
Abstract
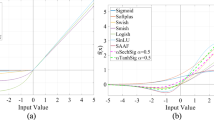
Deep neural networks provide more expressive power in comparison to shallow ones. However, current activation functions can not propagate error using gradient descent efficiently with the increment of the number of hidden layers. Current activation functions, e.g. sigmoid, have large saturation regions which are insensitive to changes of hidden neuron’s input and yield gradient diffusion. To relief these problems, we propose a bi-firing activation function in this work. The bi-firing function is a differentiable function with a very small saturation region. Experimental results show that deep neural networks with the proposed activation functions yield faster training, better error propagation and better testing accuracies on seven image datasets.








Similar content being viewed by others


References
Huang G-B, Wang DH, Lan Y (2011) Extreme learning machines: a survey. Int J Mach Learn Cybern 2(2):107–122
Chacko BP, Vimal Krishnan VR, Raju G, Babu Anto P (2012) Handwritten character recognition using wavelet energy and extreme learning machine. Int J Mach Learn Cybern 3(2):149–161
Ng WWY, Yeung DS, Wang D, Tsang ECC, Wang X-Z (2007) Localized generalization error of Gaussian-based classifiers and visualization of decision boundaries. Soft Comput. 11(4):375–381
Ng WWY, Yeung DS (2003) Selection of weight quantisation accuracy for radial basis function neural network using stochastic sensitivity measure. Electron Lett 39(10):787–789
Yeung DS, Chan PPK, Ng WWY (2009) Radial basis function network learning using localized generalization error bound. Inf Sci 179(19):3199–3217
Hinton GE, Osindero S, The Y (2006) A fast learning algorithm for deep belief nets. Neural Comput 18:1527–1554
Bengio Y, Lamblin P, Popovici D, Larochelle H (2007) Greedy layer-wise training of deep networks. In: Neural information processing systems. MIT Press, Massachusetts, pp 153–160
Vincent P, Larochelle H, Lajoie I, Bengio Y, Manzagol P-A (2010) Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion. J Mach Learn Res 11:3371–3408
Rifai S, Vincent P, Muller X, Glorot X, Bengio Y (2011) Contractive auto-encoders: explicit invariance during feature extraction. In: Proceedings of the 28th international conference on machine learning, pp 833–840
Glorot X, Bordes A, Bengio Y (2011) Deep sparse rectifier neural networks. In: Proceeding of the 14th international conference on artificial intelligence and statistics, vol 15, pp 315–323
Nair V, Hintion GE (2010) Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th international conference on machine learning, pp 807–814
Bengio Y (2009) Learning deep architectures for AI. Found Trends Mach Learn 2(1):1–127
Serre T, Kreiman G, Kouh M, Cadieu C, Koblich U, Poggio T (2007) A quantitative theory of immediate visual recognition. Progr Brain Res Comput Neurosci Theor Insights Brain Funct 165:33–56
Bengio Y, LeCun Y (2007) Scaling learning algorithms towards AI. In: Bottou L, Chapelle O, DeCoste D, Weston J (eds) Large scale kernel machines. MIT Press, Massachusetts, pp 321–388
Hastad J, Goldmann M (1991) On the power of small-depth threshold circuits. Comput Complex 1(2):113–129
Glorot X, Bengio Y (2010) Understanding the difficulty of training deep feedforward neural networks. In: JMLR W&CP: proceedings of the thirteenth international conference on artificial intelligence and statistics, vol 9, pp 249–256
Erhan D, Bengio Y, Courville A, Manzagol PA, Vincent P, Bengio S (2009) Why does unsupervised pre-training help deep learning. J Mach Learn Res 11:625–660
Ranzato M, Poultney C, Chopra S, LeCun Y (2007) A sparse and locally shift invariant feature extractor applied to document images. In: International conference on document analysis and recognition (ICDA’07), Washington: IEEE Computer Society, pp 1213–1217
Aurelio Ranzoto M, Szummer M (2008) Semi-supervised learning of compact document representations with deep networks. In: Proceedings of the 25th internal conference on machine learning, pp 792–799
LeCun Y, Bottou L, Orr GB, Muller K (1998) Efficient backprop. In: Muller K-R, Montayon G, Orr GB (eds) Neural networks: tricks of the trade. Springer, Berlin, pp 9–50
Jarrett K, Kavukcuoglu K, Ranzato M, LeCun Y (2009) What is the best multi-stage architecture for object recognition? In: IEEE 12th international conference on computer vision, pp 2146–2153
Tong Dong Ling, Mintram Robert (2010) Genetic algorithm-neural network (GANN): a study of neural network activation functions and depth of genetic algorithm search applied to feature selection. Int J Mach Learn Cybern 1(1–4):75–87
Nesterov Y (2005) Smooth minimization of non-smooth functions. Math Program 103(1):127–152
Bottou L (2012) Stochastic gradient tricks. In: Muller K-R, Montayon G, Orr GB (eds) Neural networks: tricks of the trade. Springer, Berlin, pp 430–445
Krizhevsky A (2009) Learning multiple layers of features from tiny images. M.Sc. Thesis, Department of Computer Science, University of Toronto
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Larochelle H, Erhan D, Courville A, Bergstra J, Bengio Y (2007) An empirical evaluation of deep architectures on problems with many factors of variation. In: Proceedings of the 24th international conference on machine learning, pp 473–480
Duda RO, Hart PE, Stork DG (2012) Pattern classification. Wiley, New York
Acknowledgments
This work is supported by National Natural Science Foundation of China (61272201, 61003171 and 61003172) and a Program for New Century Excellent Talents in University (NCET-11-0162) of China.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Li, JC., Ng, W.W.Y., Yeung, D.S. et al. Bi-firing deep neural networks. Int. J. Mach. Learn. & Cyber. 5, 73–83 (2014). https://doi.org/10.1007/s13042-013-0198-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-013-0198-9