
Abstract
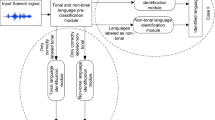
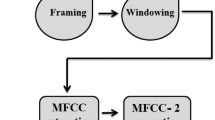
This work proposes a method for the automatic recognition of the Mexican indigenous languages (MILs): Mayan, Mixtec, Zapotec, Mixe, Nahuatl, Tarahumara, Mazahua, Tseltal, Chichimeco and Huichol. The long-term average spectrum (LTAS) is used as a feature for the language recognition process. In addition, the performance of classifiers such as multi-layer perceptron, sequential minimal optimization, naive Bayes, Simple Logistic and Logistic Model Tree is also highlighted. To reduce the features of the speech vector, the LTAS sequences extracted from the audios are first passed to BestFirst filters. In our experiments, high performance for MILs recognition was achieved using a simplified speech coding scheme with feature vectors with a low number of values. Our method is notable for its simplicity and efficiency, since it eliminates untested languages from the speech process. Different classifiers and tunning of its parameters were experimented with increase on accuracy of MILs recognition.







Similar content being viewed by others

Data availability
All relevant data from the paper is available and can be requested from the corresponding author.
References
Sunija A, Rajisha T, Riyas K. Comparative study of different classifiers for Malayalam dialect recognition system. In: International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST), vol. 24, p. 1080–8, 2015.
Liu G, Lei Y, Hansen J. Dialect idenfitication: impact of differences between read versus sponateous speech. In: EUSIPCO2010: European Signal Processing Conference, p. 2003–6, 2010.
Ali A, Dehak N, Cardinal P, Khurana S, Glass J, Bell P, Renal S. Automatic dialect detection in Arabic broadcast speech. Proc Interspeech. 2016;2016:2934–8.
Zongze R, Guofu Y, Shugong X. Two-stage training for chinese dialect recognition. In: Proc. Interspeech 2019, 2019.
Gray S, Hansen J. An integrated approach to the detection and classification of accents/dialects for a spoken document retrieval system. In: IEEE ASRU-2006, p. 35–40, 2006.
United Nations, “United Nations,” 2008. [Online]. Available: https://www.un.org/en/events/iyl/multilingualism.shtml. Accessed 2021 Feb 2021.
Martínez C, Zempoalteca A, Soancatl V, Estudillo M, Lara J, Alcántara S. Computer systems for analysis of Nahuatl. Res Comput Sci. 2012;47:11–6.
Pappu V, Pardalos PM. High-Dimensional Data Classification. In: Aleskerov F, Goldengorin B, Pardalos P, editors. Clusters, Orders, and Trees: Methods and Applications. Springer Optimization and Its Applications, vol. 92. New York, NY: Springer; 2014. https://doi.org/10.1007/978-1-4939-0742-7_8
Othman A, Hasan T, Impact of dimensionality reduction on the accuracy of data classification. In: 3rd international conference on engineering technology and its applications (IICETA) 2020, p. 128–33, 2020. https://doi.org/10.1109/IICETA50496.2020.9318955.
Hassan M, Nath B, Bhuiya M. Bengali phoneme recognition: a new. In: 6th International Conference on Computer and Information Technology, Dhaka, Bangladesh, 2003.
Cheng H, Ma X, Yugong X. A study of speech feature extraction based on manifold learning. J Phys Conf Ser. 2019;1187(5): 052021.
Byrne EAD. An international comparison of long-term average speech spectra. J Acoust Soc Am. 1996;96(4):2108–20.
Antonetti A, Siqueira L, Gobbo M, Brasolotto A, Silverio K. Relationship of cepstral peak prominence-smoothed and long-term average spectrum with auditory-perceptual analysis. Multidiscipl Digit Publ. 2020;10(8598):12.
Tanner K, Roy N, Ash A, Buder EH. Spectral moments of the long-term average spectrum: sensitive indices of voice change after therapy? J Voice. 2005;19(2):211–22.
Boersma P, Weenink D. Praat: doing phonetics by computer [Computer program]. Version 6.1.50. 20 June 2021. [Online]. Available: http://www.praat.org/. Accessed 22 June 2021.
Stephens SS, Volkman J. The relation of pitch to frequency. Am J Psychol. 1940;53(3):329–53.
Huerta L, Huesca J, Contreras J. Speech segmentation algorithm based on fuzzy memberships. Int J Comput Sci Inf Secur. 2010:229–34.
Tukey J, Bogert P, Healy M. The quefrency analysis of time series for echoes: Cepstrum, psuedo-autocovariance, cross-cepstrum and sa phe cracking. In; Proceedings of the Symposium on Time Series Analysis, 2006.
Hummersone C. Calculate the long-term average spectrum of a signal. 2021. [Online]. Available: https://github.com/IoSR-Surrey/MatlabToolbox. Accessed 08 June 2021.
Kinnunen T, Hautmaki V, Franti P. On the use of long-term average spectrum in automatic speaker recognition. In: International Synposium on Chinese Spoken Language Processing (ISCSLP 2006), 2006.
Cukier-Blaj S, Camargo Z, Madureira S. Longterm average spectrum loudness variation in speakers with asthma, paradoxical vocal fold motion and without breathing problems. In: Proceedings of the Fourth Conference on Speech Prosody, no. 9780616220, p. 41–4, 2008.
Lofqvist A. The long-time-average spectrum as a tool in voice research. J Phon. 1986;14:471–5.
Rose P. Forensic speaker identification. London: CRC Press; 2002. p. 380.
Insituto Nacional de Lenguas Indígenas. Prontuarios de frases de cortersía de Lenguas Indígenas. 01 09 2010. [Online]. Available: https://site.inali.gob.mx/Micrositios/Prontuarios/index.html. Accessed 2020 Jan 24.
Ohala J. The origin of sound patterns in vocal tract constraints. In: The production of speech. New York: Springer; 1983. p. 189–216.
Kohavi R, George JH. Wrappers for feature subset selection. Artif Intell. 1997;97(1):273–324.
Pittam J. Voice in social interaction: an interdisciplinary approach. London: SAGE Publications; 1994.
Acknowledgements
This paper is an expanded version of the research presented at the 3rd Geographic Information Systems Latin-American (GIS-LATAM) International Conference Series in October 2021.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest. The study was not supported by any funding.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Advances in Telematics, IA and Security” guest edited by Felix Mata, Roberto Zagal Flores and Jose Antonio Leon-Borges.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Huerta-Hernández, L.D., Ramírez-Pacheco, J.C., Toral-Cruz, H. et al. New Method for Automatic Recognition of Mexican Indigenous Languages: Comparative Performance of Classifiers. SN COMPUT. SCI. 4, 649 (2023). https://doi.org/10.1007/s42979-023-01985-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-023-01985-w