
Abstract
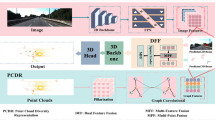
To address the impact of sparsity and disorder of point clouds on object detection accuracy, this paper proposes a multi-modal fusion network VPC-VoxelNet based on virtual point clouds. Firstly, virtual point clouds are constructed using image detection object information to increase the density of point clouds, thus improving the performance of object features; Secondly, increasing the dimensionality of point cloud features, distinguishing virtual point clouds and avoiding the accumulation of multi model errors; Finally, an optimized loss function such as the scale factor of the virtual point cloud is used to improve the training efficiency of the multi-modal network. The object detection network, VPC-VoxelNet, was tested on the KITTI dataset, and the detection accuracy was better than that of the classical 3D point cloud detection network and certain multi-modal information fusion networks, with a vehicle detection accuracy of 86.9%.









Similar content being viewed by others


Data availability
No datasets were generated or analysed during the current study.
References
Alaba SY, Ball JE (2022) A survey on deep- learning-based LiDAR 3D object detection for autonomous driving. Sensors 22:9577
Han J, Chen H, Liu N, Yan C, Li X (2018) CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion. IEEE Trans Cybern 48:3171–3183
Hackett JK, Shah M (1990) Multi-sensor fusion: a perspective. In: IEEE international conference on robotics and automation proceedings, pp1324–1330
Vora S, Lang AH, Helou B, Beijbom O (2020) PointPainting: sequential fusion for 3D object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 4604–4612
Vyas A, et al (2018) Out-of-distribution detection using an ensemble of self supervised leave-out classifiers. In: Proceedings of the European conference on computer vision (ECCV), pp 550–564
Huang T, Liu Z, Chen X, Bai X (2020) EPNet: enhancing point features with image semantics for 3D object detection. In: Computer vision—ECCV 2020, pp 35–52
Liang M, Yang B, Wang S, Urtasun R (2018) Deep continuous fusion for multi-sensor 3D object detection. In: Proceedings of the European conference on computer vision (ECCV), pp 641–656
Qi CR, Liu W, Wu C, Su H, Guibas LJ (2018) Frustum PointNets for 3D object detection from RGB-D data. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 918–927
Wang Z, Jia K (2019) Frustum ConvNet: sliding frustums to aggregate local point-wise features for amodal 3D object detection. In: 2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 1742–1749
Huang K, et al (2022) Multi-modal sensor fusion for auto driving perception: a survey. Preprint at https://doi.org/10.48550/arXiv.2202.02703
Zhuang F, Qi Z, Duan K, Xi D, Zhu Y, Zhu H, Xiong H, He Q (2020) A comprehensive survey on transfer learning. Proc IEEE 109:43–76
Xia Y, Xia Y, Li W, Song R, Cao K, Stilla U (2021) ASFM-Net: asymmetrical siamese feature matching network for point completion. In: Proceedings of the 29th ACM international conference on multimedia (MM '21). Association for Computing Machinery, New York, pp 1938–1947
Xia Y, Xu Y, Wang C, Stilla U (2020) VPC-Net: completion of 3D vehicles from MLS point clouds. ISPRS J Photogramm Remote Sens 174:166
Drobnitzky M, Friederich J, Egger B, Zschech P (2023) Survey and systematization of 3D object detection models and methods. Vis Comput 40:1867
Qi CR, Su H, Mo K, Guibas LJ (2017) PointNet: deep learning on point sets for 3D Classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 652–660
Zhou Y, Tuzel O (2018) VoxelNet: end-to-end learning for point cloud based 3D object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4490–4499
Lang AH et al (2019) PointPillars: fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12697–12705
Wu P et al (2023) PV-RCNN++: semantical point-voxel feature interaction for 3D object detection. Vis Compute 39:2425–2440
Xia Y, Gladkova M, Wang R, Li Q, Stilla U, Henriques JF, Cremers D (2022) CASSPR: cross attention single scan place recognition. In: 2023 IEEE/CVF international conference on computer vision (ICCV), pp 8427–8438
Xia Y, Shi L, Ding Z, Henriques JF, Cremers D (2024) Text2Loc: 3D point cloud localization from natural language. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 14958–14967
Song Y, Li Z, Wu J, Song C, Xu Z (2023) Leveraging front and side cues for occlusion handling in monocular 3D object detection. Vis Comput 40:1757
Cheng T et al (2022) Based on real and virtual datasets adaptive joint training in multi-modal networks with applications in monocular 3D target detection. Vis Comput 39:6367
Ji C, Liu G, Zhao D (2022) Stereo 3D object detection via instance depth prior guidance and adaptive spatial feature aggregation. Vis Comput 39:4543
Li Z et al (2022) BEVFormer: learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. Comput Vis ECCV 2022:1–18
Wang Y et al (2022) DETR3D: 3D object detection from multi-view images via 3D-to-2D queries. In: Proceedings of the 5th conference on robot learning, pp 180–191
Song S, Huang T, Zhu Q, Hu H (2023) ODSPC: deep learning-based 3D object detection using semantic point cloud. Vis Comput 40:849
Ai L, Xie Z, Yao R, Yang M (2023) MVTr: multi- feature voxel transformer for 3D object detection. Vis Comput 40:1453
Pang S, Morris D, Radha H (2020) CLOCs: camera- LiDAR object candidates fusion for 3d object detection. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 10386–10393
Luo H, Hanagud S (1997) Dynamic learning rate neural network training and composite structural damage detection. AIAA J 35:1522–1527
Yang J, Bisk Y, Gao J (2021) TACo: token-aware cascade contrastive learning for video-text alignment. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 11562–11572
Xia Y, Xu Y, Li S et al (2021) SOE-Net: a self-attention and orientation encoding network for point cloud based place recognition. In: Proceedings—2021 IEEE/CVF conference on computer vision and pattern recognition, CVPR 2021. IEEE Computer Society, pp 11343–11352
Yu F, Wang D, Shelhamer E, Darrell T (2018) Deep layer aggregation, pp 2403–2412
Duan K et al (2019) CenterNet: keypoint triplets for object detection. pp 6569–6578
Liu Z, Wu Z, Toth R (2020) SMOKE: single-stage monocular 3D object detection via keypoint estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pp 996–997
Guo C et al (2010) SecondNet: a data center network virtualization architecture with bandwidth guarantees. In: Proceedings of the 6th international conference, pp 1–12
Lin T-Y, Goyal P, Girshick R, He K, Dollar P (2017) Focal loss for dense object detection, pp 2980–2988
Girshick R (2015) Fast R-CNN, pp 1440–1448
Geiger A, Lenz P, Stiller C, Urtasun R (2013) Vision meets robotics: The KITTI dataset. Int J Robot Res 32:1231–1237
Chen X et al (2015) 3D Object proposals for accurate object class detection. In:Advances in neural information processing systems, p 28
Zarzar J, Giancola S, Ghanem B (2019) PointRGCN: Graph convolution networks for 3D vehicles detection refinement. arXiv:abs/1911.12236
Du X, Ang MH, Karaman S, Rus D (2018) A general pipeline for 3D detection of vehicles. In: 2018 IEEE international conference on robotics and automation (ICRA), pp 3194–3200
Barrera A, Guindel C, Beltrán J, García F (2020) BirdNet+: End-to-End 3D object detection in LiDAR Bird’s eye view. In: 2020 IEEE 23rd international conference on intelligent transportation systems (ITSC), pp 1–6
Desheng X, Youchun X, Feng L, Shiju P (2022) Real-time detection of 3d objects based on multi-sensor information fusion. Automot Eng 44(3):340
Chen X, Ma H, Wan J, Li B, Xia T (2017) Multi-view 3D object detection network for autonomous driving. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1907–1915
Chen J et al (2022) Disparity-based multiscale fusion network for transportation detection. IEEE Trans Intell Transp Syst 23:18855–18863
Brekke Å, Vatsendvik F, Lindseth F (2019) Multimodal 3D object detection from simulated pretraining. In: Nordic artificial intelligence research and development, pp 102–113
Wang K, Zhou T, Zhang Z, Chen T, Chen J (2023) PVF-DectNet: multi-modal 3D detection network based on perspective-voxel fusion. Eng Appl Artif Intell 120:105951
Ku J, Mozifian M, Lee J, Harakeh A, Waslander SL (2018) Joint 3D proposal generation and object detection from view aggregation. In: 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), Madrid, Spain, pp 1–8. https://doi.org/10.1109/IROS.2018.8594049
Meng Q, Wang W, Zhou T, Shen J, Van Gool L, Dai D (2020) Weakly supervised 3D object detection from lidar point cloud. In: Part XIII (ed) Computer vision—ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, proceedings. Springer, Heidelberg, pp 515–531
Acknowledgements
This work was supported by "The Anhui Province Science and Technology Innovation Tackle Plan Project (202423r06050003), 173 Basic Strengthening Program (2024-JCJQ-JJ-0363, The Anhui Provincial Key Research and Development Project, (JZ2024AKKG0003), State Key Laboratory of Intelligent Vehicle Safety Technology (IVSTSKL-202409)".
Funding
The authors certify that there is no conflict of interest with any individual/organization for the present work.
Author information
Authors and Affiliations
Contributions
Zhang Qiang and Cheng Teng drafted the main manuscript text, while Shi Qin, Chen Jiong, and Zhang Junning prepared the figures and tables. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, Q., Shi, Q., Cheng, T. et al. VPC-VoxelNet: multi-modal fusion 3D object detection networks based on virtual point clouds. Int J Multimed Info Retr 14, 10 (2025). https://doi.org/10.1007/s13735-025-00360-0
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13735-025-00360-0