
Abstract
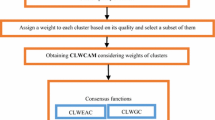
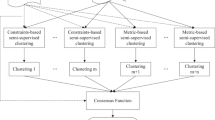
Semi-supervised clustering ensemble introduces partial supervised information, usually pairwise constraints, to achieve better performance than clustering ensemble. Although it has been successful in many aspects, there are still several limitations that need to be further improved. Firstly, supervised information is only utilized in ensemble generation, but not in the consensus process. Secondly, all clustering solutions participate in getting a final partition without considering redundancy among clustering solutions. Thirdly, each cluster in the same clustering solution is treated equally, which neglects the influence of different clusters to the final clustering result. To address these issues, we propose a two-stage semi-supervised clustering ensemble framework which considers both ensemble member selection and the weighting of clusters. Especially, we define the weight of each pairwise constraint to assist ensemble members selection and the weighting of clusters. In the first stage, a subset of clustering solutions is obtained based on the quality and diversity of clustering solutions in consideration of supervised information. In the second stage, the quality of each cluster is determined by the consistency of unsupervised and supervised information. For the unsupervised information consistency of a cluster, we consider evaluating it by the consistency of a cluster relative to all clustering solutions. For the supervised information consistency of a cluster, it depends on how satisfied a cluster is with the supervised information. In the end, the final partition is achieved by a weighted co-association matrix as consensus function. Experimental results on various datasets show that the proposed framework outperforms most of state-of-the-art clustering algorithms.





Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Availability of data and materials
The data sets supporting the results of this article are included within the references.
References
Jain AK (2010) Data clustering: 50 years beyond K-means. Pattern Recogn Lett 31(8):651–666
Ding Y, Zhao Y, Shen X, Musuvathi M, Mytkowicz T (2015) Yinyang k-means: a drop-in replacement of the classic k-means with consistent speedup. In International conference on machine learning, pp 579-587
Zhang Z, Liu L, Shen F, Shen H, Shao L (2018) Binary multi-view clustering. IEEE Trans Pattern Anal Mach Intell 41(7):1774–1782
Liu X, Li M, Tang C, Xia J, Xiong J, Liu L, Zhu E (2020) Efficient and effective regularized incomplete multi-view clustering. IEEE Trans Pattern Anal Mach Intell 43(8):2634–2646
Xia S, Peng D, Meng D, Zhang C, Wang G, Giem E, Chen Z (2020) A fast adaptive k-means with no bounds. IEEE Trans Pattern Anal Mach Intell
Zhou J, Zheng H, Pan L (2019) Ensemble clustering based on dense representation. Neurocomputing 357:66–76
Li F, Qian Y, Wang J, Dang C, Jing L (2019) Clustering ensemble based on sample’s stability. Artif Intell 273:37–55
Yu L, Cao F, Zhao X, Yang X, Liang J (2020) Combining attribute content and label information for categorical data ensemble clustering. Appl Math Comput 381:125280
Jain BJ (2016) Condorcet’s jury theorem for consensus clustering and its implications for diversity. arXiv preprint arXiv:1604.07711
Yu Z, Chen H, You J, Wong HS, Liu J, Han G (2014) Double selection based semi-supervised clustering ensemble for tumor clustering from gene expression profiles. IEEE/ACM Trans Comput Biol Bioinf 11(4):727–740
Yang F, Li T, Zhou Q, Xiao H (2017) Cluster ensemble selection with constraints. Neurocomputing 235:59–70
Xiao W, Yang Y, Wang H, Li T, Xing H (2016) Semi-supervised hierarchical clustering ensemble and its application. Neurocomputing 173:1362–1376
Topchy A, Jain AK, Punch W (2003) Combining multiple weak clusterings. In: Third IEEE international conference on data mining, pp 331–338
Fred AL, Jain AK (2002) Data clustering using evidence accumulation. In: Object recognition supported by user interaction for service robots 4, pp 276–280
Yu Z, Luo P, You J, Wong HS, Leung H, Wu S, Han G (2015) Incremental semi-supervised clustering ensemble for high dimensional data clustering. IEEE Trans Knowl Data Eng 28(3):701–714
Fern XZ, Brodley CE (2003) Random projection for high dimensional data clustering: a cluster ensemble approach. In: Proceedings of the 20th international conference on machine learning, pp 186–193
Fred AL, Jain AK (2005) Combining multiple clusterings using evidence accumulation. IEEE Trans Pattern Anal Mach Intell 27(6):835–850
Iam-On N, Boongoen T, Garrett S, Price C (2011) A link-based approach to the cluster ensemble problem. IEEE Trans Pattern Anal Mach Intell 33(12):2396–2409
Liu H, Wu J, Liu T, Tao D, Fu Y (2017) Spectral ensemble clustering via weighted k-means: theoretical and practical evidence. IEEE Trans Knowl Data Eng 29(5):1129–1143
Huang D, Wang C-D, Lai J-H (2017) Locally weighted ensemble clustering. IEEE Trans Cybernet 48(5):1460–1473
Bai L, Liang J, Du H, Guo Y (2018) An information-theoretical framework for cluster ensemble. IEEE Trans Knowl Data Eng 31(8):1464–1477
Strehl A, Ghosh J (2002) Cluster ensembles—a knowledge reuse framework for combining multiple partitions. J Mach Learn Res 3(12):583–617
Fern XZ, Brodley CE (2004) Solving cluster ensemble problems by bipartite graph partitioning. In: Proceedings of the twenty-first international conference on machine learning, p 36
Huang D, Lai JH, Wang CD (2015) Robust ensemble clustering using probability trajectories. IEEE Trans Knowl Data Eng 28(5):1312–1326
Křvánek M, Morávek J (1986) Np-hard problems in hierarchical-tree clustering. Acta Inform 23(3):311–323
Li T, Ding C, Jordan MI (2007) Solving consensus and semi-supervised clustering problems using nonnegative matrix factorization. In: Seventh IEEE international conference on data mining, pp 577–582
Vega-Pons S, Correa-Morris J, Ruiz-Shulcloper J (2010) Weighted partition consensus via kernels. Pattern Recogn 43(8):2712–2724
Franek L, Jiang X (2014) Ensemble clustering by means of clustering embedding in vector spaces. Pattern Recogn 47(2):833–842
Yu Z, Li L, Gao Y, You J, Liu J, Wong HS, Han G (2014) Hybrid clustering solution selection strategy. Pattern Recogn 47(10):3362–3375
Jia J, Xiao X, Liu B, Jiao L (2011) Bagging-based spectral clustering ensemble selection. Pattern Recogn Lett 32(10):1456–1467
Ma T, Yu T, Wu X, Cao J, Al-Abdulkarim A, Al-Dhelaan A, Al-Dhelaan M (2020) Multiple clustering and selecting algorithms with combining strategy for selective clustering ensemble. Soft Comput 24(20):15129–15141
Wagstaff K, Cardie C, Rogers S, Schrodl S (2001) Constrained k-means clustering with background knowledge. Icml 1:577–584
Zeng H, Cheung YM (2011) Semi-supervised maximum margin clustering with pairwise constraints. IEEE Trans Knowl Data Eng 24(5):926–939
Anand S, Mittal S, Tuzel O, Meer P (2013) Semi-supervised kernel mean shift clustering. IEEE Trans Pattern Anal Mach Intell 36(6):1201–1215
Liu CL, Hsaio WH, Lee CH, Gou FS (2013) Semi-supervised linear discriminant clustering. IEEE Trans Cybernet 44(7):989–1000
Lu Z, Peng Y (2013) Exhaustive and efficient constraint propagation: a graph-based learning approach and its applications. Int J Comput Vis 103(3):306–325
Xiong S, Azimi J, Fern XZ (2013) Active learning of constraints for semi-supervised clustering. IEEE Trans Knowl Data Eng 26(1):43–54
Zhang D, Chen S, Zhou ZH, Yang Q (2008) Constraint projections for ensemble learning. In AAAI, pp 758–763
Yu Z, Kuang Z, Liu J, Chen H, Zhang J, You J, Han G (2017) Adaptive ensembling of semi-supervised clustering solutions. IEEE Trans Knowl Data Eng 29(8):1577–1590
Yu Z, Luo P, Liu J, Wong HS, You J, Han G, Zhang J (2018) Semi-supervised ensemble clustering based on selected constraint projection. IEEE Trans Knowl Data Eng 30(12):2394–2407
Lai Y, He S, Lin Z, Yang F, Zhou QF, Zhou X (2019) An adaptive robust semi-supervised clustering framework using weighted consensus of random k-means ensemble. IEEE Trans Knowl Data Eng
Yang F, Li X, Li Q, Li T (2014) Exploring the diversity in cluster ensemble generation: random sampling and random projection. Expert Syst Appl 41(10):4844–4866
Li F, Qian Y, Wang J, Dang C, Liu B (2018) Cluster’s quality evaluation and selective clustering ensemble. ACM Trans Knowl Discov Data (TKDD) 12(5):1–27
Law MH, Topchy AP, Jain AK (2004) Multiobjective data clustering. In: Proceedings of the 2004 IEEE computer society conference on computer vision and pattern recognition, 2004. CVPR 2004, Vol 2, pp II–II
Alizadeh H, Minaei-Bidgoli B, Parvin H (2014) Cluster ensemble selection based on a new cluster stability measure. Intell Data Anal 18(3):389–408
Asuncion A, Newman D (2007) UCI machine learning repository
Cai D, He X, Han J, Huang TS (2010) Graph regularized nonnegative matrix factorization for data representation. IEEE Trans Pattern Anal Mach Intell 33(8):1548–1560
Statnikov A, Tsamardinos I, Dosbayev Y, Aliferis CF (2005) GEMS: a system for automated cancer diagnosis and biomarker discovery from microarray gene expression data. Int J Med Informat 74(7–8):491–503
Vinh NX, Epps J, Bailey J (2010) Information theoretic measures for clusterings comparison: variants, properties, normalization and correction for chance. J Mach Learn Res 11:2837–2854
Rand WM (1971) Objective criteria for the evaluation of clustering methods. J Am Stat Assoc 66(336):846–850
Wang H, Li T, Li T, Yang Y (2014) Constraint neighborhood projections for semi-supervised clustering. IEEE Trans Cybernet 44(5):636–643
Huang D, Wang CD, Wu JS, Lai JH, Kwoh CK (2019) Ultra-scalable spectral clustering and ensemble clustering. IEEE Trans Knowl Data Eng 32(6):1212–1226
Karypis G, Kumar V (1998) A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J Sci Comput 20(1):359–392
Huang R, Lam W, Zhang Z (2007) Active learning of constraints for semi-supervised text clustering. In: Proceedings of the 2007 SIAM international conference on data mining. Society for Industrial and Applied Mathematics, pp 113–124
Xiong C, Johnson DM, Corso JJ (2016) Active clustering with model-based uncertainty reduction. IEEE Trans Pattern Anal Mach Intell 39(1):5–17
Acknowledgements
This work was supported by Natural Science Basic Research Program of Shaanxi (Program no. 2021JM-133).
Funding
This work was supported by Natural Science Basic Research Program of Shaanxi (Program no. 2021JM-133).
Author information
Authors and Affiliations
Contributions
DZ contributed to the conception of the study and performed the data analyses and wrote the manuscript; DZ, YY performed the experiment; DZ, HQ contributed significantly to analysis and manuscript preparation; DZ, HQ helped perform the analysis with constructive discussions.
Corresponding author
Ethics declarations
Conflict of interest
No conflict of interest exits in the submission of this manuscript.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Code availability
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, D., Yang, Y. & Qiu, H. Two-stage semi-supervised clustering ensemble framework based on constraint weight. Int. J. Mach. Learn. & Cyber. 14, 567–586 (2023). https://doi.org/10.1007/s13042-022-01651-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-022-01651-2