
Abstract
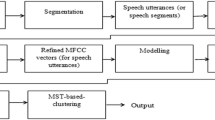
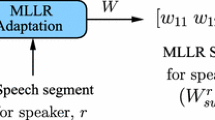
Speech clustering group the unlabeled speech utterances according to their similarity features and it requires prior information about number of speakers before assigning every speech utterance into its respective speaker cluster. Determine the number of speakers of speech dataset is a primary problem of speech clustering. Most methods follow the post clustering ideas for evaluation of number of speakers. After the recent study of cluster (or speakers) detection methods, it is found that visual access tendency (VAT) is most suitable approach for assessing the number of speakers information. However, it needs speaker model parameters for finding an accurate speakers information. By this motivation, the VAT is extended with Gaussian mixture model (GMM) for deriving of speakers information with model parameters. In the proposed work, speech data (i.e. speaker utterances or segment) is modeled by GMM, which derives GMM mean supervectors. Dissimilarity features are derived for a set of GMM mean supervectors in VAT for effective speech clustering. The GMM mean supervectors are high-dimensional and this dimensionality problem is addressed by generating intermediate vectors (i-vectors). Efficiency of proposed methods is demonstrated in the experimental study by real time datasets.




Similar content being viewed by others

References
Alam MJ, Gupta V, Kenny P, Dumouchel P (2015) Speech recognition in reverberant and noisy environments employing multiple feature extractors and i-vector speaker adaptation, pp 1–13
Anguera X (2012) Speaker independent discriminant feature extraction for acoustic pattern matching. In: Proceedings of the ICASSP
Arun P (2001) Data mining techniques. Universities Press, London
Cai D, He X, Han J (2005) Document clustering using locality preserving indexing. IEEE Trans Knowl Data Eng 17(2):1624–1637
Chu S, Tang H, Haung T (2009) Fishervoice and semi-supervised speaker clustering. In: Proceedings of the IEEE international acoustic speech and signal processing, pp 4089–4092
Dehak N, Kenny P, Dehak R, Dumouchel P, Ouellet P (2010) Front-end factor analysis for speaker verification. IEEE Trans Audio Speech Lang Process 19(4):788–798
Douglas DA, Reynolds A (2000) Speaker verification using adapted Gaussian mixture models. Digit Signal Proc 10:19–41
Ferras M, Madikeri S, Bourlard H (2016) Speaker diarization and linking of meeting data. IEEE/ACM Trans Audio Speech Lang Process 24(11):1935–1945
Gupta P, Sharma TK, Mehrotra D, Abraham A (2017) Knowledge building through optimized classification rule set generation using genetic based elitist multi objective approach. In: Neural computing and applications (NCAA), Springer. https://doi.org/10.1007/s00521-017-3042-4
Haipeng W, Tan L, Cheung CL, Bin M (2015) Acoustic segment modeling with spectral clustering methods. IEEE Trans Audio Speech Lang Process 23(2):264–277
Han J, Kamber M (2011) Data mining: concepts and techniques, 3rd edn. Morgan Kaufmann, San Francisco
Havens TC, Bezdek JC, Keller JM, Popescu M (2008) Dunn’s cluster validity index as contrast measure of VAT images. In: International conference, IEEE 2008
Jain A, Dubes R (1988) Algorithms for clustering data. Prentice Hall, New York
Lee Y, Glass J (2012) A nonparametric Bayesian approach to acoustic model discovery. In: Proceedings of ACL
Li L, Wang D, Zhang C, Zheng TF (2016) Improving short utterance speaker recognition by modeling speech unit classes. IEEE/ACM Trans Audio Speech Lang Process 24(6):1129–1139
Lovasz L, Plummer M (1986) Matching theory. Budapest, Northholland
Mohammad S, Patrick K (2014) A study of the cosine distance-based mean shift for telephone speech diarization. IEEE/ACM Trans Audio Speech Lang Process 22(1):217–227
Rafaely B, Kolossa D, Maymon Y (2017) Towards acoustically robust localization of speakers in a reverberant environment. In: Hands-free speech communications and microphone arrays (HSCMA), pp 10–16
Rajpurohit J, Sharma TK, Abraham A, Vaishali A (2017) Glossary of metaheuristic algorithms. Int J Comput Inf Syst Ind Manag Appl 9:181–205
Roberto T (2011) An overview of speaker identification: accuracy and robustness issues. IEEE Circuits Syst Mag 11:23–61
Saki F, Kehtarnavaz N (2017) Real-time unsupervised classification of environmental noise signals. IEEE/ACM Transa Audio Speech Lang Process 22(8):1657–1667
Sangeeta B, Rohdin J, Shinoda K (2015) Autonomous selection of i-vectors for PLDA modeling in speaker verification. Speech Commun 72:32–46
Senoussaoui M, Patrick K, Themo S, Dumouchel P (2013) Efficient iterative mean shift based cosine dissimilarity for mutli-recording speaker clustering. In: Proceedings of ICASSP, pp 7712–7715
Sharma TK, Pant M (2016) Identification of noise in multi noise plant using enhanced version of shuffled frog leaping algorithm. Int J Syst Assur Eng Manag. https://doi.org/10.1007/s13198-016-0466-7
Stephen SH, Dehak N, Dehak R, Glass J (2013) Unsupervised methods for speaker diarization: an integrated and iterative approach. IEEE Trans Audio Speech Lang Process 21(10):2015–2028
Tang S, Chu S (2012) Partially supervised speaker clustering. IEEE Trans Pattern Anal Mach Intell 34(5):959–971
Varadarajan B, Khudanpur S, Dupoux E (2008) Unsupervised learning of acoustic subword units. In: ACL-08: HLT
Wang L, Geng X, Bezdek J, Leckie C, Ramamohanarao K (2010) Enhanced visual analysis for cluster tendency assessment and data partitioning. IEEE Trans Knowl Data Eng 22(10):1401–1414
Xie XL, Beni G (1991) A validity measure for fuzzy clustering. IEEE Trans Pattern Anal Mach Int 13:841–847
Zeinali H, Sameti H, Burget L (2017) HMM-based phrase-independent i-vector extractor for text-dependent speaker verification. IEEE/ACM Trans Audio Speech Lang Process 25(7):1421–1435
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Suneetha Rani, T., Krishna Prasad, M.H.M. Access the number of speakers through visual access tendency for effective speech clustering. Int J Syst Assur Eng Manag 9, 559–566 (2018). https://doi.org/10.1007/s13198-018-0703-3
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-018-0703-3