
Abstract
The aim of this article is to classify children’s affective states in a real-life non-prototypical emotion recognition scenario. The framework is the same as that proposed in the Interspeech 2009 Emotion Challenge. We used a large set of acoustic features and five linguistic parameters based on the concept of emotional salience. Features were extracted from the spontaneous speech recordings of the FAU Aibo Corpus and their transcriptions. We used a wrapper method to reduce the acoustic set of features from 384 to 28 elements and feature-level fusion to merge them with the set of linguistic parameters. We studied three classification approaches: a Naïve-Bayes classifier, a support vector machine and a logistic model tree. Results show that the linguistic features improve the performances of the classifiers that use only acoustic datasets. Additionally, merging the linguistic features with the reduced acoustic set is more effective than working with the full dataset. The best classifier performance is achieved with the logistic model tree and the reduced set of acoustic and linguistic features, which improves the performance obtained with the full dataset by 4.15 % absolute (10.14 % relative) and improves the performance of the Naïve-Bayes classifier by 9.91 % absolute (28.18 % relative). For the same conditions proposed in the Emotion Challenge, this simple scheme slightly improves a much more complex structure involving seven classifiers and a larger number of features.


Similar content being viewed by others
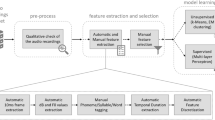
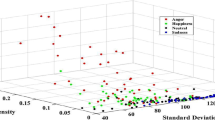

Notes
A chunk is a syntactically and semantically meaningful segment of an audio recording from the corpus. The chunks are defined manually based on syntactic and prosodic criteria [6].
References
Picard RW, Vyzas E, Healey J. Toward machine emotional intelligence: analysis of affective physiological state. IEEE Trans Pattern Anal Mach Intell. 2001;23(10):1175–1191.
Zeng Z, Pantic M, Roisman GI, Huang TS. A survey of affect recognition methods: audio, visual, and spontaneous expressions. IEEE Trans Pattern Anal Mach Intell. 2009;31(1):39–58.
Slaney M, McRoberts G. Baby Ears: a recognition system for affective vocalizations. 1998 IEEE international conference on acoustics speech and signal processing. 1998;p. 985–988.
Chetouani M, Mahdhaoui A, Ringeval F. Time-scale feature extractions for emotional speech characterization. Cognit Comput. 2009;1(2):194–201.
Wöllmer M, Eyben F, Schuller B, Douglas-Cowie E, Cowie R. Data-driven clustering in emotional space for affect recognition using discriminatively trained LSTM networks. In: 10th annual conference of the international speech communication association; 2009. p. 1595–1598.
Schuller B, Steidl S, Batliner A. The interspeech 2009 emotion challenge. In: 10th annual conference of the international speech communication association. Brighton, UK; 2009. p. 312–315.
Kostoulas T, Ganchev T, Lazaridis A, Fakotakis N. Enhancing emotion recognition from speech through feature selection. In: Sojka P, Hork A, Kopecek I, Pala K, editors. Text, speech and dialogue vol 6231 of LNCS. Heidelberg: Springer; 2010. p. 338–344.
Steidl S. Automatic classification of emotion-related user states in spontaneous children’s speech. Berlin: Logos Verlag; 2009.
Eyben F, Wöllmer M, Schuller B. OpenEAR—introducing the Munich open-source emotion and affect recognition toolkit. In: 4th international HUMAINE association conference on affective computing and intelligent interaction 2009. Amsterdam; 2009. p. 576–581.
Lee CM, Narayanan SS. Towards detecting emotions in spoken dialogs. IEEE Trans Audio Speech Lang Processing. 2005;13:293–303.
Yildirim S, Narayanan S, Potamianos A. Detecting emotional state of a child in a conversational computer game. Comput Speech Lang. 2011;25:29–44.
Witten IH, Frank E. Data mining: practical machine learning tools and techniques. 2nd ed. San Francisco, CA: Morgan Kaufmann; 2005.
Kim YS, Street N, Menczer F. Feature selection in data mining. In: Wang J, editor. Data mining opportunities and challenges. Hershey, PA: Idea Group Publishing; 2003. p. 80–105.
Snoek CGM, Worring M, Smeulders AWM. Early versus late fusion in semantic video analysis. In: 13th annual ACM international conference on multimedia. 2005;p. 399–402.
Guyon I, Elisseeff A. An introduction to variable and feature selection. J Mach Learn Res. 2003;3:1157–1182.
Planet S, Iriondo I, Socoró JC, Monzo C, Adell J. GTM-URL Contribution to the interspeech 2009 Emotion Challenge. In: 10th annual conference of the international speech communication association. Brighton, UK; 2009. p. 316–319.
Fayyad UM, Irani KB. Multi-interval discretization of continuous-valued attributes for classification learning. In: 13th international joint conference on artificial intelligence; 1993. p. 1022–1029.
Platt JC. Fast training of support vector machines using sequential minimal optimization. In: Schoelkopf B, Burges C, Smola A, editors. Advances in Kernel Methods-support vector learning. Cambridge, MA: MIT Press; 1998. p. 41–65.
Hastie T, Tibshirani R. Classification by pairwise coupling. Ann Stat. 1998;26(2):451–471.
Landwehr N, Hall M, Frank E. Logistic model trees. Mach Learn. 2005;59(1–2):161–205.
Schuller B, Batliner A, Steidl S, Seppi D. Recognising realistic emotions and affect in speech: state of the art and lessons learnt from the first challenge. Speech Communication. (2011 in press Corrected Proof).
Rish I. An empirical study of the Naïve-Bayes classifier. IJCAI 2001 Workshop on Empir Methods Artif Intell. 2001;3(22):41–46.
Kockmann M, Burget L, Černocký J. Brno University of Technology System for Interspeech 2009 Emotion Challenge. In: 10th annual conference of the international speech communication association. Brighton, UK; 2009. p. 348–351.
Schuller B, Batliner A, Steidl S, Seppi D. Emotion recognition from speech: putting ASR in the loop. In: Proceedings of the 2009 IEEE international conference on acoustics, speech and signal processing. ICASSP ’09. Washington, DC: IEEE Computer Society; 2009. p. 4585–4588.
Lu Y, Cohen I, Zhou XS, Tian Q. Feature selection using principal feature analysis. In: Proceedings of the 15th international conference on Multimedia. MULTIMEDIA ’07. New York, NY: ACM; 2007. p. 301–304.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Planet, S., Iriondo, I. Children’s Emotion Recognition from Spontaneous Speech Using a Reduced Set of Acoustic and Linguistic Features. Cogn Comput 5, 526–532 (2013). https://doi.org/10.1007/s12559-012-9174-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-012-9174-z