
Abstract
One of the important tools for analyzing gene expression data is biclustering method. It focuses on finding a subset of genes and a subset of experimental conditions that together exhibit coherent behavior. However, most of the existing biclustering algorithms find exclusive biclusters, which is inappropriate in the context of biology. Since biological processes are not independent of each other, many genes may participate in multiple different processes. Hence, nonexclusive biclustering algorithms are required for finding overlapping biclusters. In this regard, a novel possibilistic biclustering algorithm is presented here to find highly overlapping biclusters of larger volume with mean squared residue lower than a predefined threshold. It judiciously incorporates the concept of possibilistic clustering algorithm into biclustering framework. The integration enables efficient selection of highly overlapping coherent biclusters with mean squared residue lower than a given threshold. The detailed formulation of the proposed possibilistic biclustering algorithm, along with a mathematical analysis on the convergence property, is presented. Some quantitative indices are introduced for evaluating the quality of generated biclusters. The effectiveness of the algorithm, along with a comparison with other algorithms, is demonstrated both qualitatively and quantitatively on yeast gene expression data set. In general, the proposed algorithm shows excellent performance at finding patterns in gene expression data.




Similar content being viewed by others

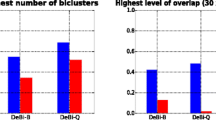
References
Ben-Dor A, Chor B, Karp R, Yakhini Z (2002) Discovering local structue in gene expression data: the order-preserving submatrix problem. In: Proceedings of the 6th international conference on computational biology, pp 49–57
Bezdek J (1980) A convergence theorem for the fuzzy ISODATA clustering algorithm. IEEE Trans Pattern Anal Mach Intell 2:1–8
Bezdek J, Hathaway RJ, Sabin MJ, Tucker WT (1987) Convergence theory for fuzzy C-means: counter examples and repairs. IEEE Trans Syst Man Cybern 17:873–877
Bezdek JC (1981) Pattern recognition with fuzzy objective function algorithm. Plenum, New York
Bryan K, Cunningham P, Bolshakova N (2005) Application of simulated annealing to the biclustering of gene expression data. In: Proceedings of the 18th IEEE symposium on computer-based medical systems, pp 383–388
Califano A, Stolovitzky G, Tu Y (2000) Analysis of gene expression microarrays for phenotype classifiation. In: Proceedings of the international conference on computational molecular biology, pp 75–85
Cano C, Adarve L, Lopez J, Blanco A (2007) Possibilistic approach for biclustering microarray data. Comput Biol Med 37:1426G–1436G
Chakraborty A, Maka H (2005) Biclustering of gene expression data using genetic algorithm. In: IEEE symposium on computational intelligence in bioinformatics and computational biology, pp 1–8
Chen G, Sullivan PF, Kosoroka MR (2013) Biclustering with heterogeneous variance. In: Proceedings of National Academy of Sciences, USA, vol 110, no. 30, pp 12,253G–12,258G
Cheng Y, Church GM (2000) Biclustering of expression data. In: Proceedings of the 8th international conference on intelligent systems for molecular biology, pp 93–103
Cho H, Dhillon I, Guan Y, Sra S (2004) Minimum sum-squared residue coclustering of gene expression data. In: Proceedings of the 4th SIAM international conference on data mining
Divina F, Aguilar-Ruiz JS (2006) Biclustering of expression data with evolutionary computation. IEEE Trans Knowl Data Eng 18(5):590–602
Domany E (2003) Cluster analysis of gene expression data. J Stat Phys 110:1117–1139
Eisen MB, Spellman PT, Botstein D (1998) Cluster analysis and display of genome-wide expression patterns. In: Proceedings of the National Academy of Sciences, USA, vol 95, pp 14,863–14,868
Eren K, Deveci M, Kucuktunc O, Catalyurek UV (2012) A comparative analysis of biclustering algorithms for gene expression data. Briefings Bioinform. doi:10.1093/bib/bbs032
Fei X, Lu S, Pop HF, Liang LR (2007) GFBA: a biclustering algorithm for discovering value-coherent biclusters. Bioinf Res Appl, 1–12
Getz G, Levine E, Domany E (2000) Coupled two-way clustering analysis of gene expression data. In: Proceedings of the National Academy of Sciences, USA, pp 12,079–12,084
Golub TR, Slonim DK, Tamayo P, Huard C, Gaasenbeek M, Mesirov JP, Coller H, Loh ML, Downing JR, Caligiuri MA, Bloomfield CD, Lander ES (1999) Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science 286:531–537
Hartigan J, Wong M (1979) Algorithm AS136: a k-means clustering algorithms. Appl Stat 28:G100–G108
Hartigan JA (1972) Direct clustering of a data matrix. J Am Stat Assoc 67(337):123–129
Herrero J, Valencia A, Dopazo J (2001) A hierarchical unsupervised growing neural network for clustering gene expression patterns. Bioinformatics 17:126G–136G
James G (1996) Modern engineering mathematics. Addison-Wesley, Reading
Jiang D, Tang C, Zhang A (2004) Cluster analysis for gene expression data: a survey. IEEE Trans Knowl Data Eng 16(11):1370–1386
Kaufmann L, Rousseeuw PJ (1990) Finding groups in data: an introduction to cluster analysis. Wiley, New York
Krishnapuram R, Keller JM (1993) A possibilistic approach to clustering. IEEE Trans Fuzzy Syst 1(2):G98–G110
Lazzeroni L, Owen A (2000) Plaid models for gene expression data. Technical report, Standford University
Lee M, Shen H, Huang JZ, Marron JS (2010) Biclustering via sparse singular value decomposition. Biometrics 66(4):1087–1095
Liu J, Wang W (2003) OP-cluster: clustering by tendency in high dimensional space. In: Proceedings of the 3rd IEEE international conference on data mining, pp 187–194
Madeira S, Oliveira A (2004) Biclustering algorithms for biological data analysis: a survey. IEEE/ACM Trans Comput Biol Bioinform 1(1):24–45
Maji P, Pal SK (2007) Rough set based generalized fuzzy C-means algorithm and quantitative indices. IEEE Trans Syst Man Cybern Part B Cybern 37(6):1529–1540
Murali TM, Kasif S (2003) Extracting conserved gene expression motifs from gene expression data. Proc Pac Symp Biocomput 8:77–88
Paul S, Maji P (2013) Gene ontology based quantitative index to select functionally diverse genes. Int J Mach Learn Cybern 1–18. doi:10.1007/s13042-012-0133-5
Pawlak Z (1991) Rough sets, theoretical aspects of resoning about data. Kluwer, Dordrecht
Rana S, Jasola S, Kumar R (2013) A boundary restricted adaptive particle swarm optimization for data clustering. Int J Mach Learn Cybern 4(4):391–400
Rodriguez-Baena DS, Perez-Pulido AJ, AguilarG-Ruiz JS (2011) A biclustering algorithm for extracting bit-patterns from binary datasets. Bioinformatics 27(19):2738–2745
Sarma TH, Viswanath P, Reddy BE (2013) A hybrid approach to speed-up the K-means clustering method. Int J Mach Learn Cybern 4(2):107–117
Segal E, Taskar B, Gasch A, Friedman N, Koller D (2001) Rich probabilistic models for gene expression. Bioinformatics, pp S243–S252
Sheng Q, Moreau Y, Moor BD (2003) Biclustering microarray data by Gibbs sampling. Bioinformatics 19:ii196–ii205
Sill M, Kaiser S, Benner A, Kopp-Schneider A (2011) Robust biclustering by sparse singular value decomposition incorporating stability selection. Bioinformatics 27(15):2089–2097
Sutheeworapong S, Ota M, Ohta H, Kinoshita K (2012) A novel biclustering approach with iterative optimization to analyze gene expression data. Adv Appl Bioinf Chem 2012(5):23–59
Tamayo P, Slonim D, Mesirov J, Zhu Q, Kitareewan S, Dmitrovsky E, Lander ES, Golub TR (1999) Interpreting patterns of gene expression with self-organizing maps: methods and application to hematopoietic differentiation. Proc Natl Acad Sci USA 96(6):2907G–2912G
Tanay A, Sharan R, Shamir R (2002) Discovering statistically significant biclusters in gene expression data. Bioinformatics 19:196–205
Tang C, Zhang L, Zhang A, Ranmanathan M (2001) Interrelated two-way clustering: an unsupervised approach for gene expression data analysis. In: Proceedings of the 2nd IEEE international symposium on bioinformatics and bioengineering, pp 41–48
Tibshirani R, Hastie T, Eisen M, Ross D, Bostein D, Brown P (1999) Clustering methods for the analysis of DNA microarray data. Technical report, Standford University
Tjhi WC, Chen L (2006) A partitioning based algorithm to fuzzy co-cluster documents and words. Patt Recognit Lett 27:151G–159G
Tjhi WC, Chen L (2007) Possibilistic fuzzy co-clustering of large document collections. Patt Recognit 40:G3452–G3466
Tjhi WC, Chen L (2008) A heuristic based fuzzy co-clustering algorithm for categorization of high dimensional data. Fuzzy Sets Syst 159:G371–G389
Tjhi WC, Chen L (2008) Dual fuzzy-possibilistic co-clustering for categorization of documents. IEEE Trans Fuzzy Syst
Wang R, Miao D, Li G, Zhang H (2007) Rough overlapping biclustering of gene expression data. In: Proceedings of the 7th IEEE international conference on bioinformatics and bioengineering, pp 828–834
Wang X, Wang Y, Wang L (2004) Improving fuzzy C-means clustering based on feature-weight learning. Pattern Recognit Lett 25(10):1123–1132
Wu CJ, Fu Y, Murali TM, Kasif S (2004) Gene expression module discovery using Gibbs sampling. Genome Inf 15(1):239–248
Yan H (2004) Convergence condition and efficient implementation of the fuzzy curve-tracing (FCT) algorithm. IEEE Trans Syst Man Cybern Part B Cybern 34(1):210–221
Yang J, Wang W, Wang H, Yu PS (2003) Enhanced biclustering on expression data. In: Proceedings of the 3rd IEEE conference on bioinformatics and bioengineering, pp 321–327
Yeung D, Wang X (2002) Improving performance of similarity-based clustering by feature weight learning. IEEE Trans Pattern Anal Mach Intell 24(4):556–561
Zadeh LA (1965) Fuzzy sets. Inf Control 8:338–353
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Das, C., Maji, P. Possibilistic biclustering algorithm for discovering value-coherent overlapping δ-biclusters. Int. J. Mach. Learn. & Cyber. 6, 95–107 (2015). https://doi.org/10.1007/s13042-013-0211-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-013-0211-3