
Abstract
Deep networks involve a huge amount of computation during the training phase and are prone to over-fitting. To ameliorate these, several conventional techniques such as DropOut, DropConnect, Guided Dropout, Stochastic Depth, and BlockDrop have been proposed. These techniques regularize a neural network by dropping nodes, connections, layers, or blocks within the network. However, these conventional regularization techniques suffers from limitation that, they are suited either for fully connected networks or ResNet-based architectures. In this research, we propose a novel regularization technique LayerOut to train deep neural networks which stochastically freeze the trainable parameters of a layer during an epoch of training. This technique can be applied to both fully connected networks and all types of convolutional networks such as VGG-16, ResNet, etc. Experimental evaluation on multiple dataset including MNIST, CIFAR-10, and CIFAR-100 demonstrates that LayerOut generalizes better than the conventional regularization techniques and additionally reduces the computational burden significantly. We have observed up to 70\(\%\) reduction in computation per epoch and up to 2\(\%\) improvement in classification accuracy as compared to the baseline networks (VGG-16 and ResNet-110) on above datasets. Codes are publically available at https://github.com/Goutam-Kelam/LayerOut.


Similar content being viewed by others
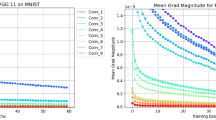


References
Agarap AF. Deep learning using rectified linear units (relu). 2018. arXiv preprint arXiv:1803.08375
Bahdanau D, Chorowski J, Serdyuk D, Brakel P, Bengio Y. End-to-end attention-based large vocabulary speech recognition. In: Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on IEEE; 2016, pp. 4945–4949.
Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans Neural Netw. 1994;5(2):157–66.
Caruana R. Learning many related tasks at the same time with backpropagation. Adv Neural Inf Process Syst. 1995;1995:657–64.
Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2014. pp. 580–587.
Graves A, Mohamed A-R, Hinton G. Speech recognition with deep recurrent neural networks. In: Acoustics, speech and signal processing (icassp), 2013 IEEE international conference on, 2013; pp. 6645–6649. IEEE.
He K, Zhang X, Ren S, Sun J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: Proceedings of the IEEE international conference on computer vision; 2015. pp. 1026–1034.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2016, pp. 770–778.
Huang G, Sun Y, Liu Z, Sedra D, Weinberger KQ. Deep networks with stochastic depth. In: European Conference on Computer Vision. Springer; 2016. pp. 646–661.
Ian G, Jean P-A, Mehdi M, Bing X, David W-F, Sherjil O, Aaron C, Yoshua B. Generative adversarial nets. In: Advances in neural information processing systems; 2014. pp. 2672–2680.
Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167; 2015.
Jansma H. Don’t use dropout in convolutional networks; 2018.
Kumar SR, Greff K, Schmidhuber J. Highway networks. arXiv preprint arXiv:1505.00387; 2015.
Keshari R, Singh R, Vatsa M. Guided dropout. Proc AAAI Conf Artif Intell. 2019;33:4065–72.
Koch G, Zemel R, Salakhutdinov R. Siamese neural networks for one-shot image recognition. In: ICML deep learning workshop, vol. 2. Lille; 2015.
Krizhevsky A, Hinton G. Learning multiple layers of features from tiny images. In: Citeseer: Technical report; 2009.
Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst. 2012;2012:1097–105.
LeCun Y. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/; 1998.
Luong M-T, Pham H, Manning CD. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025; 2015.
Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z. Zeming Lin. Alban Desmaison: Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch; 2017.
Ren S, He K, Girshick R, Sun J. Faster r-cnn: towards real-time object detection with region proposal networks. In: Advances in neural information processing systems; 2015, pp. 91–99.
Robinson AE, Hammon PS, de Sa VR. Explaining brightness illusions using spatial filtering and local response normalization. Vis Res. 2007;47(12):1631–44.
Ruder S. An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747; 2016.
Russakovsky O, Zhiheng S, Karpathy A, et al. Imagenet large scale visual recognition challenge. Int J Comput Vis. 2015;115(3):211–52.
Schroff F, Kalenichenko D, Philbin J. Facenet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2015, pp. 815–823.
Sermanet P, Eigen D, Zhang X, Mathieu M, LeCun Y. Overfeat: integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229; 2013.
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556; 2014.
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res. 2014;15(1):1929–58.
Sutskever I, Vinyals O, Le Quoc V. Sequence to sequence learning with neural networks. Adv Neural Inf Process Syst. 2014;2014:3104–12.
Taigman Y, Yang M, Ranzato MA, Wolf L. Deepface: closing the gap to human-level performance in face verification. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2014, pp. 1701–1708.
Wan L, Zeiler M, Zhang S, Cun YL, Fergus R. Regularization of neural networks using dropconnect. Int Conf Mach Learn. 2013;2013:1058–66.
Wu Z, Nagarajan T, Kumar A, et al. Blockdrop: dynamic inference paths in residual networks. Proc IEEE Conf Comput Vis Pattern Recogn. 2018;2018:8817–26.
Zhong Z, Zheng L, Kang G, Li S, Yang Y. Random erasing data augmentation. arXiv preprint arXiv:1708.04896; 2017.
Acknowledgements
We dedicate this work to our Revered Founder Chancellor, Bhagawan Sri Sathya Sai Baba and the Department of Mathematics and Computer Science, SSSIHL for providing us with the necessary resources needed to conduct our research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Goutam, K., Balasubramanian, S., Gera, D. et al. LayerOut: Freezing Layers in Deep Neural Networks. SN COMPUT. SCI. 1, 295 (2020). https://doi.org/10.1007/s42979-020-00312-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-020-00312-x