
Abstract
Classifying tweets containing valuable information about COVID-19 is crucial for developing monitoring systems that provide the latest updates. Existing approaches for informative tweet classification considers only the last layer vector of a special token by ignoring the vectors of other tokens and the token vectors from the previous layers. The paper addresses this drawback by proposing a novel approach which (i) makes use of all the token vectors from the last four layers and (ii) leverages additional information in the form of POS tags and informative words. Experiment results show that the proposed approach outperforms all the existing approaches and achieves an accuracy of 92% and F1-score of 92.01% on the COVID-19 informative tweets dataset. The uniqueness of this paper is the attempt to leverage token vectors from the last four layers, additional information in the form of POS tags and informative words from COVID-19 informative tweets for classification.














Similar content being viewed by others
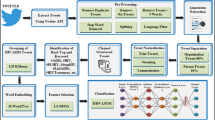
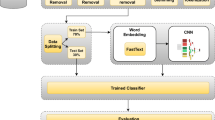
Data availability
The dataset used in this paper is available in the Github repository https://github.com/VinAIResearch/COVID19Tweet/blob/master/WNUT-2020-Task-2-Dataset.zip.
References
Babu YP, Eswari R (2020) CIA NITT at WNUT-2020 task 2: classification of covid-19 tweets using pre-trained language models. https://arxiv.org/abs/2009.05782
Bangyal WH, Qasim R, Ahmad Z et al (2021) Detection of fake news text classification on covid-19 using deep learning approaches. Comput Math Methods Med 2021:1–14
Bao LD, Nguyen VA, Huu QP (2020) Sunbear at wnut-2020 task 2: improving bert-based noisy text classification with knowledge of the data domain. In: Proceedings of the sixth workshop on noisy user-generated text (W-NUT 2020), pp 485–490
Bojanowski P, Grave E, Joulin A et al (2017) Enriching word vectors with subword information. Trans Assoc Comput Linguist 5:135–146
Chatsiou K (2020) Text classification of covid-19 press briefings using Bert and convolutional neural networks. https://arxiv.org/abs/2010.10267
Chen S, Huang Y, Huang X, et al (2019) Hitsz-icrc: a report for smm4h shared task 2019-automatic classification and extraction of adverse effect mentions in tweets. In: Proceedings of the fourth social media mining for health applications (# SMM4H) workshop & shared task, pp 47–51
Devlin J, Chang MW, Lee K, et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, Volume 1 (Long and Short Papers), pp 4171–4186
Jagadeesh M, Alphonse P (2020) Nit covid-19 at wnut-2020 task 2: deep learning model Roberta for identify informative covid-19 English tweets. In: Proceedings of the sixth workshop on noisy user-generated text (W-NUT 2020), pp 450–454
Kim Y (2014) Convolutional neural networks for sentence classification. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). Association for Computational Linguistics, Doha, Qatar, pp 1746–1751
Kothuru S, Santhanavijayan A (2023) Identifying covid-19 English informative tweets using limited labelled data. Soc Netw Anal Min 13(1):25
Kumar P, Singh A (2020) Nutcracker at wnut-2020 task 2: Robustly identifying informative covid-19 tweets using ensembling and adversarial training. In: Proceedings of the sixth workshop on noisy user-generated text (W-NUT 2020), pp 404–408
Liu Y, Ott M, Goyal N, et al (2019) Roberta: A robustly optimized bert pretraining approach. https://arxiv.org/abs/1907.11692
Loshchilov I, Hutter F (2017) Decoupled weight decay regularization. https://arxiv.org/abs/1711.05101
M ̈uller M, Salath ́e M, Kummervold PE (2020) Covid-twitter-bert: a natural language processing model to analyse covid-19 content on twitter. https://arxiv.org/abs/2005.07503
Madichetty S, Sridevi M (2021) A novel method for identifying the damage assessment tweets during disaster. Futur Gener Comput Syst 116:440–454
Madichetty S, Muthukumarasamy S, Jayadev P (2021) Multi-modal classification of twitter data during disasters for humanitarian response. J Ambient Intell Human Comput 12(11):10223–10237
Madichetty S et al (2021b) A stacked convolutional neural network for detecting the resource tweets during a disaster. Multimed Tools Appl 80(3):3927–3949
Malla S, Alphonse P (2021) Covid-19 outbreak: an ensemble pre-trained deep learning model for detecting informative tweets. Appl Soft Comput 107(107):495
Mikolov T, Chen K, Corrado G, et al (2013) Efficient estimation of word representations in vector space. https://arxiv.org/abs/1301.3781
Minaee S, Kalchbrenner N, Cambria E, et al (2020) Deep learning based text classification: a comprehensive review. https://arxiv.org/abs/2004.03705
Møller AG, Van Der Goot R, Plank B (2020) NLP north at wnut-2020 task 2: pre-training versus ensembling for detection of informative covid-19 English tweets. In: Proceedings of the sixth workshop on noisy user-generated text (W-NUT 2020), pp 331–336
Nguyen DQ, Vu T, Nguyen AT (2020a) Bertweet: a pre-trained language model for English tweets. https://arxiv.org/abs/2005.10200
Nguyen DQ, Vu T, Rahimi A, et al (2020b) WNUT-2020 Task 2: identification of informative COVID-19 English tweets. In: Proceedings of the 6th workshop on noisy user-generated text
Nimmi K, Janet B, Kalai SA et al (2022) Pre-trained ensemble model for identification of emotion during covid-19 based on emergency response support system dataset. Appl Soft Comput 120(108):842
Nowak J, Taspinar A, Scherer R (2017) LSTM recurrent neural networks for short text and sentiment classification. In: International conference on artificial intelligence and soft computing, Springer, pp 553–562
Pedregosa F, Varoquaux G, Gramfort A et al (2011) Scikit-learn: machine learning in python. J Mach Learn Res 12:2825–2830
Pennington J, Socher R, Manning C (2014) GloVe: global vectors for word representation. In: Moschitti A, Pang B, Daelemans W (eds) Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). Association for Computational Linguistics, Doha, Qatar, pp 1532–154
Matthew P, Mark N, Mohit I, Matt G, Christopher C, Kenton L, Luke Z (2018) Deep contextualized word representations. In: Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, 1: 2227–2237
Sanh V, Debut L, Chaumond J, et al (2019) Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. https://arxiv.org/abs/1910.01108
Sreenivasulu M, Sridevi M (2018) A survey on event detection methods on various social media. In: Recent findings in intelligent computing techniques. Springer, pp 87–93
Sreenivasulu M, Sridevi M (2020) Comparative study of statistical features to detect the target event during disaster. Big Data Min Anal 3(2):121–130
Waheeb SA, Khan NA, Shang X (2022) An efficient sentiment analysis based deep learning classification model to evaluate treatment quality. Malays J Comput Sci 35(1):1–20
Zhang X, Zhao J, LeCun Y (2015) Character-level convolutional networks for text classification. In: Advances in neural information processing systems, pp 649–657
Acknowledgements
Not applicable.
Funding
The authors declare that they have not received any funding.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to complete the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Ethics approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yandrapati, P.B., Eswari, R. Classifying informative tweets using feature enhanced pre-trained language model. Soc. Netw. Anal. Min. 14, 48 (2024). https://doi.org/10.1007/s13278-024-01204-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13278-024-01204-1