
Abstract
Social networks and social media have played a key role for observing and influencing how the political landscape takes shape and dynamically shifts. It is especially true in events such as national elections as indicated by earlier studies with Facebook (Williams and Gulati, in: Proceedings of the annual meeting of the American Political Science Association, 2009) and Twitter (Larsson and Moe in New Med Soc 14(5):729–747, 2012). Not surprisingly in an attempt to better understand and simplify these networks, community discovery methods have been used, such as the Louvain method (Blondel et al. in J Stat Mechanics Theory Exp 2008(10):P10008, 2008) to understand elections (Gaumont et al. in PLoS ONE 13(9):e0201879, 2018). However, most community-based studies first simplify the complex Twitter data into a single network based on (for example) follower, retweet or friendship properties. This requires ignoring some information or combining many types of information into a graph, which can mask many insights. In this paper, we explore Twitter data as a time-stamped vertex-labeled graph. The graph structure can be given by a structural relation between the users such as retweet, friendship or follower relation, whilst the behavior of the individual is given by their posting behavior which is modeled as a time-evolving vertex labels. We explore leveraging existing community discovery methods to find communities using just the structural data and then describe these communities using behavioral data. We explore two complimentary directions: (1) creating a taxonomy of hashtags based on their community usage and (2) efficiently describing the communities expanding our recently published work. We have created two datasets, one each for the French and US elections from which we compare and contrast insights on the usage of hashtags.
























Similar content being viewed by others
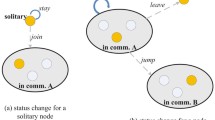


Notes
bush,carson,christie,cruz,fiorina,gilmore,graham,huckabee, kasich,pataki,paul,rubio,santorum,trump.
copé,coppé,fillon,kosciusko-morizet,nkm,lefebvre,le maire,mariton,morano,myard,poisson,sarkozy,sarkosi,sarkosy
,sarko,wauquiez,guaino,aliot-marie,allio-marie.
We performed preliminary experiments for comparing different clustering algorithms from the literature. We found that the Louvain method used by Gaumont et al. (2018) in a similar context leads to the fastest and most robust solution. Furthermore, a thorough comparison with many state-of-the-art clustering algorithms draws the same conclusion in Yang et al. (2016).
To do so, we used the Mclust package (Fraley and Raftery 2006).
using the DTW package (Giorgino and Giorgino 2018).
When there is no ambiguity, we remove the sharp symbol, that means Trump stands for #Trump.
References
Aragón Pablo, Kappler Karolin Eva, Kaltenbrunner Andreas, Laniado David, Volkovich Yana (2013) Communication dynamics in Twitter during political campaigns: the case of the 2011 Spanish national election. Policy Internet 5(2):183–206
Blondel VD, Guillaume J-L, Lambiotte R, Lefebvre E (2008) Fast unfolding of communities in large networks. J Stat Mech Theory Exp 2008(10):P10008
Bryden J, Funk S, Jansen VAA (2013) Word usage mirrors community structure in the online social network Twitter. EPJ Data Sci 2(1):3
Conover M, Ratkiewicz J, Francisco MR, Gonçalves B, Menczer F, Flammini A (2011) Political polarization on Twitter. Proc Int Conf Web Soc Med (ICWSM) 133:89–96
Davidson I, Gourru A, Ravi SS (2018) The clustering description problem: complexity results, algorithms and applications. In NIPS 2018
Enli G (2017) Twitter as arena for the authentic outsider: exploring the social media campaigns of Trump and Clinton in the 2016 US presidential election. Eur J Commun 32(1):50–61
Fraisier O, Cabanac G, Pitarch Y, Besançon R, Boughanem M (2018) #lyse2017fr: The 2017 French presidential campaign on twitter. Stanford, California, pp 501–510
Fraley C, Raftery AE (2006) Mclust version 3: an r package for normal mixture modeling and model-based clustering. Technical report, Washington Univ. Seattle Dpt. of Statistics
Gaumont N, Panahi M, Chavalarias D (2018) Reconstruction of the socio-semantic dynamics of political activist Twitter networks—method and application to the 2017 French presidential election. PLoS One 13(9):e0201879
Giorgino T, Giorgino MT (2018) Package dtw
Girvan M, Newman MEJ (2002) Community structure in social and biological networks. Proc Natl Acad Sci 99(12):7821–7826
Herring SC, Paolillo JC, Ramos-Vielba I, Kouper I, Wright E, Stoerger S, Scheidt LA, Clark B (2007) Language networks on livejournal. In: 2007 40th Annual Hawaii International Conference on System Sciences (HICSS’07). IEEE, pp 79–79
Hong L, Convertino G, Chi EH (2011) Language matters in Twitter: a large scale study. In: 5th International AAAI conference on weblogs and social media
Johnson TJ, Perlmutter DD (2013) New media, campaigning and the 2008 Facebook election. Routledge, Abingdon
Kouloumpis E, Wilson T, Moore JD (2011) Twitter sentiment analysis: the good the bad and the omg! In: Proceedings of the international conference on web and the social media (ICWSM) 11(538–541):164
Kuo C-T, Ravi SS, Vrain C, Davidson I, et al (2018) Descriptive clustering: ILP and CP formulations with applications. In: IJCAI-ECAI 2018, the 27th International Joint Conference on Artificial Intelligence and the 23rd European Conference on Artificial Intelligence
Larsson AO, Moe H (2012) Studying political microblogging: Twitter users in the 2010 Swedish election campaign. New Med Soc 14(5):729–747
Ng, AY, Jordan MI, Weiss Y (2002) On spectral clustering: analysis and an algorithm. In: Advances in neural information processing systems, pp 849–856
Perrin A (2015) Social media usage. Pew Research Center, pp 52–68
Poblete B, Garcia R, Mendoza M, Jaimes A (2011) Do all birds tweet the same?: characterizing Twitter around the world. In: Proceedings of the 20th ACM international conference on Information and knowledge management. ACM, pp 1025–1030
Quraishi M, Fafalios P, Herder E (2018) Viewpoint discovery and understanding in social networks. In: Proceedings of the 10th ACM Conference on Web Science. ACM, pp 47–56
Romero DM, Meeder B, Kleinberg J (2011) Differences in the mechanics of information diffusion across topics: idioms, political hashtags, and complex contagion on Twitter. In: Proceedings of the 20th international conference on World wide web. ACM, pp 695–704
Smith MA, Rainie L, Shneiderman B, Himelboim I (2014) Mapping Twitter topic networks: from polarized crowds to community clusters. Pew Research Center (https://www.pewinternet.org/2014/02/20/mapping-twitter-topic-networks-from-polarized-crowds-to-community-clusters)
Torgerson WS (1958) Theory and methods of scaling
Velcin J, Kim Y-M, Brun C, Dormagen J-Y, SanJuan E, Khouas L, Peradotto A, Bonnevay S, Roux C, Boyadjian J et al (2014) Investigating the image of entities in social media: Dataset design and first results. In: LREC, pp 818–822
Wang Y, Zheng B (2014) On macro and micro exploration of hashtag diffusion in Twitter. In: Proceedings of the IEEE/ACM international conference on advances in social networks analysis and mining. IEEE Press, pp 285–288
Williams C, Gulati G (2009) What is a social network worth? Facebook and vote share in the 2008 presidential primaries. In: Proceedings of the annual meeting of the American Political Science Association
Wong FMF, Tan CW, Sen S, Chiang M (2016) Quantifying political leaning from tweets, retweets, and retweeters. IEEE Trans Knowl Data Eng 28(8):2158–2172
Yang J, Leskovec J (2010) Modeling information diffusion in implicit networks. In: IEEE international conference on data mining. IEEE, pp 599–608
Yang Z, Algesheimer R, Tessone CJ (2016) A comparative analysis of community detection algorithms on artificial networks. Sci Rep 6:30750
Author information
Authors and Affiliations
Corresponding author
Additional information
IIan Davidson was a visiting Fellow at the French Institute of Advanced Studies (Collegium de Lyon) when this research was completed. All code and data used in this paper are available at www.cs.ucdavis.edu/~davidson/description-clustering/SNAM_code
Appendices
Appendix 1: community extraction, a deeper analysis
In this section, we propose a deeper analysis of the community extraction in our dataset. First, we demonstrate that filtering the users does not affect the general community structure. Second, we attempt to label the communities using well-known accounts. We next explore the properties of the subgraph for each community. For example, do some communities have more denser connections than others that is, is the Trump community subgraph more denser than the Clinton subgraph? (Yes it is, even though their clustering coefficient is similar).
1.1 High-impact users
Despite the Louvain method’s scalability, we will focus on high-impact users during this study for clarity of interpretation. We, therefore, must ensure a community structure similar to the full network found in the network of high-impact users we select. To evaluate this requirement, we analyze whether adding users with lower in-degree (less impact) will modify the community structure found using only high-impact users as follows.
We first build the retweet network of the 100 users with the higher in-degrees and then perform a Louvain community detection (Blondel et al. 2008). We then compute the ARI between this clustering output and the clustering of the 200 users Retweet network and then the ARI between the 200-node clustering and a 300-node clustering and repeat this process until we reach 13,000 users. This produces a measure of the perturbation of the community structure when adding nodes with lower and lower in-degree. The results are shown in Fig. 25. Starting from 7000, perturbation seems to be minimal for US retweet network. For the French networks, convergence seems to happen around 10,000 users. For ease of comparison, we used the 10,000 most influential accounts for both datasets. Hence from now on all experimental results will be on the 10,000 users with the highest in-degree.

Perturbation of community structure when adding new vertices. The measure is the adjusted Rand index.(left : USA, right: France). Note the ARI is measured between adjacent datasets, that is the between a dataset of x accounts and \(x+100\)
1.2 Validation of communities
For further analysis, we would like to label the community obtained in the previous section. A straightforward approach for getting a better understanding of a group of users lies in the identification of the most central users. To this end, we extract the subgraph of each community and we compute the Page Rank score for every user. Results are shown in Tables 10 (US politics, 6 clusters) and 11 (French politics, 7 clusters). It is a simple way to check whether there is a clear political leaning for an observer of US or French politics. There is a clear political polarization of the communities we found. For instance, if we look at the nodes most central to the cluster 4 (US dataset) we can see many accounts that have a clear political orientation in favor of D. Trump including the candidate, his children and the news outlets that favor him (e.g., @realDonaldTrump, @DonaldTrumpJr, @FoxNews, @foxandfriends). We choose to simply label this cluster as “Trump.” Similarly, cluster 3 has the political candidate Bernie Sanders and the news outlets that are supportive of him (e.g., @CNNPolitics, @ABC, @GMA); hence, we label it as “Sanders.” For the French dataset, most of the discovered clusters are identifiable. For instance, the cluster 2 is related to political personalities and media that can be associated to the left wing of French politics (e.g., @najatvb of Najat Belkacem, radio account @lelab_e1, @ellensalvi of the Mediapart journalist Ellen Salvi). The cluster 5 is clearly related to the Front National party (e.g., @f_philippot of F. Filippot, @tprincedelamour and @avec_marine that are a clear support of the candidate M. Le Pen). Therefore, it is rather straightforward to give them a first label to help in understanding the analysis that is carried out in the next sections. There is no surprise we cannot assign a good label to the Lambda cluster since it is composed of a myriad of small communities. In both datasets, we can also see one cluster (number 6 for the US and 7 for France) that has no clear political orientation and we choose to label these two clusters as “Others.”
Table 12 shows a set of classic graph measures that have been calculated on the same set of communities (US dataset, top table, and French dataset, bottom table). It is not surprising that the Lambda community’s diameter is small due to its low size. Furthermore, this pseudo-community is characterized by a very low mean in-degree (at least ten times less than the others are) and eigen centrality (at least five times less). This is also the case for the Others community as it is a very sparsely connected community. For these reasons, we choose not to focus on these two loosely defined communities for the rest of our analysis. For the US dataset, the higher clustering coefficient can be explained: Locally, the neighborhood of a node has higher chances to get connected together because of the components size (small diameter). However, we do not observe the same for the French dataset.
The remaining communities (4 for the USA and 5 for France) share that they are much denser and with a higher in-degree. However, it is interesting to note some differences. For instance, the Trump community is much denser than all the other communities if we look at the mean degree, so is the Sarkozy community. Their respective diameter values seem to be lower (8 for Trump and 7 for Sarkozy). It is also interesting to note that the clustering coefficient is uniformly smaller for the French communities than the USA communities indicating a more spoke to hub arrangement for the later.
Appendix 2: The allocation of hashtags to our taxonomy
See Tables 10, 11, 12, 13, 14, 15 and 16.
Here we list the allocation of hashtags to the taxonomy created in Fig. 7.
Rights and permissions
About this article

Cite this article
Davidson, I., Gourru, A., Velcin, J. et al. Behavioral differences: insights, explanations and comparisons of French and US Twitter usage during elections. Soc. Netw. Anal. Min. 10, 6 (2020). https://doi.org/10.1007/s13278-019-0611-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13278-019-0611-9