
Abstract
We present two algorithms to solve the Group Lasso problem (Yuan and Lin in, J R Stat Soc Ser B (Stat Methodol) 68(1):49–67, 2006). First, we propose a general version of the Block Coordinate Descent (BCD) algorithm for the Group Lasso that employs an efficient approach for optimizing each subproblem exactly. We show that it exhibits excellent performance when the groups are of moderate size. For groups of large size, we propose an extension of ISTA/FISTA SIAM (Beck and Teboulle in, SIAM J Imag Sci 2(1):183–202, 2009) based on variable step-lengths that can be viewed as a simplified version of BCD. By combining the two approaches we obtain an implementation that is very competitive and often outperforms other state-of-the-art approaches for this problem. We show how these methods fit into the globally convergent general block coordinate gradient descent framework in Tseng and Yun (Math Program 117(1):387–423, 2009). We also show that the proposed approach is more efficient in practice than the one implemented in Tseng and Yun (Math Program 117(1):387–423, 2009). In addition, we apply our algorithms to the Multiple Measurement Vector (MMV) recovery problem, which can be viewed as a special case of the Group Lasso problem, and compare their performance to other methods in this particular instance.






Similar content being viewed by others

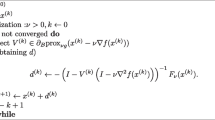
Notes
References
Bach, F.: Consistency of the group Lasso and multiple kernel learning. J. Mach. Learn. Res. 9, 1179–1225 (2008)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imag. Sci. 2(1), 183–202 (2009)
van den Berg, E., Friedlander, M.: Joint-sparse recovery from multiple measurements. arXiv 904 (2009)
van den Berg, E., Friedlander, M.: Sparse Optimization With Least-squares Constraints. Tech. rep., Technical Report TR-2010-02, Department of Computer Science, University of British Columbia, Columbia (2010)
van den Berg, E., Schmidt, M., Friedlander, M., Murphy, K.: Group sparsity via linear-time projection. Tech. rep., Technical Report TR-2008-09, Department of Computer Science, University of British Columbia, Columbia (2008)
Candès, E., Romberg, J., Tao, T.: Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. Inform Theory IEEE Trans 52(2), 489–509 (2006)
Chen, J., Huo, X.: Theoretical results on sparse representations of multiple-measurement vectors. IEEE Trans. Signal Process. 54, 12 (2006)
Dolan, E., Moré, J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002)
Donoho, D.: Compressed sensing, information theory. IEEE Trans. 52(4), 1289–1306 (2006)
Friedman, J., Hastie, T., Tibshirani, R.: A note on the group lasso and a sparse group lasso. preprint, Leipzig (2010)
Jacob, L., Obozinski, G., Vert, J.: Group Lasso with overlap and graph Lasso. In: Proceedings of the 26th Annual International Conference on Machine Learning, ACM, New York, pp. 433–440 (2009)
Kim, D., Sra, S., Dhillon, I.: A scalable trust-region algorithm with application to mixed-norm regression. vol. 1. In: Internetional Conference Machine Learning (ICML), Atlanta (2010)
Kim, S., Xing, E.: Tree-guided group lasso for multi-task regression with structured sparsity. In: Proceedings of the 27th Annual International Conference on, Machine Learning, New York (2010)
Liu, J., Ji, S., Ye, J.: Multi-task feature learning via efficient l 2, 1-norm minimization. In: Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, AUAI Press, Corvallis, pp. 339–348 (2009)
Liu, J., Ji, S., Ye, J.: SLEP: Sparse Learning with Efficient Projections. Arizona State University, Arizona (2009)
Ma, S., Song, X., Huang, J.: Supervised group Lasso with applications to microarray data analysis. BMC bioinformatics 8(1), 60 (2007)
Meier, L., Van De Geer, S., Buhlmann, P.: The group lasso for logistic regression. J. Royal Stat. Soc. Ser. B (Stat. Methodol.) 70(1), 53–71 (2008)
Moré, J., Sorensen, D.: Computing a trust region step. SIAM J. Sci. Statist. Comput. 4, 553 (1983)
Nesterov, Y.: Efficiency of coordinate descent methods on huge-scale optimization problems. CORE Discussion Papers, Belgique (2010)
Nocedal, J., Wright, S.: Numerical optimization. Springer verlag, New York (1999)
Rakotomamonjy, A.: Surveying and comparing simultaneous sparse approximation (or group-lasso) algorithms. Sig. Process. 91(7), 1505–1526 (2011)
Richtárik, P., Takáč, M.: Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function. Arxiv, preprint arXiv:1107.2848 (2011)
Roth, V., Fischer, B.: The group-lasso for generalized linear models: uniqueness of solutions and efficient algorithms. In: Proceedings of the 25th international conference on Machine learning, ACM, Bellevue, pp. 848–855 (2008)
Subramanian, A., Tamayo, P., Mootha, V., Mukherjee, S., Ebert, B., Gillette, M., Paulovich, A., Pomeroy, S., Golub, T., Lander, E., et al.: Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl Acad. Sci. U.S.A. 102(43), 15,545 (2005)
Sun, L., Liu, J., Chen, J., Ye, J.: Efficient Recovery of Jointly Sparse Vectors. NIPS, Canada, (2009)
R, Tibshirani: Regression shrinkage and selection via the lasso. J. Royal Statist. Soc. Ser. B (Methodol.) 58(1), 267–288 (1966)
Tseng, P.: Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 109(3), 475–494 (2001)
Tseng, P., Yun, S.: A coordinate gradient descent method for nonsmooth separable minimization. Math. Program. 117(1), 387–423 (2009)
Van De Vijver, M., He, Y., van’t Veer, L., Dai, H., Hart, A., Voskuil, D., Schreiber, G., Peterse, J., Roberts, C., Marton, M., et al.: A gene-expression signature as a predictor of survival in breast cancer. N. Engl. J. Med. 347(25), 1999 (2002)
Vandenberghe, L.: Gradient methods for nonsmooth problems. EE236C course notes (2008)
Wright, S., Nowak, R., Figueiredo, M.: Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 57(7), 2479–2493 (2009)
Yang, H., Xu, Z., King, I., Lyu, M.: Online learning for group lasso. In: 27th Intl Conf. on Machine Learning (ICML2010). Citeseer (2010)
Yuan, M., Lin, Y.: Model selection and estimation in regression with grouped variables. J. Royal Statist. Soc. Ser. B (Statist. Methodol.) 68(1), 49–67 (2006)
Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. Royal Statist. Soc. Ser. B (Statist. Methodol.) 67(2), 301–320 (2005)
Acknowledgments
We would like to thank Shiqian Ma for valuable discussions on the MMV problems. We also thank the two anonymous reviewers for their constructive comments, which improved this paper significantly.
Author information
Authors and Affiliations
Corresponding author
Additional information
Research supported in part by NSF Grants DMS 06-06712 and DMS 10-16571, ONR Grant N00014-08-1-1118 and DOE Grant DE-FG02-08ER25856 and AFOSR Grant FA9550-11-1-0239.
Appendices
Appendix A: Simulated Group Lasso data sets
For the specifications of the data sets in Table 2, interested readers can refer to the references provided at the beginning of Sect. 7.1. Here, we provide the details of the data sets in Table 3.
1.1 A.1 yl1L
50 latent variables \(Z_{1}, \ldots , Z_{50}\) are simulated from a centered multivariate Gaussian distribution with covariance between \(Z_{i}\) and \(Z_{j}\) being \(0.5^{|i-j|}\). The first 47 latent variables are encoded in \(\{0,\ldots ,9\}\) according to their inverse cdf values as done in [33]. The last three variables are encoded in \(\{0,\ldots ,999\}\). Each latent variable corresponds to one segment and contributes \(L\) columns in the design matrix with each column \(j\) containing values of the indicator function \(I(Z_{i}=j)\). \(L\) is the size of the encoding set for \(Z_{i}\). The responses are a linear combination of a sparse selection of the segments plus a Gaussian noise. We simulate 5,000 observations.
1.2 A.2 yl4L
110 latent variables are simulated in the same way as the third data set in [33]. The first 50 variables contribute 3 columns each in the design matrix \(A\) with the \(i\)-th column among the three containing the \(i\)-th power of the variable. The next 50 variables are encoded in a set of 3, and the final 10 variables are encoded in a set of 50, similar to yl1L. In addition, 4 groups of 1,000 Gaussian random numbers are also added to \(A\). The responses are constructed in a similar way as in yl1L. 2,000 observation are simulated.
1.3 A.3 mgb2L
5,001 variables are simulated as in yl1L without categorization. They are then divided into six groups, with first containing one variable and the rest containing 1,000 each. The responses are constructed in a similar way as in yl1L. We collect 2,000 observations.
1.4 A.4 ljyL
We simulate 15 groups independent standard Gaussian random variables. The first five groups are of a size 5 each, and the last 10 groups contain 500 variables each. The responses are constructed in a similar way as in yl1L, and we simulate 2,000 observations.
1.5 A.5 glassoL1, glassoL2
The design matrix \(A\) is drawn from the standard Gaussian distribution. The length of each group is sampled from the uniform distribution \(U(10,50)\) with probability 0.9 and from the uniform distribution \(U(50,300)\) with probability 0.1. We continue to generate the groups until the specified number of features \(m\) is reached. The ground truth feature coefficients \(x^*\) is generated from \(\mathcal N (2,4)\) with approximately \(5~\%\) non-zero values, and we assume a \(\mathcal N (0.5,0.25)\) noise.
Appendix B: MMV scalability test sets
The data sets in Table 5 are generated in the same say with different attributes. Both the design matrix \(A\) and the non-zeros rows in the ground truth \(X_0\) are drawn from the standard Gaussian distribution. The indices of the non-zero rows in \(X_0\) are uniformly sampled. The measurement matrix \(B\) is obtained by \(B = AX_0\). The data attributes, such as the number of measurements and the sparsity level of the ground truth, are set to ensure that the exact solution is recoverable by the MMV model.
Rights and permissions
About this article
Cite this article
Qin, Z., Scheinberg, K. & Goldfarb, D. Efficient block-coordinate descent algorithms for the Group Lasso. Math. Prog. Comp. 5, 143–169 (2013). https://doi.org/10.1007/s12532-013-0051-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12532-013-0051-x
Keywords
- Block coordinate descent
- Group Lasso
- Iterative shrinkage thresholding
- Multiple measurement vector
- Line-search