
Abstract
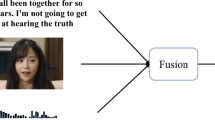
Multimodal sentiment analysis is a popular and challenging research topic in natural language processing, but the impact of individual modal data in videos on sentiment analysis results can be different. In the temporal dimension, natural language sentiment is influenced by nonnatural language sentiment, which may enhance or weaken the original sentiment of the current natural language. In addition, there is a general problem of poor quality of nonnatural language features, which essentially hinders the effect of multimodal fusion. To address the above issues, we proposed a multimodal encoding–decoding translation network with a transformer and adopted a joint encoding–decoding method with text as the primary information and sound and image as the secondary information. To reduce the negative impact of nonnatural language data on natural language data, we propose a modality reinforcement cross-attention module to convert nonnatural language features into natural language features to improve their quality and better integrate multimodal features. Moreover, the dynamic filtering mechanism filters out the error information generated in the cross-modal interaction to further improve the final output. We evaluated the proposed method on two multimodal sentiment analysis benchmark datasets (MOSI and MOSEI), and the accuracy of the method was 89.3% and 85.9%, respectively. In addition, our method outperformed the current state-of-the-art methods. Our model can greatly improve the effect of multimodal fusion and more accurately analyze human sentiment.






Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data Availability
Data is available in a public repository. The data that support the findings of this study are available in the following: MOSI–https://www.jianguoyun.com/p/DV1YEgUQvP35Bhim9d8D and MOSEI–https://www.jianguoyun.com/p/DVw4E7EQvP35Bhir9d8D.
References
Bo P, Lillian L. A sentimental education: sentiment analysis using subjectivity summarization based on minimum cuts. Proceedings of the Association for Computational Linguistics; 2004. p. 271–8. https://doi.org/10.3115/1218955.1218990.
Vinodhini G, Chandrasekaran RM. Sentiment analysis and opinion mining: a survey. Int J. 2012;2(6):282–92. https://doi.org/10.1007/978-1-4899-7502-7.
Manning C, Surdeanu M, Bauer J. The Stanford CoreNLP natural language processing toolkit. Proceedings of the Association for Computational Linguistics; 2014. p. 55–60. https://doi.org/10.3115/v1/P14-5010.
Poria S, Cambria E, Hazarika D. Context-dependent sentiment analysis in user-generated videos, vol. 1. Proceedings of the Association for Computational Linguistics; 2017. p. 873–83. https://doi.org/10.18653/v1/P17-1081.
Baltrušaitis T, Ahuja C, Morency L-P. Multimodal machine learning: a survey and taxonomy. IEEE Trans Pattern Anal Mach Intell. 2019;41(2):423–43. https://doi.org/10.1109/TPAMI.2018.2798607.
Majumder N, Hazarika D, Gelbukh A, Cambria E, Poria S. Multimodal sentiment analysis using hierarchical fusion with context modeling. Knowl Based Syst. 2018;161:124–33. https://doi.org/10.1016/j.knosys.2018.07.041.
Hu A, Flaxman S. Multimodal sentiment analysis to explore the structure of emotions, vol. 9. New York, NY, USA: Proceedings of the Association for Computing Machinery; 2018. p. 350–8. https://doi.org/10.1145/3219819.3219853.
Baecchi C, Uricchio T, Bertini M, et al. A multimodal feature learning approach for sentiment analysis of social network multimedia. Multimed Tools Appl. 2016;75:2507–25. https://doi.org/10.1007/s11042-015-2646-x.
Pandeya YR, Lee J. Deep learning-based late fusion of multimodal information for emotion classification of music video. Multimed Tools Appl. 2021;80:2887–905. https://doi.org/10.1007/s11042-020-08836-3.
Poria S, Cambria E, Bajpai R, Hussain A. A review of affective computing: from unimodal analysis to multimodal fusion. Inform Fusion. 2017;37:98–125.
Shenoy A, Sardana A. Multilogue-Net: A context-aware RNN for multi-modal emotion detection and sentiment analysis in conversation. Proceedings of the Second Grand Challenge and Workshop on Multimodal Language; 2020. p. 19–28.
Zadeh A, Chen M, Poria S. Tensor fusion network for multimodal sentiment analysis. Proceedings of the Association for Computational Linguistics; 2017. p. 1103–14. https://doi.org/10.18653/v1/d17-1115.
Zadeh A, Liang P, Mazumder N, Poria S. Memory fusion network for multi-view sequential learning. Proc AAAI Conf Artif Intell. 2018;32(1):5634–41.
Liang P, Liu Z, Zadeh A, Morency L. Multimodal language analysis with recurrent multistage fusion. Proceedings of the Association for Computational Linguistics; 2018. p. 150–61. https://doi.org/10.18653/v1/D18-1014.
Ghosal D, Akhtar MS, Chauhan D, Poria S. Contextual intermodal attention for multi-modal sentiment analysis. Proceedings of the Association for Computational Linguistics; 2018. p. 3454–66. https://doi.org/10.18653/v1/D18-1382.
Devlin J, Chang M, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. In: Burstein J, Doran C, Solorio T, editors. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, vol 1, June 2–7, 2019 (Long and Short Papers). Association for Computational Linguistics; 2019. p. 4171–86.
Liu Z, Shen Y, Lakshminarasimhan VB, Liang PP, Zadeh A, Morency L. Efficient low-rank multimodal fusion with modality-specific factors. In: Gurevych I, Miyao Y, editors. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July 15–20, 2018, Volume 1: Long Papers. Association for Computational Linguistics; 2018. p. 2247–56.
Zadeh A, Liang PP, Mazumder N, Poria S, Cambria E, Morency L-P. Memory fusion network for multi-view sequential learning. Proc AAAI Conf Artif Intell. 2018;32(1):5634–41.
Ghosal D, Akhtar MS, Chauhan D, Poria S. Contextual intermodal attention for multi-modal sentiment analysis. Proceedings of the Association for Computational Linguistics; 2018. p. 3454–66. https://doi.org/10.18653/v1/D18-1382.
Han W, Chen H, Gelbukh A, Zadeh A, et al. Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis. ICMI ’21: Proceedings of the 2021 International Conference on Multimodal Interaction; 2021. p. 6–15. https://doi.org/10.1145/3462244.3479919.
Yu W, Xu H, Yuan Z, Wu J. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. Proc AAAI Conf Artif Intell. 2021;35(12):10790–7. https://doi.org/10.18653/v1/D18-1382.
Han W, Chen H, Poria S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; 2021. p. 9180–92.
Li Q, Gkoumas D, Lioma C, Melucci M. Quantum-inspired multimodal fusion for video sentiment analysis. Inf Fusion. 2021;65:58–71.
He J, Hu H. MF-BERT: Multimodal fusion in pre-trained BERT for sentiment analysis. IEEE Signal Process Lett. 2022;29:454–8.
Wu Y, Lin Z, Zhao Y, Qin B, Zhu L-N. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis. In: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics; 2021. p. 4730–8.
Jiang D, Wei R, Liu H, Wen J, Tu G, Zheng L, Cambria E. A multitask learning framework for multimodal sentiment analysis. In: 2021 International Conference on Data Mining Workshops (ICDMW). IEEE; 2021. p. 151–7.
Yang B, Wu L, Zhu J, Shao B, Lin X, Liu TY. Multimodal sentiment analysis with two-phase multi-task learning. IEEE/ACM Trans Audio Speech Language Process. 2022;30:2015–24.
Akhtar S, Ghosal D, Ekbal A, Bhattacharyya P, Kurohashi S. All-in-one: Emotion, sentiment and intensity prediction using a multi-task ensemble framework. IEEE Trans Affect Comput. 2019;13(1):285–97. https://doi.org/10.1109/TAFFC.2019.2926724.
Wang Y, Chen Z, Chen S, Zhu Y. Multi-task Learning for Multimodal Emotion Recognition. In: Pimenidis E, Angelov P, Jayne C, Papaleonidas A, Aydin ML, editors. Artificial Neural Networks and Machine Learning – ICANN 2022. ICANN 2022. Lecture Notes in Computer Science, vol. 13531. Cham: Springer; 2022.
Song Y, Fan X, Yang Y, Ren G, Pan W. A Cross-Modal Attention and Multi-task Learning Based Approach for Multi-modal Sentiment Analysis. In: Liang Q, Wang W, Mu J, Liu X, Na Z, editors. Artificial Intelligence in China. Lecture Notes in Electrical Engineering, vol. 854. Singapore: Springer; 2022. p. 159–66. https://doi.org/10.1016/j.knosys.2022.109924.
Yang L, Na J-C, Yu J. Cross-Modal Multitask Transformer for End-to-End Multimodal Aspect-Based Sentiment Analysis. Inf Process Manag. 2022;59(5):103038 ISSN 0306–4573.
Chauhan DS, Singh GV, Arora A, Ekbal A, Bhattacharyya P. An emoji-aware multitask framework for multimodal sarcasm detection. Knowl Based Syst. 2022;257:109924. https://doi.org/10.1016/j.knosys.2022.109924 ISSN 0950–7051.
Li H, Xu H. Deep reinforcement learning for robust emotional classification in facial expression recognition. Knowl Based Syst. 2020;204: 106172. https://doi.org/10.1016/j.knosys.2020.106172.
Shu Y, Xu G. Emotion recognition from music enhanced by domain knowledge. In: The Pacific Rim International Conference On Artificial Intelligence 2019. Trends In Artificial Intelligence; 2019. p. 121–34.
Zhang K, Li Y, Wang J, Cambria E, Li X. Real-time video emotion recognition based on reinforcement learning and domain knowledge. IEEE Trans Circuits Syst Video Technol. 2021;32(3):1034–47.
Pham H, Liang PP, Manzini T, Morency L-P, Póczos B. Found in translation: learning robust joint representations by cyclic translations between modalities. Proc AAAI Conf Artif Intell. 2019;33:6892–9.
Cambria E, Howard N, Hsu J, Hussain A. Sentic blending: Scalable multimodal fusion for the continuous interpretation of semantics and sentics. In: 2013 IEEE Symposium on Computational Intelligence for Human-Like Intelligence (CIHLI). Singapore, Singapore: IEEE; 2013. p. 108–17. https://doi.org/10.1109/CIHLI.2013.6613272.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Attention is all you need. Adv Neural Inf Process Syst. 2017;30:5998–6008.
Wu Y, Schuster M, Chen Z, Le QV, Norouzi M, Macherey W, Krikun M, Cao Y, Gao Q, Macherey K, Klingner J, Shah A, Johnson M, Liu X, Kaiser L, Gouws S, Kato Y, Kudo T, Kazawa H, Stevens K, Kurian G, Patil N, Wang W, Young C, Smith J, Riesa J, Rudnick A, Vinyals O, Corrado G, Hughes M, Dean J. Google’s neural machine translation system: Bridging the gap between human and machine translation. http://arxiv.org/abs/1609.08144. Accessed 18 Oct 2016.
Cho K, van Merrienboer B, Gülçehre Ç, Bahdanau D, Bougares F, Schwenk H, Bengio Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Moschitti A, Pang B, Daelemans W, editors. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25–29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL. ACL; 2014. p. 1724–34. https://doi.org/10.3115/v1/d14-1179.
Zadeh A, Zellers R, Pincus E, Morency L. MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. IEEE Intell Syst. 2016;31(6):82–8. http://arxiv.org/abs/1606.06259. Accessed 12 Aug 2016.
Zadeh AB, Liang PP, Poria S, Cambria E, Morency L-P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); 2018. p. 2236–46.
Degottex G, Kane J, Drugman T, Raitio T, Scherer S. COVAREP–a collaborative voice analysis- repository for speech technologies. In: 2014 IEEE international conference on acoustics, speech and signal processing (icassp). IEEE; 2014. p. 960–4.
Wang Y, Shen Y, Liu Z, Liang PP, Zadeh A, Morency L-P. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. Proc AAAI Conf Artif Intell. 2019;33:7216–23.
Tsai YHH, Bai S, Liang PP, Kolter JZ, Morency LP, Salakhutdinov R. Multimodal transformer for unaligned multimodal language sequences. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy. Association for Computational Linguistics; 2019. p. 6558–69.
Tsai YH, P Liang P, Zadeh A, Morency L, Salakhutdinov R. Learning factorized multimodal representations. In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6–9, 2019. OpenReview.net; 2019. https://openreview.net/forum?id=rygqqsA9KX. Accessed 14 May 2019.
Sun Z, Sarma P, Sethares W, Liang Y. Learning Relationships between Text, Audio, and Video via Deep Canonical Correlation for Multimodal Language Analysis. Proc AAAI Conf Artif Intell. 2020;34(5):8992–9. https://doi.org/10.1609/aaai.v34i05.6431.
Rahman W, Hasan MK, Lee S, Zadeh A, Mao C, Morency L-P, Hoque E. Integrating multimodal information in large pretrained transformers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; 2020. p. 2359–69.
Funding
This work was supported by the National Natural Science Foundation of China 61962057, Autonomous Region Key R&D Project 2021B01002, and the National Natural Science Foundation of China under grant U2003208.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, F., Tian, S., Yu, L. et al. TEDT: Transformer-Based Encoding–Decoding Translation Network for Multimodal Sentiment Analysis. Cogn Comput 15, 289–303 (2023). https://doi.org/10.1007/s12559-022-10073-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-022-10073-9