
Abstract
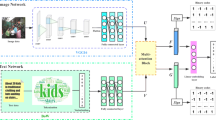
Multimodal hash technology maps high-dimensional multimodal data into hash codes, which greatly reduces the cost of data storage and improves query speed through the Hamming similarity calculation. However, existing unsupervised methods still have two key obstacles: (1) With the evolution of large multimodal models, how to efficiently distill the multimodal matching relationship of large models to train a powerful student model? (2) Existing methods do not consider other adjacencies between multimodal instances, resulting in limited similarity representation. To address these obstacles, called Unsupervised Graph Reasoning Distillation Hashing (UGRDH) is proposed. The UGRDH approach uses the CLIP as the teacher model, thus extracting fine-grained multimodal features and relations for teacher–student distillation. Specifically, the multimodal features of the teacher are used to construct a similarity–complementary relation graph matrix, and the proposed graph convolution auxiliary network performs feature aggregation guided by the relation graph matrix to generate a more discriminative hash code. In addition, a cross-attention module was designed to reason potential instance relations to enable effective teacher–student distilled learning. Finally, UGRDH greatly improves search precision while maintaining lightness. Experimental results show that our method achieves about 1.5%, 3%, and 2.8% performance improvements on MS COCO, NUS-WIDE, and MIRFlickr, respectively.








Similar content being viewed by others


Data Availability
The data that supports the findings of this study will be made available on request.
References
Luo X, Wang H, Wu D, Chen C, Deng M, Huang J, Hua X-S (2023) A survey on deep hashing methods. ACM Trans Knowl Discov Data 17(1):1–50
Zhu L, Zheng C, Guan W, Li J, Yang Y, Shen HT (2023) Multi-modal hashing for efficient multimedia retrieval: a survey. IEEE Trans Knowl Data Eng
Li L, Zheng B, Sun W (2022) Adaptive structural similarity preserving for unsupervised cross modal hashing. In: Proceedings of the 30th ACM international conference on multimedia, pp 3712–3721
Singh A, Gupta S (2022) Learning to hash: a comprehensive survey of deep learning-based hashing methods. Knowl Inf Syst 64(10):2565–2597
Su S, Zhong Z, Zhang C (2019) Deep joint-semantics reconstructing hashing for large-scale unsupervised cross-modal retrieval. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 3027–3035
Liu S, Qian S, Guan Y, Zhan J, Ying L (2020) Joint-modal distribution-based similarity hashing for large-scale unsupervised deep cross-modal retrieval. In: Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval, pp 1379–1388
Wang B, Zhang H, Zhu L, Nie L, Liu L (2023) Multi-level adversarial attention cross-modal hashing. Signal Processing: Image Communication, 117017
Zhang P-F, Luo Y, Huang Z, Xu X-S, Song J (2021) High-order nonlocal hashing for unsupervised cross-modal retrieval. World Wide Web 24(2):563–583
Shen X, Zhang H, Li L, Liu L (2021) Attention-guided semantic hashing for unsupervised cross-modal retrieval. In: 2021 IEEE international conference on multimedia and expo (ICME), pp 1–6. IEEE
Mikriukov G, Ravanbakhsh M, Demir B (2022) Unsupervised contrastive hashing for cross-modal retrieval in remote sensing. In: ICASSP 2022–2022 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 4463–4467. IEEE
Tan W, Zhu L, Li J, Zhang Z, Zhang H (2023) Partial multi-modal hashing via neighbor-aware completion learning. IEEE Trans Multimedia
Tu R-C, Jiang J, Lin Q, Cai C, Tian S, Wang H, Liu W (2023) Unsupervised cross-modal hashing with modality-interaction. IEEE Trans Circuits Syst Video Technol
Wang Z, Yu J, Yu AW, Dai Z, Tsvetkov Y, Cao Y (2021) Simvlm: simple visual language model pretraining with weak supervision. arXiv preprint arXiv:2108.10904
Chen F-L, Zhang D-Z, Han M-L, Chen X-Y, Shi J, Xu S, Xu B (2023) Vlp: a survey on vision-language pre-training. Mach Intell Res 20(1):38–56
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, et al (2021) Learning transferable visual models from natural language supervision. In: International conference on machine learning, pp 8748–8763
Gu X, Lin T-Y, Kuo W, Cui Y (2021) Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921
Guo J, Guan X, Liu Y, Lu Y (2023) Distillation-based hashing transformer for cross-modal vessel image retrieval. IEEE Geosci Remote Sens Lett
Hu H, Xie L, Hong R, Tian Q (2020) Creating something from nothing: unsupervised knowledge distillation for cross-modal hashing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3123–3132
Li M, Wang H (2021) Unsupervised deep cross-modal hashing by knowledge distillation for large-scale cross-modal retrieval. In: Proceedings of the 2021 international conference on multimedia retrieval, pp 183–191
Luo K, Zhang C, Li H, Jia X, Chen C (2023) Adaptive marginalized semantic hashing for unpaired cross-modal retrieval. IEEE Trans Multimedia
Tan W, Zhu L, Guan W, Li J, Cheng Z (2022) Bit-aware semantic transformer hashing for multi-modal retrieval. In: Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, pp 982–991
Hou C, Li Z, Tang Z, Xie X, Ma H (2022) Multiple instance relation graph reasoning for cross-modal hash retrieval. Knowl-Based Syst 256:109891
Liu L, Nie F, Wiliem A, Li Z, Zhang T, Lovell BC (2018) Multi-modal joint clustering with application for unsupervised attribute discovery. IEEE Trans Image Process 27(9):4345–4356
Liu L, Nie F, Zhang T, Wiliem A, Lovell BC (2016) Unsupervised automatic attribute discovery method via multi-graph clustering. In: 2016 23rd International conference on pattern recognition (ICPR), pp 1713–1718. IEEE
Shi Y, Zhao Y, Liu X, Zheng F, Ou W, You X, Peng Q (2022) Deep adaptively-enhanced hashing with discriminative similarity guidance for unsupervised cross-modal retrieval. IEEE Trans Circuits Syst Video Technol
Welling M, Kipf TN (2016) Semi-supervised classification with graph convolutional networks. In: International conference on learning representations (ICLR 2017)
Zhang P-F, Li Y, Huang Z, Xu X-S (2021) Aggregation-based graph convolutional hashing for unsupervised cross-modal retrieval. IEEE Trans Multimedia 24:466–479
Tan W, Zhu L, Li J, Zhang H, Han J (2022) Teacher-student learning: efficient hierarchical message aggregation hashing for cross-modal retrieval. IEEE Trans Multimedia
Wu F, Li S, Gao G, Ji Y, Jing X-Y, Wan Z (2023) Semi-supervised cross-modal hashing via modality-specific and cross-modal graph convolutional networks. Pattern Recognit 136:109211
Zhou X, Shen F, Liu L, Liu W, Nie L, Yang Y, Shen HT (2018) Graph convolutional network hashing. IEEE Trans Cybern 50(4):1460–1472
Lu X, Zhu L, Liu L, Nie L, Zhang H (2021) Graph convolutional multi-modal hashing for flexible multimedia retrieval. In: Proceedings of the 29th ACM international conference on multimedia, pp 1414–1422
Khan S, Naseer M, Hayat M, Zamir SW, Khan FS, Shah M (2022) Transformers in vision: a survey. ACM Comput Surv 54(10s):1–41
Kim W, Son B, Kim I (2021) Vilt: vision-and-language transformer without convolution or region supervision. In: International conference on machine learning, pp 5583–5594
Li J, Selvaraju R, Gotmare A, Joty S, Xiong C, Hoi SCH (2021) Align before fuse: vision and language representation learning with momentum distillation. Adv Neural Inf Process Syst 34:9694–9705
Bao H, Wang W, Dong L, Liu Q, Mohammed OK, Aggarwal K, Som S, Wei F (2021) Vlmo: unified vision-language pre-training with mixture-of-modality-experts. arXiv preprint arXiv:2111.02358
Li X, Yin X, Li C, Zhang P, Hu X, Zhang L, Wang L, Hu H, Dong L, Wei F, et al (2020) Oscar: object-semantics aligned pre-training for vision-language tasks. In: European conference on computer vision, pp 121–137. Springer
Gou J, Yu B, Maybank SJ, Tao D (2021) Knowledge distillation: a survey. Int J Comput Vis 129:1789–1819
Tung F, Mori G (2019) Similarity-preserving knowledge distillation. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1365–1374
Zhang X, Wang X, Cheng P (2023) Unsupervised hashing retrieval via efficient correlation distillation. IEEE Trans Circuits Syst Video Technol
Ma Y, Xu G, Sun X, Yan M, Zhang J, Ji R (2022) X-clip: end-to-end multi-grained contrastive learning for video-text retrieval. In: Proceedings of the 30th ACM international conference on multimedia, pp 638–647
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Wang D, Wang Q, He L, Gao X, Tian Y (2020) Joint and individual matrix factorization hashing for large-scale cross-modal retrieval. Pattern Recognit 107:107479
Ding G, Guo Y, Zhou J, Gao Y (2016) Large-scale cross-modality search via collective matrix factorization hashing. IEEE Trans Image Process 25(11):5427–5440
Yang D, Wu D, Zhang W, Zhang H, Li B, Wang W (2020) Deep semantic-alignment hashing for unsupervised cross-modal retrieval. In: Proceedings of the 2020 international conference on multimedia retrieval, pp 44–52
Yu J, Zhou H, Zhan Y, Tao D (2021) Deep graph-neighbor coherence preserving network for unsupervised cross-modal hashing. In: Proceedings of the AAAI conference on artificial intelligence, vol 35, pp 4626–4634
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: common objects in context. In: European conference on computer vision, pp 740–755. Springer
Chua T-S, Tang J, Hong R, Li H, Luo Z, Zheng Y (2009) Nus-wide: a real-world web image database from National University of Singapore. In: Proceedings of the ACM international conference on image and video retrieval, pp 1–9
Huiskes MJ, Lew MS (2008) The mir flickr retrieval evaluation. In: Proceedings of the 1st ACM international conference on multimedia information retrieval, pp 39–43
Wang W, Shen Y, Zhang H, Yao Y, Liu L (2021) Set and rebase: determining the semantic graph connectivity for unsupervised cross-modal hashing. In: Proceedings of the twenty-ninth international conference on international joint conferences on artificial intelligence, pp 853–859
Zhang J, Peng Y, Yuan M (2018) Unsupervised generative adversarial cross-modal hashing. In: Proceedings of the AAAI conference on artificial intelligence, vol 32
Wu G, Lin Z, Han J, Liu L, Ding G, Zhang B, Shen J (2018) Unsupervised deep hashing via binary latent factor models for large-scale cross-modal retrieval. In: IJCAI, vol 1, p 5
Acknowledgements
This work was supported by the Open Fund of Advanced Cryptography and System Security Key Laboratory of Sichuan Province (Grant No. SKLACSS–202208), National Natural Science Foundation of China (No.61772295), Postgraduate Scientific Research Innovation Project of Chongqing Normal University(YKC23025) and the Science and Technology Research Program of Chongqing Municipal Education Commission (Grant no.KJZD-M202000501).
Author information
Authors and Affiliations
Contributions
LS writing original draft preparation, YD writing review and editing, supervision, funding acquisition, All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that the publication of this paper has no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sun, L., Dong, Y. Unsupervised graph reasoning distillation hashing for multimodal hamming space search with vision-language model. Int J Multimed Info Retr 13, 16 (2024). https://doi.org/10.1007/s13735-024-00326-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13735-024-00326-8