
Abstract
For a class of linear variational inequalities resulting, e.g., from Signorini contact problems, a simple variable transformation (or synonymously a basis transformation) can be used to convert the linear inequality constraints into simple box constraints. This enables the use of efficient, stable and simple to implement iterative solvers. This manuscript shows how this variable transformation can be implicitly incorporated within an accelerated projected SOR scheme (APSOR) as well as the primal-dual active set method. In particular, some possible acceleration steps are proposed and the global convergence of the APSOR scheme is proven. Moreover, some implementational aspects are discussed and it is demonstrated that the accelerated projected symmetric SOR scheme is competitive to the locally quadratic converging primal-dual active set method.
Similar content being viewed by others

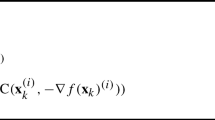
Avoid common mistakes on your manuscript.
1 Introduction
In this paper we consider variational inequalities of the following type: Find \(x \in K\) such that
for all \(y \in K\) with \(A\in {\mathbb {R}}^{n\times n}\), \(L\in {\mathbb {R}}^n\), \(B \in {\mathbb {R}}^{m\times n}\), \(g \in {\mathbb {R}}^m\) and \(K:=\left\{ y\in {\mathbb {R}}^n \mid By\le g\right\} \), where A is assumed to be positive definite (but not necessarily symmetric). The inequality sign \(\le \) has to be understood componentwisely. Variational inequalities of this type appear in many problems of mathematical programming. For instance, they result from the discretization of contact problems and have a vast amount of related applications (Glowinski 1984; Glowinski et al. 1981; Kikuchi and Oden 1988). In many cases, the matrix A is symmetric, for instance, when A results from the discretization of a (linear elastic) contact problem with standard finite elements or boundary elements. However, the application of more advanced discretization methods, such as interior penalty discontinuous Galerkin methods, may lead to a non-symmetric A (Banz and Stephan 2014a, b).
Provided that K is non-empty, it is well known that the variational inequality (1) has a unique solution. However, the computation of this solution is by no means trivial. For particular problems there exist highly optimized well advanced solvers like monotone multigrid solvers (Kornhuber 1997). But, for more general problems or if the implementational effort should be kept small, one may resort to more basic projection-contraction methods such as presented in He (1997); Bnouhachem (2006) or to CG-based methods with proportioning and projection (Dostál 1997; Dostál and Schöberl 2005). The convergence of these methods is often guaranteed, however their applicability depend on an efficient projection back onto the set K (which is available for box constraints). And even then, the number of iterations often depends on user-chosen and problem-dependent parameters. Moreover, the realization of projections for non-box constraints is often as complicated as solving (1) itself.
We note if A is symmetric, the variational inequality problem (1) is equivalent to the strictly convex, quadratic minimization problem: Find \(x \in K\) such that
with \(E(y):=\frac{1}{2} y^\top Ay-y^\top L\). For such a problem a huge number of algorithms are described in literature, e.g., Geiger and Kanzow (2002), Gill et al. (1981), Jarre and Stoer (2013), Nocedal and Wright (1999). Many of these utilize the first order optimality or KKT conditions
where \(\lambda \in {\mathbb {R}}^m\) serves as a Lagrange multiplier associated to the inequality constraints. An efficient algorithm which is based on the solution of the KKT-System (3) is the primal-dual active set algorithm (Kunisch and Rendl 2003; Curtis et al. 2014). In many implementations of such optimization schemes, the general constraints \(By \le g\) and simple box constraints \(y \le g\) are distinguished for the sake of computational efficiency. This is even more important for projection-contraction methods as the projection onto a convex set with box constraints can be computed efficiently just by taking a simple maximum or minimum, whereas in general the projection itself is a non-trivial minimization problem. Moreover, the primal-dual active set method (Kunisch and Rendl 2003) may converge for box constraints but not necessarily for general inequality constraints (Curtis et al. 2014).
In this paper, we consider a special matrix class for the constraints matrix B, which is characterized by the property that each column of B has at most one non-zero entry. Such linear constraints are of special interest, for instance, in the discretization of contact problems and, in particular, in Signorini contact problems of linear elasticity (cf. e.g. Hlávaček et al. 1988; Kikuchi and Oden 1988) in which each row of the matrix B contains a vector which is the outer normal vector of a certain boundary point. Based on this matrix class, we introduce a variable transformation which enables the transformation of the constraints \(Bx\le g\) to box constraints so that efficient and easy to implement solution schemes can be applied. For its definition we exploit some ideas from a transformation approach originally proposed by Hlavacek et al. in Hlávaček et al. (1988). The variable transformation and its inverse are easily and efficiently computable and, equally important, fit well into iterative solvers which exploit the possibly sparse structure of the matrix A. Similar variable transformation techniques for transforming linear inequality contraints into box contraints are introduced in literature. We refer to Krause (2001), Dickopf and Krause (2009), Kothari and Krause (2022), where variable transformations enable the use of projected Gauss Seidel schemes as smoother within monotone multigrid methods.
The paper is structured as follows: In Sect. 2 the matrix class for B as well as the variable transformation are introduced and analyzed. In Sect. 3, we discuss an efficient realization of the variable transformation within the projected successive overrelaxation procedure (PSOR), which is well-known in the context of obstacle problems (see, e.g. (Hlávaček et al. 1988, p. 20), (Glowinski et al. 1981, p. 67), (Glowinski 1984, p. 40) and (Hlávaček et al. 1988, p. 20)) and of simplified Signorini problems (see, e.g. (Kikuchi and Oden 1988, p. 128)). In particular, the variable transformation appears only implicitly and all variables are stated with respect to their original basis. Moreover, we discuss an acceleration approach based on the solution of low dimensional subproblems yielding the accelerated PSOR procedure (APSOR) as similarly introduced in Blum et al. (2004); Schröder and Blum (2008). In Sect. 4 a different more explicit realization of the variable transformation as a matrix-matrix-matrix–vector multiplication is presented exemplarily for the primal-dual active set method as proposed in Kunisch and Rendl (2003). Various numerical studies are presented in Sect. 5, which analyze the acceleration techniques for PSOR schemes and the effect of the variable transformation on both the number of iterations as well as the CPU-time. Detailed proofs, in particular of the global convergence of the accelerated PSOR scheme with implicit variable transformation, are placed in the appendix.
2 Transformation to box constraints
In this section, we introduce the following matrix class for the matrix B: Denoting the index set of non-zero row entries by
for each row of B with index \(1 \le i \le m\), we assume the condition for B that
for all \(1\le i,k\le m\) with \(i \ne k\). This condition implies that in each column of B there exists at most one non-zero entry, which further implies \(m \le n\) if B contains no zero rows. Note that (5) implies separable linear constraints in the sense of separable convex constraints as, for instance, described in Dostál et al. (2023).
Based on this matrix class we introduce a variable transformation which converts the linear constraints \(By \le g\) to box constraints. For this purpose, we define the quantity \(\gamma =(\gamma _1,\ldots ,\gamma _n)\) as
for the column index \(j\in \{1,\ldots ,n\}\). Note that this quantity is indeed well-defined and indicates the unique row index of the non-zero entry of the j-th column of B. We further define the pivot index \(\rho (i)\in \alpha _i\) for the row index \(1\le i \le m\) of B by
Without loss of generality we assume \(B_{i,\rho (i)}\ne 0\), as rows with only zero entries can be eliminated if the corresponding entry in g is non-negative. Note, if this entry were negative, the convex set K would be empty. Further note that this assumption on B means
and that \(\gamma _{\rho (i)}=i\). With these quantities at hand we specify the vectors \(\sigma ,\kappa \in {{\mathbb {R}}}^n\) by
for \(1\le i\le n\). Eventually, we define the matrix \(M^{(\xi )}\in {{\mathbb {R}}}^{n\times n}\) for a vector \(\xi \in {{\mathbb {R}}}^n\) by
for \(1\le i,j \le n\). The following lemma states that for \(y\in {\mathbb {R}}^n\)
defines as a variable transformation (i.e. \(I+M^{(\sigma )}\) is regular) and that the back- and forward-transformation can be computed explicitly as the following Lemma shows. In this paper, we call (7) box constraints transformation or bc-transformation for short.
Lemma 1
The matrices \(I+M^{(\sigma )}\) and \(I+M^{(\kappa )} \) are regular. Moreover, it holds
Proof
Let \(k,i\in \{1,\ldots ,n\}\). First, we note that
with
If the first condition in (8) holds, we have \(k=\rho (\gamma _{\rho (\gamma _i)})=\rho (\gamma _i)=r\) and \(\gamma _r = \gamma _{\rho (\gamma _i)} = \gamma _i\). Thus, this condition reduces to \(\gamma _i\ge 1\) and \(k=\rho (\gamma _i)\). Moreover, it holds
Hence,
and, thus,
It remains to be showed that \(\kappa _i+B_{\gamma _i,\rho (\gamma _i)}\sigma _i=0\) for \(\gamma _i\ge 1\) with \(k=\rho (\gamma _i)\). Assume \(i = \rho (\gamma _i)\) then
For the case \(i \ne \rho (\gamma _i)\) we obtain
which completes the proof. \(\square \)
To get a better understanding of the bc-transformation we look at the following illustrative example: Let the matrix \(B\in {\mathbb {R}}^{3\times 8}\) be given as
which obviously fulfills condition (5). We get
and
This gives the back- and forward-transformation matrices
The bc-transformation (7) is well adapted to the constraining matrix B as the matrix
becomes a (generalized) permutation matrix.
Lemma 2
Let \(\hat{y}\in {\mathbb {R}}^n\). Then,
for \(1\le j\le m\).
Proof
For \(\tilde{y}:=M^{(\sigma )} \hat{y}\) we conclude from the definition of \(M^{(\sigma )}\)
for \(1\le i\le n\) and, therewith,
\(\square \)
We can now prove that (1) is equivalent to the variational inequality: Find \(\hat{x} \in \hat{K}\) such that
for all \(\hat{y} \in \hat{K}:= \{ \hat{y} \in {\mathbb {R}}^n \mid \hat{y} \le \hat{g} \}\), where
and \(\hat{g}\in ({\mathbb {R}}\cup \{\infty \})^n\) with
Clearly, introducing \(\hat{g} \in {\mathbb {R}}^n\) may increase the number of constraints, but a constraint with \(\hat{g}_i = \infty \) is always inactive. In particular, we have \(\hat{x}\in \hat{K}\) if and only if
for all \(1\le i\le n\) with \(\gamma _i\ge 1\). We further note that \(\hat{A}\) is positive definite if this is true for the matrix A and that the matrix \(\hat{A}\) is symmetric if and only if A is symmetric. In the symmetric case, A and \(\hat{A}\) have the same number of positive, negative and zero eigenvalues, resulting from Sylvester’s law of inertia.
Theorem 3
If \(x\in K\), then \(\hat{x}:= (I+M^{(\kappa )})x\in \hat{K}\). Furthermore, if x solves (1), then \(\hat{x}\) solves (10). Reversely, if \(\hat{x}\in \hat{K}\), then \(x:=(I+M^{(\sigma )})\hat{x}\in K\). Moreover, if \(\hat{x}\) solves (10), then x solves (1).
Proof
Let \(1\le i\le n\) with \(\gamma _i\ge 1\) and let \(x\in K\) solve (1). Using Lemma 2 we have \(\hat{x}_{\rho (\gamma _i)}=(P\hat{x})_{\gamma _i}=(Bx)_{\gamma _i}\le g_{\gamma _i}\), which is \(\hat{x}\in \hat{K}\) due to (11). Using again Lemma 2 we conclude for \(\hat{y}\in \hat{K}\) and \(y:=(I+M^{(\sigma )})\hat{y}\) that \((By)_{\gamma _i}=(P\hat{y})_{\gamma _i}={\hat{y}}_{\rho (\gamma _i)}\le g_{\gamma _i}\). Thus, (6) gives \(y\in K\) and we verify
which shows that \(\hat{x}\) solves (10). Now, let \(\hat{x}\in \hat{K}\) solve (10), then Lemma 2 and (11) yield \((Bx)_{\gamma _i}=(P\hat{x})_{\gamma _i}=\hat{x}_{\rho (\gamma _i)}\le g_{\gamma _i}\), which gives \(x\in K\) due to (6). Applying Lemma 2 we conclude for \(y\in K\) and \(\hat{y}:=(I+M^{(\kappa )})y\) that \(\hat{y}_{\rho (\gamma _i)}=(P\hat{y})_{\gamma _i}=(By)_{\gamma _i}\le g_{\gamma _i}\). Thus, (11) gives \(\hat{y}\in \hat{K}\) and
which shows that x solves (10). \(\square \)
From the relation between x and \(\hat{x}\) as stated in Theorem 3 we easily obtain the following result for the minimization problem: Find \(\hat{x} \in \hat{K}\) such that
with \(\hat{E}(\hat{y}):=\frac{1}{2} \hat{y}^\top \hat{A}\hat{y}-\hat{y}^\top \hat{L}\).
Corollary 4
It holds that \(x\in K\) solves (2), if and only if \(\hat{x} = (I+M^{(\sigma )})^{-1} x\in \hat{K}\) solves (12). Moreover, it holds \(\hat{E}(\hat{y})=E((I+M^{(\sigma )}) \hat{y})\) for all \(\hat{y}\in {\mathbb {R}}^n\).
Furthermore, we get the following result for the KKT-system: Find \((\hat{x},\hat{\lambda })\in {\mathbb {R}}^n\times {\mathbb {R}}^m\) such that
Corollary 5
It holds that \((x,\lambda )\in {\mathbb {R}}^n\times {\mathbb {R}}^m\) solves (3) if and only if \((\hat{x},\hat{\lambda }):=((I+M^{(\sigma )})^{-1}x, \lambda )\) solves (13).
Theorem 3 suggests solving (1) just by using an appropriate solution procedure for the transformed problem (10). However, keeping in mind that A and \(M^{(\sigma )}\) are (typically) sparse matrices, it is often not efficient to explicitly compute the matrix product \(\hat{A}=(I+M^{(\sigma )})^\top A (I+M^{(\sigma )})\) with respect to CPU-time and/or memory consumption. For instance, if \(B\in {\mathbb {R}}^{1\times n}\) with \(\alpha _1=\{1,\ldots ,n\}\), \(\hat{A}\) is dense, i.e. the sparsity pattern of B can lead to a significant increase of the number of non-zero entries of \(\hat{A}\). Therefore, the direct application of solution algorithms to (10) might not be appropriate. In the following two sections we demonstrate exemplarily how the bc-transformation (7) can be embedded into iterative solvers such as the (accelerated) projected successive overrelaxation (PSOR and APSOR) and the primal-dual active set algorithm. In the PSOR algorithms the bc-transformation appears only implicitly with all the iterates being stated in the original variable x. Whereas, in the active set algorithm the bc-transformation appears more explicitly as a matrix-matrix-matrix–vector multiplication with all the iterates being stated in the transformed variable \(\hat{x}\).
3 Projective successive overrelaxation with the bc-transformation
In this section, we present the projective successive overrelaxation procedures PSOR and APSOR which include the bc-transformation (7). The APSOR procedure contains an additional acceleration step, in which a low dimensional minimization problem is solved after each complete PSOR step. Both procedures need one additional auxiliary vector \(z\in {\mathbb R}^m\), which enables access to the transformed variables without calculating them explicitly. For the computation of z we use the mapping \(\mathcal{M}^{(\xi )}:{\mathbb {R}}^n\rightarrow {\mathbb {R}}^m\) given by
for some \(\xi \in {\mathbb {R}}^n\). We denote the i-th row vector of A by \(A_{i,:}\) and define \(\epsilon \in {\mathbb {R}}^n\) by
for \(1\le i\le n\) and with the relaxation parameter \(\omega \in (0,2)\). Furthermore, we define
and
with some \(D\in {\mathbb {R}}^{n\times r}\).

PSOR and APSOR with bc-transformation
In Algorithm 1 the PSOR procedure and the APSOR procedure with the bc-transformation are simultaneously described. In particular, omitting the acceleration step gives the PSOR procedure. For the APSOR procedure we assume that A is symmetric to ensure that the minimization problem in the acceleration step has a unique solution. The column vectors \(D_{:,i}\) of D in the acceleration step can be interpreted as search directions. Their choice is, in principle arbitrary. Choosing \(D_{:,i}\) as the differences of the last r iterations might be a practical selection since active components cancel out to zero in \(D_{:,i}\) such that these components are not changed by the acceleration step. We refer to Blum et al. (2004), Schröder and Blum (2008) where the differences of iterations also are used in a similar acceleration approach for the projective SOR procedure. Note that choosing \(r \ge 2\) linearly independent search directions may make the solution of the minimization problem in the acceleration step relatively challenging.
In order to formally describe a sequence of iterates computed by Algorithm 1 let the mappings \(S^*_i:{\mathbb {R}}^n\times {\mathbb {R}}^m\rightarrow {\mathbb {R}}^n\) and \(T^*_i:{\mathbb {R}}^n\times {\mathbb {R}}^m\rightarrow {\mathbb {R}}^m\) be defined such that \(S^*_i(x,z)\) returns the updated x and \(T^*_i(x,z)\) returns the updated z of the i-th PSOR substep. Define
for \(i\in \{1,\ldots ,n\}\) and for \(D\in {\mathbb {R}}^{n\times r}\) set
with \(H_D:{\mathbb {R}}^n\times {\mathbb {R}}^m\rightarrow {\mathbb {R}}^n\) and \(G_D:{\mathbb {R}}^n\times {\mathbb {R}}^m\rightarrow {\mathbb {R}}^m\) defined as \(H_D(x,z):=x\) and \(G_D(x,z):=z\), respectively, if the acceleration step in Algorithm 1 is omitted (PSOR). If Algorithm 1 includes the acceleration step (APSOR), \(H_D(x,z)\) returns the modified x and \(G_D(x,z)\) the modified z as computed in the acceleration step, i.e.
and
Therewith, Algorithm 1 generates the sequence \(\{x^{l},z^{l}\}_{l\in {\mathbb {N}}}\) with \(x^0\in {\mathbb {R}}^n\), \(z^0:=-\mathcal{M}^{(\kappa )} (x^0)\) and
where \(D^l\in {\mathbb {R}}^{n\times r}\) denotes the matrix as chosen in the l-th acceleration step of the APSOR procedure. In the PSOR case we simply set \(D^l:=0\).
The acceleration step in the APSOR procedure aims to further reduce the iteration error \(\Vert x - x^l\Vert \) of the iterate \(x^l\) by solving a low dimensional minimization problem. This may be motivated by the observation that (as A is symmetric) the difference in E is an upper bound for the error induced by A, i.e.
with \(\Vert x\Vert _A^2:=x^\top Ax\) (which directly results from (1)).
We note that it may not be necessary to solve the minimization problem in the acceleration step exactly. It could be sufficient to find an \(\tilde{\alpha } \in \Theta _D(x)\) such that \(E(x+D\tilde{\alpha })\le E(x)\), i.e. a new feasible point which does not increase the energy value. Hence, we may simply solve the unconstrained minimization problem to obtain a descend direction with respect to the energy value and afterwards perform some simple line search backtracking to guarantee feasibility. The numerical results suggest that this proceeding leads to less active constraints for the new iterate giving more flexibility to the next PSOR step. The acceleration step can be formulated in the following way: Let \(\mu \in (0,1)\) and \(q\in {\mathbb {N}}_0\) and define
and
for \(D\in {\mathbb {R}}^{n\times r}\).

If Algorithm 1 is performed with this line search acceleration step (LSAPSOR), let \(H_D(x,z)\) return the modified x and \(G_D(x,z)\) the modified z as computed in this acceleration step, i.e.
We note that \(G_D\) still fulfills (15). With this extended definition of the mappings \(H_D\) and \(G_D\) the sequence \(\{x^l,z^l\}_{l\in {\mathbb {N}}}\), as defined in (16), also includes the LSAPSOR scheme. Indeed, due to the convexity of E we have
We further note that
if \(r=1\) and
with \(d_0:= D_{:,1}^\top (L - Ax)\), \(d_1:=D_{:,1}^\top A D_{:,2}\) and \(d_2:=D_{:,1}^\top A D_{:,1}\) if \(r=2\).
Theorem 6
Let A be symmetric and positive definite and let \(x\in K\) be the solution of (1). Furthermore, let \(\{x^l\}_{l\in {\mathbb {N}}}\) be generated by the PSOR, the APSOR or the LSAPSOR scheme as defined in (16). Then, the sequence \(\{E(x^l)\}_{l\in {\mathbb {N}}}\) is monotonic decreasing and
Proof
The proof can be found in the appendix. \(\square \)
Remark 1
The PSOR procedure is closely related to the projective symmetric successive overrelaxation (PSSOR). For this procedure an additional backward PSOR step in Algorithm 1 has to be performed. Its analysis mainly requires some (notational) modifications in the proof of Theorem 6 as well as in the proofs of Lemmas 10, 11 and 13 as presented in the appendix. In particular, Theorem 6 remains valid for the PSSOR procedure and its accelerated variants APSSOR and LSAPSSOR.
Remark 2
The application of the bc-transformation to include the constraints given by condition (5) may not be restricted to the PSOR scheme and its accelerated variants. This iterative scheme can be seen as an example, where an implicit realization of the bc-transformation is beneficial. Other types of methods (such as CG-based methods introduced, e.g., in Dostál 1997; Dostál and Schöberl 2005; Nocedal and Wright 1999) developed for solving (1) with box constraints may benefit from an implicit realization of the bc-transformation as well. The use of the PSOR scheme (or its accelerated variants (LS)(A)P(S)SOR) as smoother in monotone multigrid methods (see, e.g., Kornhuber 1997; Krause 2001; Dickopf and Krause 2009; Kothari and Krause 2022) in combination with the bc-transformation may also have potential in the context of solving large-scale contact problems.
4 Primal-dual active set solver with the bc-transformation

Matrix-vector-multiplication \(\hat{y} = \hat{A}_{{\mathcal {I}},{\mathcal {I}}} \hat{x}_{{\mathcal {I}}}\)

matrix-vector multiplication \(z=(I+M^{(\sigma )})x\)

matrix-vector multiplication \(z=(I+M^{(\sigma )})^\top x\).
A widely used method to solve the KKT-system (13) is the so-called active set method. In this algorithm an index set, the active set \({\mathcal {A}}\subset \{1,\ldots ,n\}\), is iteratively determined, which contains exactly those indices, for which the constraint (13b) is active. In each iteration step a corresponding equality constrained minimization problem is solved. If both the primal variable \(\hat{x}\in {\mathbb {R}}^n\) and the dual variable \(\hat{s}\in {\mathbb {R}}^n\) are used to update the active set \({\mathcal {A}}\) the algorithm is called primal-dual active set method (Kunisch and Rendl 2003). The basic procedure of the primal-dual active set algorithm for problems with box-constraint is stated in the following way: Given an active set \({\mathcal {A}}\) and its complement \({\mathcal {I}}:=\{1,\ldots ,n\}\backslash {\mathcal {A}}\), compute \(\hat{x}\) and \(\hat{s}\) such that
with \(\hat{s}_{\mathcal {I}}=0\), \(\hat{x}_{\mathcal {A}}=\hat{g}_{\mathcal {A}}\) and update \({\mathcal {A}}=\left\{ i\in \{1,\ldots n\} \mid \hat{x}_i>\hat{g}_i \text { or } \hat{s}_i>0 \right\} \). Here, the subvector \(\hat{x}_{{\mathcal {A}}}\in {\mathbb {R}}^{\ell }\) of \(\hat{x}\) with \(\ell :=\#{{\mathcal {A}}}\) is defined as
for \(1\le i\le \ell \) where \(({\mathcal {A}})\in \{1,\ldots ,n\}^{\ell }\) denotes the (ordered) tuple resulting from \({\mathcal {A}}\), i.e. \(({\mathcal {A}}):=(i_1,\ldots ,i_\ell )\) for \(i_1,\ldots ,i_\ell \in {\mathcal {A}}\) and \(i_1<\ldots <i_\ell \). The other subvectors and submatrices in (18) are analogously defined, for instance, the submatrix \(\hat{A}_{{\mathcal {A}},{\mathcal {I}}}\in {\mathbb {R}}^{\ell \times s}\) of \(\hat{A}\) with \(s:=\#{\mathcal {I}}\) is defined as
for \(1\le i\le \ell \) and \(1\le j\le s\).
If the hatted matrix \(\hat{A}\) is readily available, \(\hat{A}_{{\mathcal {I}},{\mathcal {I}}} \hat{x}_{\mathcal {I}}=\hat{L}_{\mathcal {I}} - \hat{A}_{{\mathcal {I}},{\mathcal {A}}}\hat{g}_{\mathcal {A}}\) may be solved efficiently, for instance, by a preconditioned CG method. In general, with only A and the matrix–vector multiplication \((I+M^{(\sigma )})x\) being available, we find that the matrix–vector multiplication \(\hat{A}_{{\mathcal {I}},{\mathcal {I}}} \hat{x}_{\mathcal {I}}\) needed for such iterative solvers can be efficiently computed by the Algorithms 2, 3 and 4, in which the pre-computed tuple \(({\mathcal {G}})\) of \({\mathcal {G}}:=\{j\in \{1,\ldots ,n\}\mid \gamma _j>0\}\) is used. Note that the order in the definition of \((\cdot )\) is only needed to ensure that this notation is well-defined, it is not needed for the computations in the algorithms.
Alternatively, we may use the projected CG method to solve the equality constrained minimization subproblem which would only require the use of Algorithms 3 and 4. We note that the dual variable \(\hat{s}\) is nothing but the residuum and is computed by the matrix–vector multiplications
From Lemma 2 and Corollary 5 we obtain \(P^\top \hat{\lambda } =P^\top \lambda =\hat{s}\) for the Lagrange multiplier. Thus, \(\hat{\lambda }\) and \(\lambda \) can be computed by \(\hat{\lambda }=\lambda = P P^\top \hat{\lambda } = P \hat{s}\) (in a post-processing step). A convergence analysis of the primal-dual active set method can be found, e.g. in Kunisch and Rendl (2003), Hintermüller et al. (2002).
5 Numerical results
In this section we discuss the effect of different methods for the acceleration of the P(S)SOR scheme applied to an obstacle problem (i.e. \(B=I\) and the bc-transformation is not needed). Furthermore, the application of the bc-transformation is studied in the context of a three dimensional Signorini contact problem. In the experiments all iterative solvers are initialized with a zero initial solution. A MATLAB implementation of the bc-transformation and some solvers can be found in the Online Resource 1.
5.1 Effect of the acceleration step and relaxation parameter \(\omega \) for an obstacle problem
In order to demonstrate the effect of the acceleration step within the PSOR and PSSOR, see Algorithm 1, and of the choice of the relaxation parameter \(\omega \in (0,2)\) in this algorithm, we consider the one dimensional obstacle problem:
The discretization of this problem with lowest order conforming finite elements on a uniform mesh yields the variational inequality (1) with \(B:=I \in {\mathbb {R}}^{n \times n}\),
where \(h:=2/(n+1)\) is the mesh size of the one-dimensional subdivision of \((-1,1)\) with \(n+2\) nodes. In particular, n coincides with the dimension or with the degrees of freedom (DOF) of the discrete problem. As the problem already has box constraints, the bc-transformation is not needed (indeed \(M^{(\sigma )}=0\)) and the problem can be solved without further adaptation with the PSOR or PSSOR algorithm.
Figure 1 shows the dependency of the number of the iterations resulting from the accelerated P(S)SOR schemes on the relaxation parameter \(\omega \). We choose \(n:=127\) and stop the iteration if \(\Vert x_{P(S)SOR} - x_{AS} \Vert _2 < 10 ^{-9}\) is reached, where the discrete solution \(x_{AS}\) is calculated by the primal-dual active set algorithm in combination with a direct solver. Furthermore, we use the difference of the current iterate to the last one or two iterations as search direction(s) \(D_{:,i}\) within the acceleration step, in which we therefore have to solve a one or two dimensional minimization problem. We consider two fundamentally different acceleration procedures with these search directions, see the discussion in Sect. 3. While solving the 1d constrained optimization problem is quite simple, solving the constrained problem becomes significantly more difficult if two search directions are used. We call these procedures C1d and C2d, respectively. By L1d and L2d we denote the acceleration method for which the unconstrained minimization problem is solved and afterwards an inexact line search between the current iterate and the previously computed unconstrained minimizer is performed to satisfy the constraint \(x \le g\), see LSAPSOR acceleration step. Starting with the full length \(\xi _D=1\) the scaling parameter \(\xi _D\) is halved in each back tracking step (i.e. \(\mu :=0.5\) in (17)). If we perform an exact back tracking, then C1d and L1d would be the same. This is not true for two or higher dimensional minimization problems in the acceleration step. Clearly, L2d essentially requires only two matrix–vector multiplications and is, therefore, much cheaper than C2d both in computational time and in implementational effort. But also the inexactness of the line search can have a positive effect on its own. Due to the halving of \(\xi _D\) we can expect that the new iterate has at least one active constraint less than the iterate resulting from an exact line search. Thus, the next P(S)SOR step has more flexibility in terms of feasible directions to reduce the energy value. In Schröder and Blum (2008) the unconstrained minimizer is projected back into the feasible set by minimizing the Euclidean distance. We call this acceleration variant P2d. While the projection is cheaper than the back tracking variant its convergence can not be guaranteed as the energy value might increase due to the projection. We observe in the numerical experiments that P2d does converge but the energy value is not monotone decreasing.
Not surprisingly, the number of iterations depends strongly on the choice of \(\omega \). In Fig. 1 we observe that the optimal \(\omega \) seems to be (almost) independent of the acceleration method. Moreover, Fig. 1a shows that the acceleration procedure within the PSOR has no significant effect on the number of iterations in the case of an optimal \(\omega \). However, if the acceleration is applied the number of iterations are much more robust to changes in \(\omega \), which eases the burden of selecting an appropriate \(\omega \) for practical computations. In the case of the PSSOR scheme the acceleration step always improves the number of iterations significantly, see Fig. 1b. What stands out is the large volatility of the number of iterations if one of the acceleration procedures is applied. This volatility may be a consequence of using the differences of the last iterates for the search directions \(D_{:,i}\).

Number of iterations (y-axis) for the one dimensional obstacle problem with \(n=127\) for different values of \(0<\omega <2\) (x-axis)
It is well known that the eigenvalues of A and, therewith, the optimal \(\omega \) depend on the dimension n. We set \(\omega :=2-12.75/n\) for the experiments documented in Tables 1, 2, 3 and 4. Doubling n one P(S)SOR step becomes roughly twice as expensive because each row of A contains at most three non-zero entries. However, the number of iterations also increase. In the case of all PSOR schemes and the non-accelerated PSSOR scheme they are roughly doubling as well. We do not always observe this effect for the accelerated PSSOR schemes (which are further discussed at the end of this section). The implementation is done in MATLAB and the computations have been carried out on a HP EliteBook 840 G5 laptop with a i7-8550U CPU @ 1.80GHz CPU. Tables 1 and 2 emphasize once more that for reasonable good choices of \(\omega \) there is no advantage in taking an acceleration step for the PSOR method. As the number of iterations is roughly the same we can easily read off the CPU time needed for the individual acceleration steps, which is mainly one or two matrix–vector multiplications, and the cost for the back tracking. The C2d case is exceptional as we use MATLAB’s own active set quadratic programming solver to solve the non-trivial constrained minimization subproblem. For the PSSOR method, where a single step is twice as expensive as a single PSOR step, the choice of the acceleration methods has a drastic effect, see Tables 3 and 4. In particular, the use of a two dimensional subproblem is by far superior to the one dimension case and, of course, the standard non-accelerated case. Due to the easier implementation and guaranteed convergence we favor the L2d case.
5.2 Effect of the bc-transformation on contact solvers
To analyze the effect of the bc-transformation (7) we consider a so-called Signorini contact problem (Kikuchi and Oden 1988). The reference configuration of the body \(\Omega \) being in contact with a rigid obstacle is a segment of a hollow sphere. More precisely,
with the spherical coordinates \(x(r,\varphi ,\theta ):=(r\cos \varphi \sin \theta , r\sin \varphi \cos \theta , r\cos \theta )\) and midpoint \(p:=(-1.625,0,0)\), see Figs. 2a and b. The boundary of \(\Omega \) is decomposed into the Dirichlet boundary part
the boundary part \(\Gamma _C\) which potentially comes in contact with the rigid obstacle, namely
and the Neumann boundary part \( \Gamma _N:= \partial \Omega {\setminus } (\Gamma _D\cup \Gamma _C)\). The surface of the rigid obstacle which gets in contact with \(\Omega \) is described by the gap function
For the given constant volume force \(f:=(0,0,-0.1)^\top \) we seek a function \(u \in [H^1(\Omega )]^3\) such that
As usual, n is the outward unit normal and \(\sigma _n\), \(u_n\), \(\sigma _t\), \(u_t\) are the normal, tangential components of \(\sigma (u)n\) and u, respectively. The equation (20b) with the stiffness tensor \({\mathcal {C}}\) describes Hooke’s law with Young’s modulus of elasticity \(E:=2\,\textrm{GPa}\) and Poisson’s ratio \(\nu :=0.42\) where \(\epsilon (u)=\frac{1}{2} \left( \nabla u + \nabla u^\top \right) \) is the linearized strain tensor. The material parameters are chosen for a less or non-stiff (e.g. rubber-like) material in order to have a (reasonable) large contact area. In general, the application of Hooke’s linear-elastic material law is only justified to a very limited extent for such materials or for large deformations as occurs here.
To approximately solve (20) we subdivide \(\Omega \) by a uniform mesh consisting of hexahedrons and use lowest order finite elements with vector-valued, continuous and piecewise trilinear functions vanishing on \(\Gamma _D\). This gives the variational inequality (1) with the usual stiffness matrix A and the load vector L, see (Kikuchi and Oden 1988). The non-penetration condition \(u_n \le g\) is enforced for the finite element solution only in the vertices of the mesh lying on \(\Gamma _C\). This gives the constraining matrix B in (1), which consists of the unit normal vectors showing outward with respect to \(\Gamma _C\) in these vertices. Note that B trivially satisfies the required condition (5). Further note that as \(\Omega \) is a segment of a hollow sphere all these normal vectors point in different directions. See Fig. 2c for a visualization of the finite element solution.

a, b Reference configuration of the body \(\Omega \), c finite element mesh and deformed body
In view of the results of the previous section we no longer consider the PSOR methods and the acceleration step with a simple projection, namely P2d. Figure 3 shows the dependency of the number of PSSOR iterations on the relaxation parameter \(\omega \). We apply the PSSOR method to the explicitly transformed problem, i.e. with the matrix \(\hat{A}\) and data \(\hat{L}\), \(\hat{g}\), and stop the iterations if \(\Vert x_{PSSOR} - x_{AS} \Vert _2 < 10 ^{-9}\) for some exact discrete solution \(x_{AS}\) (resulting from the active set method). The observations are similar to those for the one dimensional obstacle case of Sect. 5.1. In particular, a very strong reduction in the number of iterations is obtained by both L2d and C2d.

Number of PSSOR iterations (y-axis) for the Signorini contact problem for \(n=3672\) (1024 mesh elements) for different values of \(0<\omega <2\) (x-axis)
Tables 5, 6 and 7 report the number of iterations and the required time in seconds for differently accelerated PSSOR methods. We choose \(\omega := 1.12- 1.35/\root 3 \of {\text {DOF}}\) to account for changing eigenvalues of A and stop once the relative difference of two successive iterates is less then \(10^{-10}\) in the Euclidean norm. In theory the PSSOR method which acts on the explicitly transformed problem should yield exactly the same iteration sequence as the PSSOR method with implicit bc-transformation (iPSSOR). However, due to unavoidable rounding errors the sequences of iterates (and therewith the number of iterations) may differ. In the case that no acceleration is applied this effect may be neglectable. But, as discussed above, the strong dependency of the minimization subproblem on the preceding sequence of iterates and the strong effect of the acceleration step itself make the sequences of accelerated PSSOR iterates with explicit or implicit bc-transformation differ. Indeed, the effect of differing iterates can be observed in the tables and is particularly distinct for the accelerated variants. As the implementation of the C1d and C2d method within the iPSSOR is rather challenging and not very promising we have not considered these variants in the experiments.
Table 8 compares the (i)PSSOR method with L2d with the primal-dual active set method, which can be seen as a commonly used reference method to solve variational inequalities as given in (1). In the case of those variants relying on the explicit bc-transformation the CPU time for this transformation, i.e. computation of \(\hat{A}\), \(\hat{L}\) and \(\hat{g}\) needs to be added to the solution time. The (reduced) system of linear equations within each active set iteration is either solved with MATLAB’s extremely fast direct solver (AS-D), MATLAB’s diagonal preconditioned CG-method (AS-CG) or with a diagonal preconditioned projected CG method (AS-Proj) as introduced in (Nocedal and Wright 1999, Alg. 16.2). Even when adding the transformation time to the solution time the methods acting on the explicit transformed problem are still slightly faster than solvers with the bc-transformation carried out on the fly. Interestingly, the sparsity pattern of A and \(\hat{A}\) is almost identical and \(\hat{A}\) has only a handful of non-zero entries more than A. This and the fact that the transformation only effects those matrix entries which are somehow associated with the contact boundary part may also explain the observation that the computed condition number of \(\hat{A}\) is nearly identical to that of A, see Table 9. We note that the material parameters influence the condition number which may be significantly larger in practical applications than shown in this table. It is well-known that the condition number of the stiffness matrix strongly influence the number of the iterations of the PSOR scheme. This also appears to apply to the accelerated variants.
We expressly note that the (i)PSSOR method with an L2d acceleration step is of similar speed as the active set method. This leads us to the conclusion that the bc-transformation in conjunction with the simple to implement PSSOR scheme is very practical and, in particular, good enough to solve variational inequalities of the form (1) with B satisfying (5). Moreover, it has advantages in terms of memory requirements (as it exploits the sparsity structures of A and B), does not need an additional (direct) solver (in contrast to AS-D) and can serve as a benchmark solver to test more advanced methods that are optimized to specific problems.
Data Availability
The data for this article are available in the supplementary materials or on request from the authors.
References
Banz L, Stephan EP (2014) A posteriori error estimates of \(hp\)-adaptive IPDG-FEM for elliptic obstacle problems. Appl Numer Math 76:76–92
Banz L, Stephan EP (2014) hp-adaptive IPDG/TDG-FEM for parabolic obstacle problems. Comput Math Appl 67:712–731
Blum H, Braess D, Suttmeier FT (2004) A cascadic multigrid algorithm for variational inequalities. Comput Vis Sci 7(3–4):153–157
Bnouhachem A (2006) A new projection and contraction method for linear variational inequalities. J Math Anal Appl 314(2):513–525
Curtis FE, Han Z, Robinson DP (2014) A globally convergent primal-dual active-set framework for large-scale convex quadratic optimization. Comput Optim Appl 60(2):311–341
Dickopf T, Krause R (2009) Efficient simulation of multi-body contact problems on complex geometries: a flexible decomposition approach using constrained minimization. Internat J Numer Methods Eng 77(13):1834–1862
Dostál Z (1997) Box constrained quadratic programming with proportioning and projections. SIAM J Optim 7(3):871–887
Dostál Z, Schöberl J (2005) Minimizing quadratic functions subject to bound constraints with the rate of convergence and finite termination. Comput Optim Appl 30(1):23–43
Dostál Z, Kozubek T, Sadowská M, Vondrák V (2023) Scalable Algorithms for Contact Problems, 2nd edn. Advances in Mechanics and Mathematics, vol. 36, p. 443. Springer, New York
Geiger C, Kanzow C (2002) Theorie und Numerik Restringierter Optimierungsaufgaben. Springer, Berlin, Heidelberg
Gill PE, Murray W, Wright MH (1981) Practical optimization. Academic Press, Cambridge, Massachusetts
Glowinski R (1984) Numerical methods for nonlinear variational problems. Springer Series in Computational Physics. Springer, New York
Glowinski R, Lions JL, Trémolierès R (1981) Numerical analysis of variational inequalities. Studies in Mathematics and its Applications. North-Holland Publishing Company, Amsterdam
He B (1997) A class of projection and contraction methods for monotone variational inequalities. Appl Math Optim 35(1):69–76
Hintermüller M, Ito K, Kunisch K (2002) The primal-dual active set strategy as a semismooth newton method. SIAM J Optim 13(3):865–888
Hlávaček I, Haslinger J, Nečas J, Lovíšek J (1988) Solution of variational inequalities in mechanics. Applied Mathematical Sciences. Springer, New York
Jarre F, Stoer J (2013) Optimierung. Springer, Berlin, Heidelberg
Kikuchi N, Oden JT (1988) Contact problems in elasticity: a study of variational inequalities and finite element methods. SIAM Studies in Applied Mathematics. SIAM, Philadelphia
Kornhuber R (1997) Adaptive monotone multigrid methods for nonlinear variational problems. Vieweg+Teubner Verlag, Wiesbaden
Kothari H, Krause R (2022) A generalized multigrid method for solving contact problems in Lagrange multiplier based unfitted finite element method. Comput Methods Appl Mech Eng 392:114629–114630
Krause RH (2001) Monotone multigrid methods for signorini’s problem with friction. Dissertation, FU Berlin
Kunisch K, Rendl F (2003) An infeasible active set method for quadratic problems with simple bounds. SIAM J Optim 14:35–52
Nocedal J, Wright SJ (1999) Numerical optimization, 2nd edn. Springer, New York
Schröder A, Blum H (2008) Projective SOR-procedures for Signorini problems. Numerical analysis and applied mathematics. International conference on numerical analysis and applied mathematics 2008, American Institute of Physics (AIP). AIP Conference Proceedings 1048, 474–477
Funding
Open access funding provided by Paris Lodron University of Salzburg.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix A: Proof of Theorem 6
Appendix A: Proof of Theorem 6
Crucial for the convergence proof is the observation that the PSOR procedure and its accelerated variants APSOR and LSAPSOR with bc-transformation are equivalent to those applied to the transformed problem (10). For this purpose we need access to the diagonal entries of the system matrix \(\hat{A}\) and define
where \(\epsilon \) is defined as in (14).
Lemma 7
There holds
for all \(1\le i \le n\) and all \(\omega \in (0,2)\).
Proof
We distinguish between three cases. If \(\gamma _i=0\), then \(\hat{A}_{ii}=A_{ii}\). If \(\gamma _i\ge 1\) and \(i\ne \rho (\gamma _i)\), we have
Finally, if \(\gamma _i\ge 1\) and \(i=\rho (\gamma _i)\), we obtain
Therefore, in all three cases we obtain \(\omega \hat{A}_{ii}^{-1}=\hat{\delta }_i\). \(\square \)
To formally describe the PSOR procedures applied to (10) let \(\hat{S}_i:{\mathbb {R}}^n\rightarrow {\mathbb {R}}^n\) be defined as
for \(i\in \{1,\ldots ,n\}\), where the i-th row vector of \(\hat{A}\) is denoted by \(\hat{A}_{i,:}\). Furthermore, let \(\hat{P}_i:{\mathbb {R}}\rightarrow \mathbb {R}\) be the one dimensional projection with
and set
for \(i\in \{1,\ldots ,n\}\). Note that
and
Eventually, define for \(\hat{D}\in {\mathbb {R}}^{n\times r}\)
where \(\hat{H}_{\hat{D}}(\hat{x}):=\hat{x}\) in the case of the PSOR method and
with
and
if the APSOR method is applied. Note that if \(\hat{x}\in \hat{K}\), we have \(0\in {\hat{\Theta }}_{\hat{D}}(\hat{x})\) and, thus,
Moreover, it holds
for all \(y\in \{\hat{x}+\hat{D}\hat{\beta }\mid \hat{\beta }\in \hat{\Theta }_{\hat{D}}(\hat{x})\}\). This gives
If the LSAPSOR method is applied we set
with
and
Defining \(\varphi (t):=\hat{E}(\hat{x}+t \hat{D}\hat{\gamma }_{D}(\hat{x}))\) we get for \(t\in [0,1]\)
which shows that \(\varphi \) is monotonic decreasing in [0, 1] and, thus,
for all \(t\in \hat{I}_D(\hat{x}):=[0,\hat{\xi }_D(\hat{x},\hat{\gamma }_D(\hat{x}))]\). Hence, (23) is still true. Moreover, we have (24) for all \(\hat{y}\in \{\hat{x}+t\hat{D}\hat{\gamma }_D(\hat{x})\mid t\in \hat{I}_D(\hat{x})\}\). This gives that (25) is also valid for this case.
The iterates \(\{\hat{x}^l\}_{l\in {\mathbb {N}}}\) of the PSOR and its accelerated variants are given by \(\hat{x}^0:=(I+M^{(\kappa )})x^0\) and
with \(\hat{D}^l:=(I+M^{(\kappa )})D^l\) in the APSOR and the LSAPSOR case and \(\hat{D}^l:=0\) in the PSOR case.
Lemma 8
There holds
for all \(x\in {\mathbb {R}}^n\).
Proof
We have
The second assertion follows from
with \(1\le i\le m\). \(\square \)
The connection of the mappings \(S^*_i\) and \(T^*_i\) (as introduced in Sect. 3) with the bc-transformation is given by the following assertion.
Lemma 9
There holds
for all \( 1\le i \le n\) and \(x\in {\mathbb {R}}^n\).
Proof
Let \(\hat{x}:=(I+M^{(\kappa )})x\) and \(z:=-\mathcal{M}^{(\kappa )}(x)=\mathcal{M}^{(\sigma )}(\hat{x})\). From Lemma 7 we have
If \(\gamma _i=0\), then, for \(k\ne i\), it holds
Thus, we have
Furthermore, there is \(\hat{x}_i=x_i\) and \(\hat{L}_i=L_i\). Since \(i\ne \rho (\gamma _r)\) for all \(r\in \{1,\ldots ,n\}\) with \(\gamma _r\ge 1\), we obtain \(\left( [I+M^{(\sigma )}]^\top \right) _{ir}=\delta _{ir}\) and
Consequently, it follows
Now we consider \(T^*_i\). Since \(\mathcal{M}^{(\sigma )}(\hat{S}_i(\hat{x}))=\mathcal{M}^{(\sigma )}(\hat{x})\), we have
If \(\gamma _i\ge 1\) and \(i\ne \rho (\gamma _i)\), then, for \(k\not \in \{i,\rho (\gamma _i)\}\), we also have (26) and, therefore, (27). Moreover, it holds
and
With
we get
From
we get
Furthermore, we obtain
for \(j\ne \gamma _i\) and, by using (28),
If \(\gamma _i\ge 1, i=\rho (\gamma _i)\), then, for \(k\ne i\), we also obtain (26) and, therefore, (27) holds. Furthermore, there is
and
For \(j\ne \gamma _i\), we have (29). In addition, it holds
With \(b:=x_i-z_{\gamma _i}=\hat{x}_i\) and \(c:=\hat{P}_i\left( b+\epsilon _i(L_i-A_{i,:}x)\right) =\left( \hat{S}_i(\hat{x})\right) _i\) we get
and
\(\square \)
Lemma 10
For any \(x\in {\mathbb {R}}^n\) there holds
Proof
Lemma 9 yields
Let \(i\in \{1,\ldots ,n\}\). By induction and from Lemma 8 it follows that
with
Applying Lemma 9 yields
and
The definition of \(S^{*,n}\), \(T^{*,n}\) and \(\hat{S}^n\) yields the assertion. \(\square \)
During the iteration process of Algorithm 1 the close relationship between \(x^{l}\) and \(z^{l}\) is given by the following statement.
Lemma 11
It holds \(z^{l}=-\mathcal{M}^{(\kappa )}(x^{l})\).
Proof
If Algorithm 1 includes the acceleration step (APSOR or LSAPSOR), we get from (15)
Now, we consider Algorithm 1 without the acceleration step (PSOR). The assertion is true for \(l=0\) as \(z^{0}\) is initialized by \(z^{0}:=-\mathcal{M}^{(\kappa )}(x^{0})\). By induction, it follows from Lemma 1, Lemma 8 and Lemma 10
\(\square \)
Lemma 12
Let \(\hat{x}:=(I+M^{(\kappa )})x\) and \(\hat{D}:= (I+M^{(\kappa )})D\). Then, \(\hat{\alpha }_{\hat{D}}(\hat{x})=\alpha _D(x)\), \(\hat{\gamma }_{\hat{D}}(\hat{x})=\gamma _D(x)\) and \(\hat{\xi }_{\hat{D}}(\hat{x},\hat{\gamma }_{\hat{D}}(\hat{x}))=\xi _D(x,\gamma _D(x))\).
Proof
From Lemma 1 and Corollary 4 we conclude for \(\hat{\beta }\in {\mathbb {R}}^r\)
We obtain from Theorem 3
This and (30) give \(\hat{\alpha }_{\hat{D}}(\hat{x})=\alpha _D(x)\). The identity \(\hat{\gamma }_{\hat{D}}(\hat{x})=\gamma _D(x)\) directly follows from Corollary 4. From Theorem 3 we conclude
This shows \(\xi _D(x,\gamma _D(x))=\hat{\xi }_{\hat{D}}(\hat{x},\hat{\gamma }_{\hat{D}}(\hat{x}))\). \(\square \)
Lemma 13
There holds
Proof
For \(l=0\) the assertion is fulfilled. By induction we conclude from Lemma 10 and Lemma 11 that
If Algorithm 1 is applied without the acceleration step (PSOR), Lemma 1 and (31) give
Now we consider Algorithm 1 with the APSOR and LSAPSOR acceleration step. For this purpose set \(\hat{y}:=\hat{S}^n\left( \hat{x}^{l}\right) \) and \(y:=(I+M^{(\sigma )})\hat{y}\). In the APSOR case Lemma 12 and (31) give
Analogously, we obtain in the LSAPSOR case
\(\square \)
Proof of Theorem 6
Let \(l\ge 1\) and define \(\hat{S}^0:{\mathbb {R}}^n\rightarrow {\mathbb {R}}^n\) as \(\hat{S}^0(x):=x\). Furthermore, let \(i\in \{1,\ldots ,n\}\) and define \(\tilde{S}^i:{\mathbb {R}}^n\rightarrow {\mathbb {R}}^n\) as
and set
Due to the projection \(\hat{P}_i\) it is easy to see that \(\eta ^{l}_i \in [0,1]\). From (32) and Lemma 7 we get
Note that for \(y^{l,i}:=\hat{S}^{i}(\hat{x}^l) - \hat{S}^{i-1}(\hat{x}^l)\) it holds
Thus,
If \(\eta ^l_i=0\), then \(\left( \hat{S}^{i}(\hat{x}^l)- \hat{x}^l \right) _i=0\) or \(\left( \tilde{S}^{i}(\hat{x}^l)-\hat{x}^l\right) _i=0\). Note that \(\left( \tilde{S}^{i}(\hat{x}^l)-\hat{x}^l\right) _i=0\) implies
as \(\hat{x}^l\in \hat{K}\) for \(l\ge 1\). Thus, in this case we conclude from (33) that
If \(\eta ^l_i\ne 0\), then (33) yields
Thus, we conclude from (23) and \(\hat{S}^n(\hat{x}^{l})\in \hat{K}\) as well as from (34) and (35)
i.e. the sequence \( \{\hat{E}(\hat{x}^l) \}_{l\in {\mathbb {N}}}\) is monotonic decreasing. Moreover, it is bounded from below as
with the minimal eigenvalue \(\lambda >0\) of \(\hat{A}\) which, in particular, yields
Hence, \( \{\hat{E}(\hat{x}^{l}) \}_{l\in {\mathbb {N}}}\) has a limit. We obtain from (21), (35) and (36)
with
For \(i\in \{1,\ldots ,n\}\) and \(\hat{x}\in {\mathbb {R}}^n\) we obtain from (21) and (22)
where we set \(\infty -a:=\infty \) for some \(a\in {\mathbb {R}}\). For an accumulation point \(\hat{x}^*\in {\mathbb {R}}^n\) let \(\{x^{l_k}\}_{k\in {\mathbb {N}}}\) be a subsequence with the limit \(\hat{x}^*\), i.e. \(\hat{x}^*=\lim _{k\rightarrow \infty } \hat{x}^{l_k}\). In the PSOR case we get from (39)
Hence, \(\hat{x}^*=\lim _{k\rightarrow \infty } \hat{x}^{l_k+1}\) and, thus, \(\hat{S}^{i-1}(\hat{x}^*)=\hat{x}^*\). This and (40) yield
In the APSOR and the LSAPSOR case we conclude from (25) and (38)
Consequently, (39) and (41) imply
with
and, hence,
Defining
we get from (41)
and, thus,
Therefore, in the PSOR case as well as the APSOR and the LSAPSOR case we have \(\hat{x}^*\in \hat{K}\) and \((\hat{A}\hat{x}^*-\hat{L})_i=0\) if \(\hat{g}_i=\infty \). Furthermore, we conclude \(\hat{L}_i-\hat{A}_{i,:} \hat{x}^*\ge 0\). Thus, for \(\hat{y}\in \hat{K}\) we obtain
Since \(\hat{x}\in \hat{K}\) is the unique solution of (10) we have
From (37) it follows that \(\hat{E}\) is coercive. Hence, \(\{\hat{x}^l\}_{l\in {\mathbb {N}}}\) is bounded as \(\{E(\hat{x}^{l}) \}_{l\in {\mathbb {N}}}\) is bounded. This means that \(\{\hat{x}^l\}_{l\in {\mathbb {N}}}\) has at least one accumulation point. From (43) we conclude
and, thus, \(\lim _{l\rightarrow \infty } \hat{x}^l=\hat{x}\). Finally, from Theorem 3 and Lemma 13 we conclude
Since \(\{\hat{E}(\hat{x}^l) \}_{l\in {\mathbb {N}}}\) is monotonic decreasing, Lemma 13 shows that this is also true for the sequence \( \{E(x^l) \}_{l\in {\mathbb {N}}}\). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Banz, L., Schröder, A. A variable transformation to box constraints for solving variational inequalities. Comp. Appl. Math. 44, 135 (2025). https://doi.org/10.1007/s40314-024-03066-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40314-024-03066-x