
Abstract
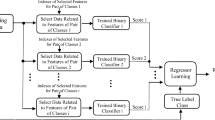
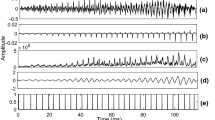
This paper proposes a novel speech emotion recognition (SER) framework for affective interaction between human and personal devices. Most of the conventional SER techniques adopt a speaker-independent model framework because of the sparseness of individual speech data. However, a large amount of individual data can be accumulated on a personal device, making it possible to construct speaker-characterized emotion models in accordance with a speaker adaptation procedure. In this study, to address problems associated with conventional adaptation approaches in SER tasks, we modified a representative adaptation technique, maximum likelihood linear regression (MLLR), on the basis of selective label refinement. We subsequently carried out the modified MLLR procedure in an online and iterative manner, using accumulated individual data, to further enhance the speaker-characterized emotion models. In the SER experiments based on an emotional corpus, our approach exhibited performance superior to that of conventional adaptation techniques as well as the speaker-independent model framework.







Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Suprateek S, John D. Understanding mobile handheld device use and adoption. Commu ACM. 2003;46:35–40.
Ballagas R, Borchers J, Rohs M, Jennifer G. The smart phone: ubiquitous input device. IEEE Pervasive Comput. 2006;5:70–7.
Mark A, Streefkerk J. Interacting in desktop and mobile context: emotion, trust, and task performance. Ambient Intell. 2003;2875:119–32.
Pittermann J, Pittermann A, Minker W. Handing emotions in human–computer dialogues. Berlin: Springer; 2010. p. 19–42.
Park JS, Kim JH, Oh YH. Feature vector classification based speech emotion recognition for service robots. IEEE Trans Consum Electron. 2009;55:1590–6.
Ignacio LM, Carlos OR, Joaquin GR, Daniel R. Speaker dependent emotion recognition using prosodic supervectors. In: Proceedings of interspeech; 2009. pp. 1971–4.
Nwe TL, Foo SW, Silva LCD. Speech emotion recognition using hidden Markov models. Speech Commun. 2003;41:603–23.
Ververidis D, Kotropoulos C. Emotional speech recognition: resources, features, and methods. Speech Commun. 2006;48:1162–81.
Kwon O, Chan K, Hao J, Lee T. Emotion recognition by speech signals. In: Proceedings of Eurospeech; 2003. pp. 125–8.
Tato R, Santos R, Kompe R, Pardo JM. Emotional space improves emotion recognition. In: Proceedings of the international conference on spoken language processing (ICSLP); 2002. pp. 2029–32.
Huang R, Ma C. Toward a speaker-independent real time affect detection system. In: Proceedings of international conference on pattern recognition (ICPR); 2006. pp. 1204–7.
Leggetter CJ, Woodland PC. Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models. Comput Speech Lang. 1995;9:171–85.
Woodland PC, Pye D, Gales MJF. Iterative unsupervised adaptation using maximum likelihood linear regression. In: Proceedings of international conference on spoken language processing (ICSLP); 1996. pp. 1133–6.
Lee CH, Lin CH, Juang BH. A study on speaker adaptation of the parameters of continuous density hidden markov models. IEEE Trans Signal Process. 1991;39:806–14.
Matsui T, Furui S. N-best-based unsupervised speaker adaptation for speech recognition. Comput Speech Lang. 1998;12:41–50.
Anastasakos T, Balakrishnan SV. The use of confidence measures in unsupervised adaptation of speech recognizers. In: Proceedings of international conference on spoken language processing (ICSLP); 1998. pp. 2303–6.
Grimm M, Kroschel K, Mower E, Narayanan S. Primitives-based evaluation and estimation of emotions in speech. Speech Commun. 2007;49:787–800.
Jiang H. Confidence measures for speech recognition: a survey. Speech Commun. 2005;45:455–70.
Pitz M, Wessel F, Ney H. Improved MLLR speaker adaptation using confidence measures for conversational speech recognition. In: Proceedings of international conference on spoken language processing (ICSLP); 2000. pp. 548–51.
Gollan C, Bacchiani M. Confidence scores for acoustic model adaptation. In: Proceedings of international conference on acoustics, speech, and signal processing (ICASSP); 2008, pp. 4289–92.
Liberman M, Davis K, Grossman M, Martey N, Bell J. Emotional prosody speech and transcripts. In: Linguistic data consortium (LDC). Philadelphia: University of Pennsylvania; 2002.
Acknowledgments
This study was financially supported by academic research fund of Mokwon University in 2012 and Defense Acquisition Program Administration and Agency for Defense Development under the contract.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Kim, JB., Park, JS. & Oh, YH. Speaker-Characterized Emotion Recognition using Online and Iterative Speaker Adaptation. Cogn Comput 4, 398–408 (2012). https://doi.org/10.1007/s12559-012-9132-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-012-9132-9