
Abstract
Sound Event Detection (SED) is the task of detecting and demarcating the segments with specific semantics in audio recording. It has a promising application prospect in security monitoring, intelligent medical treatment, industrial production and so on. However, SED is still in the early stage of development and it faces many challenges, including the lack of accurately annotated data and the poor performance on detection due to the overlap of sound events. In view of the above problems, considering the intelligence of human beings and their flexibility and adaptability in the face of complex problems and changing environment, this paper proposes an approach of human–machine collaboration based SED (HMSED). In order to reduce the cost of labeling data, we first employ two CNN models with embedding-level attention pool module for weakly-labeled SED. Second, in order to improve the abilities of these two models alternately, we propose an end-to-end guided learning process for semi-supervised learning. Third, we use a group of median filters with adaptive window size in the post-processing of output probabilities of the model. Fourth, the model is adjusted and optimized by combining the results of machine recognition and manual annotation feedback. Based on HTML and JavaScript, an interactive annotation interface for HMSED is developed. And we do extensive exploratory experiments on the effects of human workload, model structure, hyperparameter and adaptive post-processing. The result shows that the HMSED is superior to some classical SED approaches.










Similar content being viewed by others
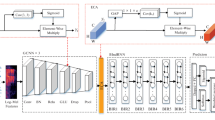

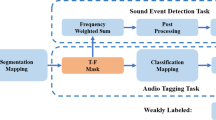
References
Annamaria, M., Toni, H., Tuomas, V.: Metrics for polyphonic sound event detection. Appl. Sci. J. 6(6), 162 (2016)
Bongjun, K., Bryan, P.: A Human-in-the-loop system for sound event detection and annotation. ACM Trans. Interact. Intell. Syst. J. 8(2), 1–13 (2018)
Bongjun K, Shabnam G.: Self-supervised attention model for weakly labeled audio event classification. In: EUSIPCO, pp. 1–5 (2019)
Cakir, E., Parascandolo, G., Heittola, T.: Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. J. 25(6), 129l–1303 (2017)
Gencoglu O, Virtanen H.: Recognition of acoustic events using deep neural networks. In: European Signal Processing Conference, pp. 5–10 (2014)
Heittola F, Mesaros A, Virtanen F.: Sound event detection in multisource environments using source separation. In: Machine Listening in Multisource Environments (2011)
Jort F, Gemmeke, Daniel P.W.E, Dylan F.: Audio set: an ontology and human-labeled dataset for audio events. In: ICASSP, pp. 776–780 (2017)
Kong Q Q, Xu Y, Wang W W.: A joint detection-classification model for audio tagging of weakly labelled data. In : IEEE International Conference on Acoustics Speech and Signal Processing. New Orleans, LA, USA, pp.641–645 (2017).
Lin, C.C., Chen, S.H., Truong, T.K.: Audio classification and categorization based on wavelets and support vector machine. IEEE Trans. Speech Audio Process. J. 13(5), 644–651 (2015)
Liwei L, Xiangdong W, Hong L, Yueliang Qian.: Guided learning for weakly-labeled semi-supervised sound event detection. In: ICASSP, pp. 626–630 (2020)
Lu R, Duan Z, Zhang C.: Multi-scale recurrent neural network for sound event detection. In: IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 131–135(2018)
Mesaros A, Heittola T, Eronen A.: Acoustic event detection in real life recordings. In: IEEE, pp. 1267–1271 (2010)
Parascandolo G, Huttunen H, VirtanenI T.: Recurrent neural networks for polyphonic sound event detection in real life recordings. In: ICASSP, pp. 6440–6444 (2016)
Sabour, S., Frosst, N., Hinton, G.E.: Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. NIPS 3856–3866 (2017)
Shuyang, Z., Toni, H., Tuomas, V.: Active learning for sound event detection. IEEE ACM Trans. Audio Speech Lang. Process 28, 2895–2905 (2020)
Sidiropoulos E, Mezaris, Vkompatsiaris I.: On the use of audio events for improving video scene segmentation. In: International Workshop on Image Analysis for Multimedia Interactive Services WIAMlS.IEEE, pp. 1–4 (2010)
Tarvainen A, Valpola H.: Mean teachers are better role models: weight-averaged consistency targets improve semi-supervised deep learning results. In: Neural Information Processing Systems, pp. 1196–1205 (2017)
Tery P K, Maddage N C, Kankanhalli M S.: Audio based event detection for multimedia surveillance. In: IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, vol. 5, pp.5–5 (2006)
Zhang H, McLoughlin I, Song Y.: Robust sound event recognition using convolutional neural works. In: ICASSP, pp. 559–563 (2015)
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (No. 61960206008, No. 62002294).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ge, S., Yu, Z., Yang, F. et al. Human–machine collaboration based sound event detection. CCF Trans. Pervasive Comp. Interact. 4, 158–171 (2022). https://doi.org/10.1007/s42486-022-00091-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42486-022-00091-9