
Abstract
Background
To populate knowledge repositories, such as WordNet, Freebase and NELL, two branches of research have grown separately for decades. On the one hand, corpus-based methods which leverage unstructured free texts have been explored for years; on the other hand, some recently emerged embedding-based approaches use structured knowledge graphs to learn distributed representations of entities and relations. But there are still few comprehensive and elegant models that can integrate those large-scale heterogeneous resources to satisfy multiple subtasks of knowledge population including entity inference, relation prediction and triplet classification.
Methods
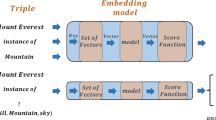
This paper contributes a novel embedding model which estimates the probability of each candidate belief <h,r,t,m> in a large-scale knowledge repository via simultaneously learning distributed representations for entities (h and t), relations (r) and the words in relation mentions (m). It facilitates knowledge population by means of simple vector operations to discover new beliefs. Given an imperfect belief, we can not only infer the missing entities and predict the unknown relations, but also identify the plausibility of the belief, just by leveraging the learned embeddings of remaining evidence.
Results
To demonstrate the scalability and the effectiveness of our model, experiments have been conducted on several large-scale repositories which contain millions of beliefs from WordNet, Freebase and NELL, and the results are compared with other cutting-edge approaches via comparing the performance assessed by the tasks of entity inference, relation prediction and triplet classification with their respective metrics. Extensive experimental results show that the proposed model outperforms the state of the arts with significant improvements.
Conclusions
The essence of the improvements comes from the capability of our model that encodes not only structured knowledge graph information, but also unstructured relation mentions, into continuous vector spaces, so that we can bridge the gap of one-hot representations, and expect to discover certain relevance among entities, relations and even words in relation mentions.



Similar content being viewed by others


Notes
We have changed the original name of the dataset (FB15K), so as to follow the naming conventions in our paper. Related studies using this dataset can be found at https://www.hds.utc.fr/everest/doku.php?id=en:transe.
References
Bollacker K, Cook R, Tufts P. Freebase: a shared database of structured general human knowledge. In: AAAI, 2007;7:1962–3. http://www.aaai.org/Papers/AAAI/2007/AAAI07-355.pdf.
Bollacker K, Evans C, Paritosh P, Sturge T, Taylor J. Freebase: a collaboratively created graph database for structuring human knowledge. In: Proceedings of the 2008 ACM SIGMOD international conference on management of data, ACM 2008; p. 1247–50 http://dl.acm.org/citation.cfm?id=1376746.
Bordes A, Glorot X, Weston J, Bengio Y. A semantic matching energy function for learning with multi-relational data. Mach Learn. 2014;94(2):233–5910. doi:10.1007/s10994-013-5363-6.
Bordes A, Usunier N, Garcia-Duran A, Weston J, Yakhnenko O. Translating embeddings for modeling multi-relational data. In: Advances in neural information processing systems, 2013. p. 2787–95.
Bordes A, Weston J, Collobert R, Bengio Y, et al. Learning structured embeddings of knowledge bases. In: AAAI 2011. http://www.aaai.org/ocs/index.php/AAAI/AAAI11/paper/viewPDFInterstitial/3659/3898.
Carlson A, Betteridge J, Kisiel B, Settles B, Jr, ERH, Mitchell TM. Toward an architecture for never-ending language learning. In: Proceedings of the twenty-fourth conference on artificial intelligence (AAAI 2010) 2010.
Fan M, Cao K, He Y, Grishman R. Jointly embedding relations and mentions for knowledge population. arXiv preprint arXiv:1504.01683 2015.
Fan M, Zhao D, Zhou Q, Liu Z, Zheng TF, Chang EY. Distant supervision for relation extraction with matrix completion. In: Proceedings of the 52nd annual meeting of the association for computational linguistics volume 1: long papers, p. 839–49. Association for Computational Linguistics, Baltimore, MD 2014. http://www.aclweb.org/anthology/P14-1079.
Fan M, Zhou Q, Chang E, Zheng TF. Transition-based knowledge graph embedding with relational mapping properties. In: Proceedings of the 28th Pacific Asia conference on language, information, and computation, 2014; p. 328–37.
Fan M, Zhou Q, Zheng TF. Learning embedding representations for knowledge inference on imperfect and incomplete repositories. arXiv preprint arXiv:1503.08155 2015.
Gardner M, Talukdar PP, Kisiel B, Mitchell TM. Improving learning and inference in a large knowledge-base using latent syntactic cues. In: EMNLP, p. 833–38. ACL 2013. http://dblp.uni-trier.de/db/conf/emnlp/emnlp2013.html#GardnerTKM13.
Grishman R. Information extraction: techniques and challenges. In: International summer school on information extraction: a multidisciplinary approach to an emerging information technology, SCIE ’97, p. 10–27. Springer, London 1997. http://dl.acm.org/citation.cfm?id=645856.669801.
GuoDong Z, Jian S, Jie Z, Min Z. Exploring various knowledge in relation extraction. In: Proceedings of the 43rd annual meeting on association for computational linguistics, ACL ’05, p. 427–34. Association for Computational Linguistics, Stroudsburg, PA, USA 2005. doi:10.3115/1219840.1219893.
Hendrickx I, Kim SN, Kozareva Z, Nakov P, Séaghdha DO, Padó S, Pennacchiotti M, Romano L, Szpakowicz S. Semeval-2010 task 8: multi-way classification of semantic relations between pairs of nominals. In: Proceedings of the 5th international workshop on semantic evaluation, SemEval ’10, p. 33–8. Association for Computational Linguistics, Stroudsburg, PA, USA 2010. http://dl.acm.org/citation.cfm?id=1859664.1859670.
Hoffmann R, Zhang C, Ling X, Zettlemoyer L, Weld DS. Knowledge-based weak supervision for information extraction of overlapping relations. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies-vol. 1, p. 541–50. Association for Computational Linguistics 2011.
Jenatton R, Le Roux N, Bordes A, Obozinski G, et al. A latent factor model for highly multi-relational data. In: NIPS, 2012. p. 3176–84.
Kambhatla N. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In: Proceedings of the ACL 2004 on interactive poster and demonstration sessions, p. 22. Association for Computational Linguistics 2004.
Klyne G, Carroll JJ. Resource description framework (rdf): concepts and abstract syntax. W3C Recommendation 2005.
Lao N, Cohen WW. Relational retrieval using a combination of path-constrained random walks. Mach. Learn. 2010;81(1):53–67.
Lao N, Mitchell T, Cohen WW. Random walk inference and learning in a large scale knowledge base. In: Proceedings of the 2011 conference on empirical methods in natural language processing, p. 529–39. Association for computational linguistics, Edinburgh, Scotland, UK. 2011. http://www.aclweb.org/anthology/D11-1049.
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. Distributed representations of words and phrases and their compositionality. In: Burges C., Bottou L, Welling M, Ghahramani Z, Weinberger K, editors. Advances in neural information processing systems 26, 2013. p. 3111–19.
Miller GA. Wordnet: a lexical database for english. Commun ACM. 1995;38(11):39–41.
Mintz M, Bills S, Snow R, Jurafsky D. Distant supervision for relation extraction without labeled data. In: Proceedings of the joint conference of the 47th annual meeting of the ACL and the 4th international joint conference on natural language processing of the AFNLP: vol. 2, p. 1003–11. Association for Computational Linguistics 2009.
Mitchell T, Cohen W, Hruschka E, Talukdar P, Betteridge J, Carlson A, Dalvi B, Gardner M, Kisiel B, Krishnamurthy J, Lao N, Mazaitis K, Mohamed T, Nakashole N, Platanios E, Ritter A, Samadi M, Settles B, Wang R, Wijaya D, Gupta A, Chen X, Saparov A, Greaves M, Welling J. Never-ending learning. In: Proceedings of the twenty-ninth AAAI conference on artificial intelligence (AAAI-15) 2015.
Quinlan JR, Cameron-Jones RM. Foil: A midterm report. In: Proceedings of the European conference on machine learning, ECML ’93, p. 3–20. Springer, London 1993. http://dl.acm.org/citation.cfm?id=645323.649599.
Riedel S, Yao L, McCallum A. Modeling relations and their mentions without labeled text. In: Machine learning and knowledge discovery in databases, p. 148–63. Springer 2010.
Sarawagi S. Information extraction. Found Trends Databases. 2008;1(3):261–377.
Socher R, Chen D, Manning CD, Ng A. Reasoning with neural tensor networks for knowledge base completion. In: Advances in neural information processing systems, 2013. p. 926–34.
Surdeanu M, Tibshirani J, Nallapati R, Manning CD. Multi-instance multi-label learning for relation extraction. In: Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning, p. 455–65. Association for Computational Linguistics 2012.
Sutskever I, Salakhutdinov R, Tenenbaum JB. Modelling relational data using bayesian clustered tensor factorization. In: NIPS, 2009. p. 1821–8.
Wang Z, Zhang J, Feng J, Chen Z. Knowledge graph and text jointly embedding. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), p. 1591–1601. Association for Computational Linguistics 2014. http://aclweb.org/anthology/D14-1167.
Wang Z, Zhang J, Feng J, Chen Z. Knowledge graph embedding by translating on hyperplanes. In: Proceedings of the twenty-eighth AAAI conference on artificial intelligence, July 27–31, 2014, Québec City, Québec, Canada., 2014. p. 1112–19 http://www.aaai.org/ocs/index.php/AAAI/AAAI14/paper/view/8531.
West R, Gabrilovich E, Murphy K, Sun S, Gupta R, Lin D. Knowledge base completion via search-based question answering. In: WWW 2014. http://www.cs.ubc.ca/~murphyk/Papers/www14.pdf.
Weston J, Bordes A, Yakhnenko O, Usunier N. Connecting language and knowledge bases with embedding models for relation extraction. In: Proceedings of the 2013 conference on empirical methods in natural language processing, p. 1366–71. Association for Computational Linguistics, Seattle, Washington, USA 2013. http://www.aclweb.org/anthology/D13-1136.
Xu K, Feng Y, Huang S, Zhao D. Semantic relation classification via convolutional neural networks with simple negative sampling. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, Sept 17–21, 2015, p. 536–40 (2015). http://aclweb.org/anthology/D/D15/D15-1062.pdf.
Xu Y, Mou L, Li G, Chen Y, Peng H, Jin Z. Classifying relations via long short term memory networks along shortest dependency paths. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, Sept 17–21, 2015, p. 1785–94 2015. http://aclweb.org/anthology/D/D15/D15-1206.pdf.
Zelenko D, Aone C, Richardella A. Kernel methods for relation extraction. J Mach Learn Res. 2003;3:1083–106.
Acknowledgments
The paper is dedicated to all the members of CSLT (http://cslt.riit.tsinghua.edu.cn/) and Proteus Group (http://nlp.cs.nyu.edu/index.shtml). It was supported by National Program on Key Basic Research Project (973 Program) Under Grant 2013CB329304, National Science Foundation of China (NSFC) Under Grant Nos. 61433018 and 61373075, and Chinese Scholarship Council, when the first author was a joint-supervision Ph.D. candidate of Tsinghua University and New York University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
Miao Fan, Qiang Zhou, Andrew Abel, Thomas Fang Zheng and Ralph Grishman declare that they have no conflict of interest.
Informed Consent
Informed consent was not required as no humans or animals were involved.
Human and Animal Rights
This article does not contain any studies with human participants or animals performed by any of the authors.
Rights and permissions
About this article

Cite this article
Fan, M., Zhou, Q., Abel, A. et al. Probabilistic Belief Embedding for Large-Scale Knowledge Population. Cogn Comput 8, 1087–1102 (2016). https://doi.org/10.1007/s12559-016-9425-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-016-9425-5