot teachers. These insights could be used by robots in the future to track their human teachers’ progress and experience.
We learned that non-expert robot users react in diverse ways when kinesthetically teaching a robot over multiple sessions. Some may be good from the start, some may improve, and some may struggle throughout. We showed that some aspects of human teachers’ behaviour might be useful for identifying the most suitable teachers for robots. For example, we found that more successful robot teachers tend to use both hands for teaching more, and they change their hand placement on the robot’s arm more often. Roboticists could use our methods and findings to enable a robot to track human teachers’ progress and level of experience, so that the robot can identify better human teachers (i.e., high-achievers) to potentially result in better robot learning outcomes.
Data availability
The dataset analyzed during the current study is available from the corresponding author on request. [We would include the video submitted for review in the final accepted version.]
Change history
15 October 2024
A Correction to this paper has been published: https://doi.org/10.1007/s12369-024-01182-6
Notes
To date, some effort has been made to address the ‘who to imitate’ question in imitation learning through approaches other than computational modelling or machine learning. For example, a teacher’s engagement has been proposed as a metric to define a good teacher for robots [44]. However, there is still no conclusive answer to the problem.
The size and the positioning of the cutting boards and the areas in the whiteboard were chosen to be within the workspace of the robot’s left arm and were fixed for all participants. In Tasks 2 and 4, compared to Tasks 1 and 3, those areas were extended to the right side and included areas that were harder to reach for the robot’s left hand. This required participants to use both hands when teaching Tasks 2 and 4 in order to adjust at least two degrees of freedom in the robot’s arm for more effectively covering the whole area.
The robot performance was not intended to give examples of potentially effective ways of executing the task, and it was not meant to reflect precisely on how the participant had taught the robot in tasks 1 and 2. Instead, coarse-level feedback was given in the sense that the robot’s performance was at most as successful in accomplishing the task as each participant’s individual demonstrations in Tasks 1 and 2. Participants only watched the feedback and were not given any additional insight into their teaching. Note, employing real-time learning of robot movements from the two demonstrations in Tasks 1 and 2 goes beyond the scope of this study which takes a human-centred approach.
We used pieces of paper, paper clips, safety pins, binder clips, and buttons distributed on the cutting boards, as well as a set of horizontal or vertical lines, cross-hatching pattern, small circles, and random handwritten letters drawn on the whiteboard.
The descriptions of the tasks and the instructions stated by the robot became shorter after the third session to avoid fatigue, as the participants were already familiar with the procedure.
On average, there were 4.11 (SD=2.75) days between successive sessions for a participant.
People who used medical devices that were susceptible to disturbance by infrared light and/or radiation, people with photosensitive epilepsy, and people who had implanted medical devices were excluded in order to eliminate participants’ safety risks due to proximity to the robot and the measuring devices.
In most of the cases that led to data loss in gaze recording, Tobii glasses could not detect the eyes properly when a participant was looking down as a result of standing close to the robot and teaching a task on a short table.
The success of Tasks 3 and 4, i.e., clearing areas of the whiteboard, was not considered as almost all participants provided highly successful demonstrations (see Fig. 5). Therefore, it could make it difficult to distinguish between participants’ performances.
Task nature and task order together uniquely define the task. In each level of task nature, i.e., cleaning the table or the board, the one with the larger task order is cleaning the bigger surface.
Measures concerning RQ4 did not follow a normal distribution for our participant pool. The LMM analysis is therefore limited to improving participants only.
References
Ajaykumar G, Steele M, Huang CM (2021) A Survey on End-User Robot Programming. ACM Comput Surv. https://doi.org/10.1145/3466819
Aldebaran (2023) Cartesian control API. http://doc.aldebaran.com/2-1/naoqi/motion/control-cartesian-api.html. Accessed on Mar 2, 2023
Aldebaran (2023a) Choregraphe. http://doc.aldebaran.com/1-14/software/choregraphe/choregraphe_overview.html. Accessed on Apr 15, 2023
Aldebaran (2023b) Pepper the humanoid and programmable robot. https://www.aldebaran.com/en/pepper. Accessed on Mar1, 2023
Aliasghari P, Ghafurian M, Nehaniv CL, Dautenhahn K (2022) Impact of nonverbal robot behaviour on human teachers’ perceptions of a learner robot. Interact Stud 22(2):141–176. https://doi.org/10.1075/is.20036.ali
Aliasghari P, Ghafurian M, Nehaniv CL, Dautenhahn K (2023) Kinesthetic teaching of a robot over multiple sessions: impacts on speed and success. In: Social robotics: 14th international conference (ICSR ‘22). Springer, pp 160–170, https://doi.org/10.1007/978-3-031-24670-8_15
Argall BD, Chernova S, Veloso M, Browning B (2009) A survey of robot learning from demonstration. Robot Auton Syst 57(5):469–483. https://doi.org/10.1016/j.robot.2008.10.024
Bates D, Mächler M, Bolker BM, Walker SC (2015) Fitting linear mixed-effects models using lme4. J Stat Softw. https://doi.org/10.18637/jss.v067.i01
Billard A, Calinon S, Dillmann R, Schaal S (2008) Robot Programming by Demonstration. In: Siciliano B, Khatib O (eds) Springer handbook of robotics. Springer, p 1371–1394, https://doi.org/10.1007/978-3-540-30301-5_60
Billard AG, Calinon S, Dillmann R (2016) Learning from humans. In: Siciliano B, Khatib O (eds) Springer handbook of robotics (2nd ed). Springer, p 1995–2014,https://doi.org/10.1007/978-3-319-32552-1_74
Bozdogan H (1987) Model selection and Akaike’s Information Criterion (AIC): the general theory and its analytical extensions. Psychometrika 52(3):345–370. https://doi.org/10.1007/BF02294361
Bradski G (2000) The openCV library. Dr Dobb’s J Softw Tools Prof Programm 25(11):120–123
Breazeal C (2009) Role of expressive behaviour for robots that learn from people. Philosoph Trans R Soc B Biol Sci 364(1535):3527–3538. https://doi.org/10.1098/rstb.2009.0157
Breazeal C, Dautenhahn K, Kanda T (2016) Social robotics. In: Siciliano B, Khatib O (eds) Springer handbook of robotics (2nd ed). Springer, p 1935–1972, https://doi.org/10.1007/978-3-319-32552-1_72
Cakmak M, Takayama L (2014) teaching people how to teach robots: the effect of instructional materials and dialog design. In: Proceedings of the 2014 ACM/IEEE international conference on human-robot interaction. ACM, HRI ’14, p 431–438,https://doi.org/10.1145/2559636.2559675
Cakmak M, Thomaz AL (2014) Eliciting good teaching from humans for machine learners. Artif Intell 217:198–215. https://doi.org/10.1016/j.artint.2014.08.005
Calinon S, Billard A (2007) Learning of gestures by imitation in a humanoid robot. In: Nehaniv CL, Dautenhahn K (eds) Imitation and social learning in robots, humans and animals: behavioural, social and communicative dimensions. Cambridge University Press, p 153–178, https://doi.org/10.1017/CBO9780511489808.012
Chen TL, Kemp CC (2010) Lead me by the hand: evaluation of a direct physical interface for nursing assistant robots. In: HRI ’10: proceedings of the 5th ACM/IEEE international conference on human-robot interaction. IEEE, p 367–374, https://doi.org/10.1109/HRI.2010.5453162
Cho S, Jo S (2013) Incremental online learning of robot behaviors from selected multiple kinesthetic teaching trials. IEEE Trans Syst Man Cybern Syst 43(3):730–740. https://doi.org/10.1109/TSMCA.2012.2207108
Dautenhahn K, Nehaniv CL (2002) The agent-based perspective on imitation. In: Dautenhahn K, Nehaniv CL (eds) Imitation in animals and artifacts. MIT press, p 1–40, https://doi.org/10.7551/mitpress/3676.003.0002
Elor A, Kurniawan S, Takayama L (2022) Human experiences in teaching robots: understanding agent expressivity and learning effects through a virtual robot arm. In: 2022 IEEE International conference on smart computing (SMARTCOMP). IEEE, pp 133–141, https://doi.org/10.1109/SMARTCOMP55677.2022.00033
Emery N (2000) The eyes have it: the neuroethology, function and evolution of social gaze. Neurosci Biobehav Rev 24(6):581–604. https://doi.org/10.1016/S0149-7634(00)00025-7
Fischer K, Kirstein F, Jensen LC, Krüger N, Kukliński K, aus der Wieschen MV, Savarimuthu TR (2016) A comparison of types of robot control for programming by demonstration. In: 11th ACM/IEEE international conference on human-robot interaction. IEEE, HRI ’16, p 213–220, https://doi.org/10.1109/HRI.2016.7451754
Friard O, Gamba M (2016) BORIS: a free, versatile open-source event-logging software for video/audio coding and live observations. Methods Ecol Evol 7(11):1325–1330. https://doi.org/10.1111/2041-210X.12584
Giuliani M, Mirnig N, Stollnberger G, Stadler S, Buchner R, Tscheligi M (2015) Systematic analysis of video data from different human-robot interaction studies: a categorization of social signals during error situations. Front Psychol. https://doi.org/10.3389/fpsyg.2015.00931
Gopalan N, Moorman N, Natarajan M, Gombolay M (2023) Negative result for learning from demonstration: challenges for end-users teaching robots with task and motion planning abstractions. In: RSS 2023 workshop on learning for task and motion planning, https://roboticsconference.org/2022/program/papers/028/
Grollman DH, Billard A (2011) Donut as I do: Learning from failed demonstrations. In: 2011 IEEE international conference on robotics and automation (ICRA 2011). IEEE, pp 3804–3809, https://doi.org/10.1109/ICRA.2011.5979757
Hart SG (2006) Nasa-Task Load Index (NASA-TLX); 20 Years Later. In: Proceedings of the human factors and ergonomics society annual meeting, vol 50. Sage Publications, p 904–908, https://doi.org/10.1177/154193120605000909
Hart SG, Staveland LE (1988) Development of NASA-TLX (Task Load Index): results of empirical and theoretical research. In: Human mental workload, advances in psychology, vol 52. North-Holland, p 139–183, https://doi.org/10.1016/S0166-4115(08)62386-9
Hedlund E, Johnson M, Gombolay M (2021) The effects of a robot’s performance on human teachers for learning from demonstration tasks. In: HRI ’21: Proceedings of the 2021 ACM/IEEE international conference on human-robot interaction. ACM, p 207–215, https://doi.org/10.1145/3434073.3444664
Hoehl S, Keupp S, Schleihauf H, McGuigan N, Buttelmann D, Whiten A (2019) ‘Over-imitation’: a review and appraisal of a decade of research. Dev Rev 51:90–108. https://doi.org/10.1016/j.dr.2018.12.002
Hoshi T, Shinoda H (2006) Robot skin based on touch-area-sensitive tactile element. In: Proceedings of 2006 IEEE international conference on robotics and automation (ICRA 2006). IEEE, pp 3463–3468, https://doi.org/10.1109/ROBOT.2006.1642231
Kaiser M, Friedrich H, Dillmann U (1995) Obtaining good performance from a bad teacher. In: Programming by demonstration vs. learning from examples workshop at ML’95
Kaochar T, Peralta RT, Morrison CT, Fasel IR, Walsh TJ, Cohen PR (2011) Towards understanding how humans teach robots. In: User modeling, adaption and personalization. Springer, pp 347–352, https://doi.org/10.1007/978-3-642-22362-4_31
Khan F, Zhu X, Mutlu B (2011) How do humans teach: on curriculum learning and teaching dimension. In: Proceedings of the 24th international conference on neural information processing systems. Curran Associates Inc., NIPS’11, p 1449–1457,https://doi.org/10.5555/2986459.2986621
Kidd CD, Breazeal C (2008) Robots at home: understanding long-term human-robot interaction. In: 2008 IEEE/RSJ International conference on intelligent robots and systems (IROS). IEEE, pp 3230–3235, https://doi.org/10.1109/IROS.2008.4651113
Knaust M, Koert D (2021) Guided robot skill learning: a user-study on learning probabilistic movement primitives with non-experts. In: 2020 IEEE-RAS 20th international conference on humanoid robots (humanoids). IEEE, pp 514–521, https://doi.org/10.1109/HUMANOIDS47582.2021.9555785
Koo TK, Li MY (2016) A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J Chiropr Med 15(2):155–163. https://doi.org/10.1016/j.jcm.2016.02.012
Krishna K, Murty MN (1999) Genetic K-means algorithm. IEEE Trans Syst Man Cybern Part B 29(3):433–439
Lukežic A, Vojír T, Zajc LC, Matas J, Kristan M (2017) Discriminative correlation filter with channel and spatial reliability. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 4847–4856, https://doi.org/10.1109/CVPR.2017.515
Metta G, Sandini G, Vernon D, Natale L, Nori F (2008) The iCub humanoid robot: an open platform for research in embodied cognition. In: Proceedings of the 8th workshop on performance metrics for intelligent systems. ACM, p 50–56, https://doi.org/10.1145/1774674.1774683
Moorman NM, Gopalan N, Singh A, Hedlund-Botti E, Schrum ML, Yang C, Seelam L, Gombolay M (2023) Investigating the impact of experience on a user’s ability to perform hierarchical abstraction. In: RSS 2023 Workshop on learning for task and motion planning, https://roboticsconference.org/program/papers/004/
Nehaniv CL, Dautenhahn K (2007) Introduction: the constructive interdisciplinary viewpoint for understanding mechanisms and models of imitation and social learning. Cambridge University Press. https://doi.org/10.1017/CBO9780511489808.001
Novanda O (2017) Metrics to evaluate human teaching engagement from a robot’s point of view. PhD thesis, University of Hertfordshire, Hertfordshire, UK, https://doi.org/10.18745/th.19624
OpenCV (2022) The CSRT tracker. https://docs.opencv.org/4.6.0/d2/da2/classcv_1_1TrackerCSRT.html#details. Accessed on Mar 25, 2023
Orendt EM, Fichtner M, Henrich D (2016) Robot programming by non-experts: intuitiveness and robustness of one-shot robot programming. In: 2016 25th IEEE international symposium on robot and human interactive communication (RO-MAN). IEEE, p 192–199, https://doi.org/10.1109/ROMAN.2016.7745110
Pais Ureche AL, Billard A (2015) Metrics for assessing human skill when demonstrating a bimanual task to a robot. In: Proceedings of the tenth annual ACM/IEEE international conference on human-robot interaction extended abstracts. ACM, HRI’15 Extended Abstracts, p 37–38, https://doi.org/10.1145/2701973.2702017
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay Édouard (2011) Scikit-learn: machine learning in python. J Mach Learn Res 12(85):2825–2830
Ramaraj P, Ortiz CL, Mohan S (2021) Unpacking human teachers’ intentions for natural interactive task learning. In: 2021 30th IEEE international conference on robot & human interactive communication (RO-MAN). IEEE, pp 1173–1180, https://doi.org/10.1109/RO-MAN50785.2021.9515448
Ravichandar H, Polydoros AS, Chernova S, Billard A (2020) Recent advances in robot learning from demonstration. Ann Rev Control Robot Autonom Syst 3(1):297–330. https://doi.org/10.1146/annurev-control-100819-063206
Sakr M, Freeman M, Van der Loos HFM, Croft E (2020) Training human teacher to improve robot learning from demonstration: a pilot study on kinesthetic teaching. In: 2020 29th IEEE international conference on robot and human interactive communication (RO-MAN). IEEE, pp 800–806, https://doi.org/10.1109/RO-MAN47096.2020.9223430
Sakr M, Li ZJ, Van der Loos HFM, Kulic D, Croft EA (2022) Quantifying demonstration quality for robot learning and generalization. IEEE Robot Autom Lett 7(4):9659–9666. https://doi.org/10.1109/LRA.2022.3191950
Saran A, Short ES, Thomaz A, Niekum S (2019) Understanding teacher gaze patterns for robot learning. In: Proceedings of conference on robot learning, vol 100. PMLR, pp 1247–1258, https://proceedings.mlr.press/v100/saran20a/saran20a.pdf
Saran A, Desai K, Chang ML, Lioutikov R, Thomaz A, Niekum S (2022) Understanding acoustic patterns of human teachers demonstrating manipulation tasks to robots. In: 2022 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 9172–9179, https://doi.org/10.1109/IROS47612.2022.9981053
Saunders J, Nehaniv CL, Dautenhahn K, Alissandrakis A (2007) Self-imitation and environmental scaffolding for robot teaching. Int J Adv Rob Syst 4(1):109–124. https://doi.org/10.5772/5703
Schrum ML, Hedlund-Botti E, Gombolay M (2023) Reciprocal mind meld: Improving learning from demonstration via personalized, reciprocal teaching. In: Proceedings of The 6th conference on robot learning, vol 205. PMLR, pp 956–966, https://proceedings.mlr.press/v205/schrum23a.html
Sena A, Howard M (2020) Quantifying teaching behavior in robot learning from demonstration. Int J Robot Res 39(1):54–72. https://doi.org/10.1177/0278364919884623
Shehu IS, Wang Y, Athuman AM, Fu X (2021) Remote eye gaze tracking research: a comparative evaluation on past and recent progress. Electronics. https://doi.org/10.3390/electronics10243165
Siegfried R, Aminian B, Odobez JM (2020) ManiGaze: a dataset for evaluating remote gaze estimator in object manipulation situations. In: ETRA ’20 Short Papers: ACM symposium on eye tracking research and applications. ACM, https://doi.org/10.1145/3379156.3391369
Sweller J (1994) Cognitive load theory, learning difficulty, and instructional design. Learn Instr 4(4):295–312. https://doi.org/10.1016/0959-4752(94)90003-5
Tobii (2023) Tobii Pro Glasses 2 wearable eye tracker. https://www.tobii.com/products/discontinued/tobii-pro-glasses-2. Accessed on Mar 7, 2023
Wrede S, Emmerich C, Grünberg R, Nordmann A, Swadzba A, Steil J (2013) A user study on kinesthetic teaching of redundant robots in task and configuration space. J Hum Robot Interact 2(1):56–81. https://doi.org/10.5898/JHRI.2.1.Wrede
Acknowledgements
This research was undertaken, in part, thanks to funding from the Canada 150 Research Chairs Program. The authors wish to also thank Delara Forghani and Ali Yamini for assisting with data encoding.
Funding
This research was undertaken, in part, thanks to funding from the Canada 150 Research Chairs Program.
Author information
Authors and Affiliations
Contributions
PA, MG, CLN, KD designed the study. PA implemented the apparatus, performed the experiment, conducted the data analysis, and drafted the manuscripts. MG, CLN and KD reviewed and edited the manuscripts, and also supervised the project.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no Conflict of interest to declare that are relevant to the content of this article.
Ethical Approval
The study received full ethics clearance from the University of Waterloo Human Research Ethics Board. All the participants gave informed consent ahead of their first visit for the experiment.
Consent for Publication
Not applicable.
Materials Availability
Not applicable.
Code Availability
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary file 1 (mp4 26013 KB)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Aliasghari, P., Ghafurian, M., Nehaniv, C.L. et al. How Non-experts Kinesthetically Teach a Robot over Multiple Sessions: Diversity in Teaching Styles and Effects on Performance. Int J of Soc Robotics 16, 2079–2105 (2024). https://doi.org/10.1007/s12369-024-01164-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12369-024-01164-8