
Abstract
The multi-objective particle swarm optimization (MOPSO) is an optimization technique that mimics the foraging behavior of birds to solve difficult optimization problems. MOPSO is well known for its strong global search capability, which efficiently locates solutions that are close to the global optimum across a wide search domain. However, similar to many other optimization algorithms, the fast convergence property of MOPSO can occasionally lead to the population entering the local optimum too soon, obstructing researchers from investigating more efficient solutions. To address this challenge, the study proposes a novel framework that integrates the fireworks algorithm (FA) into MOPSO and establishes a size-double archiving mechanism to maintain population diversity. By preventing population homogenization, this mechanism promotes the retention of better solutions. Additionally, by fusing evolutionary data analysis with particle information, the study offers new individual optimal choices and adaptive parameter tuning to improve the algorithm’s robustness and adaptability and better manage the complexity of multi-objective optimization problems (MOPs). The suggested algorithm is compared with several existing MOPSOs and multi-objective evolutionary algorithms (MOEAs) in simulation experiments. Standard test problems like ZDT, UF, and DTLZ are used in the experiments. The new algorithm performs exceptionally well in terms of improving convergence and population diversity, as well as demonstrating significant competitiveness for solving MOPs.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
MOPs represent a distinct category of optimization problems [1,2,3], characterized by the simultaneous consideration of multiple objective functions during the optimization process. These functions often exhibit conflicting relationships, whereby the pursuit of one objective may result in a trade-off with others [4,5,6]. The focus of multi-objective optimization is not on identifying a single best solution; its real challenge lies in identifying a set of equivalent solutions, which are referred to as a pareto-optimal solution set. They achieve a state of equilibrium between multiple objectives such that no single objective can be further optimized without sacrificing the others.
Because traditional mathematical planning techniques are best suited for tackling single-objective problems (SOP) and are difficult to apply directly to scenarios with several conflicting objectives, they have faced significant difficulties when dealing with MOPs. On the other hand, evolutionary algorithms that rely on population and meta-heuristic properties, like particle swarm optimization (PSO) [7], genetic algorithms [8], ant colony algorithms [9], and differential evolution [10], have proven to be highly effective in resolving MOPs. Other optimization problems like graphical character creation [11], beneficiation operation metrics optimization [12], evolutionary game optimal outcomes [13], inventory control [14], and optimal control of wastewater treatment processes [15] have all been solved by meta-inspired optimization algorithms. Among them, the PSO has shown excellent performance in SOP due to its simplicity, fast convergence, and small number of parameters [16]. In view of this, some scholars have begun to explore the extension of the PSO algorithm to the field of multi-objective optimization, with a view to utilizing its efficient characteristics to cope with more complex MOPs.
Eberhart and Kennedy proposed PSO in 1995 [17]. It is a population-based random search evolutionary method that is extensively utilized in SOP. The PSO method cannot be utilized directly for MOPs optimization because it lacks the mechanisms to preserve the Pareto solution set and the strategy to choose individual optimal solutions (pbest) and global optimal solutions (gbest) from non-dominant alternatives. Two obstacles must be overcome by researchers to apply PSO to MOPs. Finding a balance between preserving Pareto Frontiers’ diversity and convergence is the first task [PF]. This depends on the characteristics and quality of the external elite archive according to the MOPSO algorithm [18].The diversity of the solution set and the algorithm's performance might be impacted by either too quick or too slow convergence in the archive. As a result, it is critical to keep MOPSO's archive diversity and convergence in check. Creating appropriate ways to choose the pbest and gbest for every particle is the second challenge. One of the forerunners in the field of multi-objective optimization is Coello Coello, who first used PSO to solve MOPs [19], paving the way for further investigation. In an effort to meet the demands of various scenarios and enhance performance when working with complex MOPs, researchers have proposed several versions of MOPSO algorithms as the field of MOEAs continues to grow and deepen.
The elite mechanism is important in MOPSO. The algorithm is able to approach the ideal PF by gradually improving the convergence performance by preserving the non-dominated solutions in an external archive. However, during the optimization process, the number of non-dominated solutions may increase quickly [20], which presents a problem for archive maintenance. The scholars have suggested a number of density-based strategies for updating the archive to efficiently manage the non-dominated solutions in it. Among these, the crowding distance method [21], which estimates the degree of crowding among a given solution’s closest neighbors in the target space, directs the updating of archives. To preserve the diversity of solutions, non-dominated solutions with high crowding distance values are preferentially kept during the archive truncation process in related studies. An additional tactic is the adaptive grid [22,23,24], which simplifies the archive by segmenting the target space into several grid cells and eliminating solutions found in areas with a higher concentration of particles according to the grid system. A different approach was taken by Cui et al. [25], who divided the archive into two sections: convergence and diversity. These sections are used to preserve solutions with various attributes. Significant results have been obtained and this strategy partially addresses the issue that a single archive would not be adequate to continuously preserve solutions with convergence and variety. A technique for maintaining archives that was created recently is the reference vector method. To maintain diversified archives, a set of predefined vectors is employed as a reference. The technique is extensively employed in IDMOPSO [27] and MaOPSO-vPF [26]. This method's disadvantage is that the maintenance effect is dependent on the MOP's PF's geometry [28]. Metrics-based approaches are frequently used in MOPSO archives maintenance. Higher contribution values are given priority to be kept in the archive, and all non-dominated solutions in the archive are graded based on how much they contribute to the metrics. This method has been used by MOPSOhv [30] and MaOPSO-CA [29] to manage their archives. But the success of this strategy largely depends on the measures selected; if the assessment metrics are not sound, the algorithm’s performance could suffer greatly.
In terms of leader selection, Li et al. [31] constructed a virtual PF (vPF) based on the geometry of the archive and then estimated the vGD contribution value of the solution to the vPF to rank the solutions in the archive for leader selection. The solutions in the top 10% after sorting are thought to be potential candidates for gbest. This method guarantees that the chosen gbest can precisely assess each solution's contribution to the constituent PF, thereby guiding the algorithm to converge to the PF. However, Wu and Han [20, 32] et al. presented an evolutionary state estimation mechanism in adaptive MOPSO that chooses the diversity global best (d-gbest) and convergence global best (c-gbest) dynamically. This strategy aims to balance the exploration and exploitation capabilities of the algorithm, i.e., to increase the diversity of solutions in the exploration state and promote the convergence of solutions in the exploitation state. However, the pbest selection strategy is often underemphasized in most MOPSO algorithms. For example, in algorithms such as MOEA-DCOPSO [33] and NMPSO [34], pbest selection usually relies solely on the dominance relationship between new solutions and historical pbest. This simplified treatment may neglect the potential value of pbest in guiding the particle search process, thus affecting the search efficiency of the algorithm and the quality of the final solution.
As well, there are several key points to keep in mind when designing an effective MOPSO. First, there is a need to balance global and local search capabilities, i.e., to switch appropriately between exploration and exploitation states [35]. Second, since the parameters of traditional MOPSO are state-independent [36,37,38], the traditional parameters cannot satisfy the requirement of MOPSO to evolve states. In addition, due to the fast convergence speed of MOPSO, it is easy to fall into local optimality and premature convergence [39]. During the development process, if the number of gbest is small, it may cause the particle population to fall into the local optimal region instead of continuing to explore other potentially more optimal regions. Therefore, rational selection of gbest in the archive in the context of MOPSO is another difficulty in MOPSO design [40, 41].
The researchers’ deep thinking and inventive spirit in MOPSO research are evident in these research advances. We think that MOPSO will perform better when handling MOPs with ongoing research and development. This paper proposes an improved MOPSO, called FAMOPSO, to further improve the convergence and diversity of the MOPSO algorithm in the multi-objective optimization process. To overcome the limitations that the traditional MOPSO may encounter when handling complex problems, this study employs a number of novel strategies.
When the number of gbest is small, FA [42] is introduced to generate the best leader (fbest) to guide the population update together with gbest. The algorithm has an explosion mechanism and a diverse search strategy, which can improve diversity and effectively avoid local optimization.
This paper presents an innovative double-size archiving mechanism. Larger archives are designed to store more non-control solutions and effectively maintain archive diversity by diversifying dense areas of particles into scarce areas. While smaller archives focus on preserving elite solutions to improve convergence efficiency, To further optimize archive management, we have introduced adaptive grid techniques, shift-based density estimation (SDE) [43], and crowded distance (CD) [44] strategies that aim to increase archiving diversity and convergence speed.
Finally, this paper deeply analyzes the limitations of the traditional pbest method in the evolutionary process and innovatively introduces a particle-Active mechanism based on information fusion to realize information sharing and communication among particles. Using evolutionary information to dynamically adjust the updating parameters, we improve the adaptability and robustness of the algorithm.
In this study, we provide the reader with a comprehensive understanding of the FAMOPSO algorithm. The article is structured as follows: Sect. 2 introduces the background knowledge of PSO and related work to lay the foundation for the subsequent discussion. Section 3 describes the FAMOPSO algorithm in detail, including the fireworks algorithm to guide the population update, the dual archiving mechanism maintenance strategy, and the role of Active particles. Section 4 verifies the performance of FAMOPSO through experimental results, demonstrating its effectiveness and advantages in MOPs. Finally, Sect. 5 discusses the missing problems of FAMOPSO in terms of applications, limitations of FAMOPSO at this stage, research contributions, and future research directions. By arranging the content in this way, we hope to present the research work on the FAMOPSO algorithm in a systematic way.
2 Related Work
2.1 Introduction to MOPs
In practical application, many optimization problems involve many contradictory objectives that need to be considered and optimized at the same time. This kind of problem is called MOPs. Generally, contradictory MOPS can be mathematically expressed as:
where \(x=\left({x}_{1},{x}_{2},\ldots {x}_{d}\right)\) is a d-dimensional decision vector in the decision space \({R}^{d}\), denoted as: \(\text{x}\in {R}^{d}\). \(F\left(x\right)\) represents an m-dimensional objective vector, where \({f}_{i}\left(x\right)\) represents the objective function in the ith dimension,\({g}_{i}\left(x\right)\ge 0\) is an inequality constraint, and \({h}_{j}\left(x\right)=0\) is an equality constraint.
A simultaneous optimal solution cannot be found in MOPs due to the conflicting aims. Finding a set of Pareto optimum sets, or non-dominated solutions, that form PF in the target space and illustrate the trade-offs between various goals is therefore crucial. These solutions give decision-makers a range of options from which to select the best plan based on their tastes and circumstances. To guarantee convergence to the true PF, discover and preserve the variety of non-dominated solutions and offer guidance for the decision-making process, MOEAs are designed.
2.2 Reasons Why PSO is Suitable for MOPs and Its Advantages
PSO is considered more suitable in solving MOPs, mainly due to the following advantages:
-
1.
.Global search capability: PSO is able to perform global search effectively by simulating the foraging behavior of groups of organisms in nature. Each particle adjusts its moving direction and speed according to the individual historical optimal position and the global optimal position, thus gradually approaching the global optimal solution. This method based on group intelligence makes PSO have stronger exploration ability and wider search space when dealing with MOPs.
-
2.
Diversity maintenance mechanism: to maintain the diversity of the population, PSO employs a variety of strategies, such as maintaining the Pareto front and selecting multiple optimal particles. These strategies help to avoid the algorithm from falling into local optimums and ensure that a widely distributed set of Pareto-optimal solutions are found in multi-objective optimization problems.
-
3.
Convergence improvement means: PSO also employs a variety of convergence improvement means, such as adaptive lattice variants, mutation operators, and so on. These means help to enhance the exploration ability of the algorithm, carry out sufficient exploration in the early stage, and gradually converge to the vicinity of the optimal solution in the later stage.
-
4.
Wide range of applications: PSO algorithms have been widely used in a variety of real-world problems, including engineering design, function optimization, neural network training, path planning, and so on. In multi-objective optimization problems, PSO also shows strong application potential and wide applicability.
In addition to PSO compared with other algorithms such as DE and ACO, the specific advantages of PSO in multi-objective optimization problems are mainly reflected in the following aspects:
-
1.
Simple and easy to implement: the principle of PSO is simple, easy to implement, and easy to understand. In contrast, although DE also has strong global search capability, its parameter setting and variation strategy are relatively complex, while ACO focuses more on simulating the positive feedback mechanism in ant foraging behavior and is relatively weak in the direct handling of multi-objective problems.
-
2.
Efficient global search: PSO is able to quickly perform global search in the solution space through information sharing and collaboration among particles. In contrast, although DE also has some global search capability, it may be less efficient in dealing with complex multi-objective problems; ACO focuses more on local search and path optimization.
-
3.
Flexible fitness calculation: PSO can flexibly define the fitness function according to the specific problem and deal with the trade-off between multiple objectives through the Pareto domination mechanism. In contrast, DE and ACO algorithms may be relatively fixed or not flexible enough in terms of fitness calculation and objective trade-offs.
In summary, the PSO algorithm has the advantages of strong global search capability, effective Pareto domination mechanism, perfect diversity preservation mechanism, various means of convergence improvement, and wide application areas in solving multi-objective problems. Compared with other algorithms such as DE and ACO, PSO shows higher efficiency and wider applicability in MOPs.
2.3 Introduction and Basic Definition of PSO
PSO is a traditional swarm intelligence algorithm that mimics natural social behavior to solve optimization problems. It was inspired by the foraging habits of birds. It is well-known for its quick convergence and straightforward implementation. In the particle swarm algorithm, every particle must communicate with pbest and gbest. By working together and continuously adjusting their own position and speed, the particles are able to discover new solutions within the search space. The traditional PSO is expanded to handle multiple conflicting targets against the backdrop of MOPs. Thus, rather than searching for a single worldwide optimal solution, our goal is to find a collection of non-dominated solutions. Therefore, MOPSO needs a special mechanism to maintain the diversity of solutions and ensure that the algorithm can effectively explore and converge to the real Pareto frontier. The (t + 1) generation particle velocity and position update formula is:
where t denotes the number of iterations, d denotes the dimension of the decision space. \({x}_{i}(t)\) and \({v}_{i}(t)\) denote the position and velocity of the ith particle, respectively. \(\text{i}=\text{1,2},\ldots ,\text{Pmax}\), \(\text{Pmax}\) denotes the number of population particles, \(\omega\) is the inertia weight, \({c}_{1}\) and \({c}_{2}\) are the learning factors, and \({r}_{1}\) and \({r}_{2}\) are two random vectors generated uniformly in [0,1].
3 Algorithm Design of the Proposed FAMOPSO
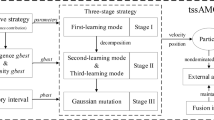
This study proposes an improved algorithm called FAMOPSO in an effort to further improve the performance of MOPSO. The fundamental architecture of the FAMOPSO algorithm is displayed in Fig. 1. FAMOPSO has several important improvements and innovations over the standard MOPSO.

Framework diagram of the proposed FAMOPSO
First, we introduce FA to generate a new fbest and make it work together with the original gbest to guide population renewal. This novel updating mechanism helps the particles get rid of the local optimum and encourages them to explore a wider search area, thus effectively avoiding the algorithm from falling into the local optimum prematurely.
Second, this paper proposes a double-archiving strategy to balance the algorithm’s convergence speed and population diversity. The larger archive is in charge of keeping a lot of non-dominant solutions and preserving population diversity by mutating particles from dense to sparse areas. On the other hand, smaller archives concentrate on keeping the best solution that evolves well to speed up the algorithm’s convergence. To facilitate the efficient management of these two archives, we present adaptive grid technology along with SDE and CD selection strategies. The diversity of archiving can be increased using adaptive grid technology, which can dynamically modify the grid’s size and shape to accommodate the distribution of solutions. Simultaneously, SDE and CD strategies determine the density of the solution based on its distribution and make appropriate decisions to expedite the algorithm's convergence.
Finally, in the aspect of particle renewal, based on the idea of multi-particle information fusion, we redesigned the individual optimal selection mechanism and realized the sharing and exchange of information between particles. In this way, particles can understand the search space more comprehensively and make more reasonable updating decisions. At the same time, we use the evolution information of particles to customize the update parameters of each particle, and these parameters will be dynamically adjusted according to the performance of particles, which enhances the exploration ability of the algorithm.
3.1 Fireworks Algorithm Produces New Leader (fbest)
In traditional MOPSO, the particle updating process is usually guided by the gbest generated by the population. However, only a small number of gbest are usually generated in the early stages of the algorithm's operation. This phenomenon may lead the population to over-rely on these limited resources during the updating process, which increases the risk of falling into local optimal solutions. In addition, our observation also reveals that when dealing with some specific test problems, the population consistently produces only a small number of gbest from the early stage of iteration to the end of the algorithm. This situation further limits the population’s ability to explore the solution space, thus making it difficult to localize to the real PF.
After thorough research and analysis, we found that FA has a significant advantage in generating new leaders. The core idea of this algorithm originates from the firework explosion phenomenon in nature and achieves global search and optimization of the problem by simulating the process of a firework explosion. Collectively, FA regards each feasible solution as a fireworks particle and evaluates their performance according to fitness value in each iteration. Then, the algorithm chooses the best individual as the leader of the current iteration and explodes it to generate new fireworks particles. This process helps the algorithm approach the optimal solution to the problem step by step while maintaining population diversity. It is worth noting that the fireworks algorithm will consider the balance between population diversity and convergence speed when generating new leaders and achieve this goal by adjusting parameters such as explosion radius and spark number.
In this study, we rely on the core idea of FA, which is to use FA to generate fbest and thus facilitate population renewal. Compared with the traditional leader renewal mechanism, the introduction of fbest can not only help the population get rid of the local optimal state but also significantly improve its ability to accurately locate the real PF. This improvement is expected to improve the efficiency of the algorithm in exploring and developing solutions when dealing with MOPs. The specific implementation steps are as follows: during the operation of the algorithm, we pay close attention to the number of non-dominated solutions. When the quantity is insufficient, we use FA to “explode” the existing non-dominated solutions and generate new sparks. Then evaluate these sparks and select outstanding individuals. Together with gbest, these individuals guide population renewal and explore the more optimal solution area. This FA-based mechanism increases population diversity and reduces local optimal risk. Excellent spark and a global optimal solution work together to accelerate convergence and improve solution efficiency. This innovative method provides new ideas for MOPSO, achieves a better balance between exploration and development, and obtains accurate and efficient solutions.
3.2 Specific Steps for fbest Generation
Under close scrutiny of the fireworks display, we are able to recognize two distinct explosion patterns, as shown in Fig. 2. Those that are well crafted release a starburst of sparks that are tightly focused at the center of the explosion, creating a breathtaking spectacle. On the other hand, lesser-quality fireworks display sparks that are not only few in number but also scattered. This is illustrated in the figure. In the algorithm’s perspective, these high-performing fireworks can be viewed as outstanding particles in the population, which lend themselves to deeper exploration in localized areas through more abundant sparks. In contrast, the poor-quality fireworks symbolize the dominated particles, which need to expand their search to find a more optimal solution. In the framework of FA, high-quality fireworks present the properties of a large number of sparks and a limited range of explosion waves. However, in this study, we chose to represent the non-dominated solutions as “fireworks,” which means that all the selected fireworks are of high quality.

Fireworks explosion diagram
In the FA, the explosion radius and the number of sparks produced by the explosion of each firework are calculated based on its adaptation value relative to other fireworks in the firework population. For fireworks xi, the explosion radius Ai and the number of sparks Si are calculated as follows, respectively:
where \({F}_{\text{min}}=\text{min}\sum {f}_{j}\left({x}_{i}\right), {F}_{\text{max}}=\text{max}\sum {f}_{j}\left({x}_{i}\right)\) are the minimum and maximum values of the sum of non-dominated particle fitness values of the current population, respectively. A is a constant used to adjust the size of the blast radius, m is also a constant used to adjust the number of sparks produced by the explosion, and \(\xi\) represents the smallest positive constant in the computer system, which serves to avoid zero error when performing division operations.
To ensure that the number of sparks \({S}_{i}\) is reasonable and to avoid it being too much or too little, we define the boundary of \({S}_{i}\) as shown in the following Eq:
where a and b are parameters that limit the number of sparks to prevent too many or too few and satisfy a < b < 1, and \(round\left(\right)\) is a rounding function based on the principle of rounding.
During a firework explosion, sparks may be affected by the explosion in randomly selected Z dimensions. We randomly determine the number of dimensions affected by the following Eq. (10):
where Z is the number of dimensions of the particle explosion, d is the positional dimension of \(N{s}_{i}\), and \(rand\left(\text{0,1}\right)\) is a random number on [0,1].

In the above process, we have determined the number of firework explosions, the explosion radius, and the dimension of the explosion, and then the particles generate a large number of sparks through Eqs. (11) and (12), and then we select the batch of particles with the best performance, which is referred to as the fbest in this paper, among these sparks. Then the population is guided by the fbest and the gbest together, and the population achieves the information sharing with the population. This process greatly enriches the exploration of the search space and improves the algorithm’s ability to discover Pareto optimal solutions. Its pseudocode is shown in Algorithm 1.
where \({A}_{i}\) is the explosion radius of the ith particle in Eq. (7), \({h}_{i}\) is the magnitude of the change in particle position in Eq. (12), \(\text{rand}\left(\begin{array}{c}-\text{1,1}\end{array}\right)\) is a random number between [− 1, 1], and \(N{s}_{i}^{j}\) denotes the jth position dimension of the ith non-dominated solution.
3.3 Large and Small Double Archiving Mechanism
In real life, we often observe the phenomenon that population size has a significant impact on the production of good talent. A larger population base implies a larger potential talent pool, which increases the likelihood of producing high-quality talent. Drawing on this idea, we design a size-dual archiving mechanism to maintain the archive of the optimization process. The initial step is to construct an archive, designated as A, with a substantial storage capacity. This archive has a maximum capacity three times the number of population particles, allowing it to hold more non-dominated particles. If A can no longer hold as many particles as possible, then an adaptive grid technique is used to keep the archive at a manageable size and guarantee that resources are used wisely. To produce particles of higher quality, secondly, mutation operations are carried out on particles with a higher density in A. Then, to correspond with the population size, archive B is created with a lower capacity. B serves as a storage space for the premium particles that were chosen from A. The population renewal process will thereafter be guided by these particles.
The details are as follows: if the number of particles in archive A does not reach the population size, all particles in archive A are transferred to archive B. When the number of particles in archive A exceeds the population size, a mutation operation is performed, i.e., the crowding distance of each particle is calculated, and some particles with a smaller crowding distance are selected for mutation so as to promote the migration of particles from dense areas to sparse areas and further increase the population diversity. In this process, according to Eq. 13, the particles with a large crowding distance are selected to guide the mutation. After the mutation is completed, the mutated particles with excellent performance are screened and added to archive A. It is confirmed that to balance the population stability and mutation effect, the number of population variations should be controlled between [size(A) − N, N/2] (when size(A) − N > N/2, the number of variation is N/2), where size(A) refers to the number of particles in archive A and N is the population size. Finally, SDE and CD are used to determine which solutions should be transferred to archive B. This method comprehensively considers the distribution of solution sets and individual convergence information, which not only maintains the diversity of solution sets but also ensures good convergence of solution sets. See Algorithm 2 for the relevant algorithms. Using the SDE and CD indicators to select high-quality, non-dominated solutions in Archive A, we can ensure that Archive B is full of potential candidate solutions until Archive B reaches its maximum capacity. Then, the excellent particles in Archive B will lead to population renewal and push the search process to the optimal frontier.
where \({\text{NS}}_{i}\) is the particle with smaller CD value, \({\text{NS}}_{k}\) and \({\text{NS}}_{j}\) are the particles with larger CD value \(\left(i\ne k\ne j\right)\),and \(\text{rand}\left(1\right)\) is a randomly generated random number in [0,1], the formula is oriented to the particles in the sparse region and aims to direct the particles in the dense region towards the coefficient region.
SDE is a transfer-based density estimation strategy that is an improved density estimation method that evaluates the density of individuals by considering their convergence and distributional information. This method not only focuses on the distribution of individuals in the population but also considers the convergence of individuals. SDE is described as follows:
where \({X}_{i}\) is the particle in the large archive A, \((i,j=\text{1,2},3,\ldots ,{N}_{A}\) \(i\ne j)\) \({N}_{A}\) is the number of particles in archive A. \(m=\text{1,2},,\ldots ,M\), \(M\) is denotes the total number of targets. \({f}_{m}\left({X}_{i}\right)\) is denotes the mth target value of the ith particle. \({\stackrel{\Delta }{f}}_{m}\left({X}_{j}\right)\) denotes the target value after shifting the mth target value of the solution \({X}_{j}\).
CD is used to assess and maintain population diversity. It is based on the principle that crowding of individuals is measured by calculating the average distance between each individual and its neighbors, which helps the selection operation to select the better adapted individuals while maintaining the population diversity. CD is described as follows:
where \(F{\text{Min}}_{j}=\text{min}\left({f}_{j}\left(x\right)\right)\) and \(F{\text{Max}}_{j}=\text{max}\left({f}_{j}\left(x\right)\right)\) denote the minimum and maximum values of particle fitness values on the jth dimensional target, respectively, and \(f\left({X}_{i+1,j}\right)\) denotes the jth target value for the i + 1th particle.
In this study, a large-scale archive is built to simulate the influence of population size on talent output in the real world. When using evaluation indices such as SDE and CD to select outstanding individuals, increasing the number of non-dominant solutions can expand the selection range of SDE and CD and then improve the probability of selecting high-quality individuals (see Fig. 3). This mechanism is consistent with the theory that the probability of producing high-quality talents is higher when the population is large and has been successfully applied to the process of solving optimization problems.

Schematic diagram of a large and small double archive
3.4 Active Information Fusion Strategy and Adaptive Parameters for Particle Update Detection
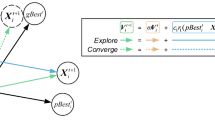
Under the MOPSO framework, the population particles present three unique scenarios when sharing information with pbest, revealing the different states of the particles during information exchange. First, we observe that the particle \({X}_{i}\left(t\right)\) of the current generation dominates the particle \({X}_{i}\left(t-1\right)\) of the previous generation, i.e., \({X}_{i}\left(t\right)\prec {X}_{i}\left(t-1\right)\)(as shown in Fig. 4, a), which clearly indicates that the particle is in an evolutionary state as it is moving towards a more optimal solution region. At this point, the pbest of the particle is updated to \({X}_{i}\left(t\right)\). However, this change results in zero results for the individual cognition part of the update formula, rendering pbest useless in exchanging information with particles.

Schematic of particle evolution
Second, the current generation particle \({X}_{i}\left(t\right)\) is dominated by the previous generation particle \({X}_{i}\left(t-1\right)\), i.e., \({X}_{i}\left(t\right)\succ {X}_{i}\left(t-1\right)\) (as shown in Fig. 4, b), and we recognize that the particle is in a degenerate state. In this case, the pbest of the particle is maintained as \({X}_{i}\left(t-1\right)\), and since the particle has already shown a degenerative trend, continuing to use \({X}_{i}\left(t-1\right)\) as the leader will, with high probability, lead to the population being trapped in a locally optimal solution, which hinders the possibility of exploring a wider solution space.
Algorithm 2: Maintenance of size double archive

Finally, examining the case where the current generation of particles \({X}_{i}\left(t\right)\) and the previous generation of particles \({X}_{i}\left(t-1\right)\) do not dominate each other, i.e., \({X}_{i}\left(t\right)\sim {X}_{i}\left(t-1\right)\) (as shown in Fig. 4c), we find that the particles have neither significantly evolved nor degraded. According to the traditional MOPSO update strategy, the pbest of the particle at this point can be \({X}_{i}\left(t\right)\) or \({X}_{i}\left(t-1\right)\). However, choosing \({X}_{i}\left(t\right)\) as the pbest will also result in zero contribution from the individual cognitive component, while choosing \({X}_{i}\left(t-1\right)\) may cause the population to stagnate in the local optimum and neither choice can effectively promote the overall evolution of the population.
The update of particles in a traditional MOPSO is dependent on tracking their pbest. But as was already mentioned, there are clear flaws in this mechanism for handling MOPs, particularly when it comes to preserving population diversity and averting premature convergence. To address these issues, we developed a novel strategy for selecting leaders—the so-called Active particle. This type of particle is based on the fusion of multi-particle information, which seeks to direct the particle updating process by utilizing both the individual particle information and the global information of the entire population instead of depending solely on the particle’s or its neighbors’ best experience.
Because of the way that Active particles are designed, every particle can achieve a dynamic and varied information exchange. This facilitates information sharing and exchange between particles and improves the algorithm's capacity for exploration. To create a new leader, the Active particle actually chooses at random which member of the population is the best and combines it with the particle itself (see Eq. (16) for more information). In this way, Active particles serve as effective guides for other particles to explore by representing distinct regions in the solution space in addition to high-quality solutions. The algorithm’s performance is greatly enhanced by the addition of the Active mechanism when compared to the conventional pbest method. It not only quickens the algorithm’s rate of convergence but also significantly raises the caliber of the solution that is found. More importantly, Active offers fresh concepts and approaches for resolving challenging MOPs while drastically lowering the likelihood that the algorithm will enter a local optimum by preserving population diversity.
where \(\text{Active}\left(t\right)\) denotes the activated particle of the tth iteration, \({X}_{i}\left(t\right)\) denotes the ith particle of the tth iteration, \(\text{rand}\left(1\right)\) is a randomly generated vector in [0,1] used to increase the randomness of the search, gbest is the global optimal particle. The sharing of information between the particle itself and the global optimal particle particles is considered in Eq. (16), rather than a single dependence on the particle’s own information.
3.5 Adaptive Parameter Tuning Mechanism
In FAMOPSO, the complexity and diversity of the information sharing mechanism of particles puts higher demands on the algorithm, which suggests that the conventional MOPSO method—which uses fixed parameters w, c1, and c2—is insufficient in certain ways. The many requirements and difficulties that particles may encounter at various phases are ignored by this preset parameter setting. This research proposes a novel adaptive adjustment approach in recognition of this. The “dynamic adjustment”—the adaptable modification of important parameters w, c1, and c2 in accordance with the particle state in real time—is the fundamental component of this technique. This implies that the flight path of particles is now shaped by the interaction between particle performance in real time and environmental feedback, rather than by unchangeable rules. By doing this, we can more precisely satisfy the requirements of particles in various update scenarios, enhancing the overall algorithm's effectiveness and efficiency.
The specific adjustment strategies are as follows:
(1) Local optimality escape strategy: in response to the potential degradation phenomenon of particles during the iterative process or the indication of the lack of dominance relationship between particles of two consecutive generations, this paper keenly identifies that the particles may have been caught in the dilemma of local optimality. To effectively address this challenge, the strategy is to adopt a refined parameter tuning scheme, i.e., moderately reducing the values of the inertia weight w and the individual learning factor c1, while significantly boosting the role of the social learning factor c2 (the details of the tuning follow the established adaptive Eq. 17). The aim is to weaken the particles’ reliance on historical trajectories, reduce the risk of premature convergence caused by individual overconfidence, and enhance the information exchange and sharing among particles, encouraging the particle community to explore the solution space with more potentials so as to help the particles break through the current limitations, move towards a broader search frontier, and discover and locate the global optimal solution.
(2) Excellent solution neighborhood exploration strategy: in the journey of multi-objective optimization, when the particles show significant evolutionary momentum, i.e., their trajectories are steadily moving towards the better solution neighborhood, the strategy of this paper turns to focus on deepening the local exploration and fine search. At this point, the parameter configuration is strategically adjusted, which is manifested by increasing the values of the inertia weights w and the individual learning factor c1, while moderately reducing the influence of the social learning factor c2 (the details of the adjustment follow the well-designed adaptive Eq. 18). The purpose of this adjustment is to strengthen the ability of the particles to deeply explore the neighborhood of the current excellent solution and encourage the particles to carry out more detailed mining and iteration on the basis of the known high-quality solutions, with a view to further refining and revealing the better solutions hidden in the neighborhood, thus promoting the continuous refinement and optimization of the algorithm in the solution space.
where \({w}_{i}\) is the inertia weight of the ith particle, \(c{1}_{i}, c{2}_{i}\) are the learning factors of the ith particle. \(W, C1, C2\) the base parameters in Eqs. 17–18, \(\text{rand}\left(1\right)\) is a random number between [0,1],\(F\left({X}_{i}^{t}\right)=\sum f\left({x}_{i,\text{t}}\right)\) is the sum of the fitness values of particle i at the tth iteration, and || denotes the absolute value sign. The common purpose of these three sets of formulas is to dynamically adjust the algorithm parameters according to the current status of the population, including diversity, convergence speed, and other relevant factors, to optimize the algorithm's performance and adaptability. This adaptive adjustment mechanism is an important component in the design of modern MOEAs and is of great significance in improving the solution quality and efficiency of the algorithm.
By utilizing the adaptive adjustment approach mentioned above, every particle can determine the optimal parameter configuration for the present state by evaluating its performance in real-time throughout the search process. The flexibility, adaptability, and overall performance of the FAMOPSO algorithm in handling complex MOPs are much enhanced by this method, which also successfully strikes a balance between the demands of local and global exploration. In addition, this dynamic adjustment mechanism also provides more opportunities for particles to explore new regions in the solution space and dig deeper when promising regions are found, thus accelerating the optimization process and improving the quality of the understanding. Since the new leader-Active particles and adaptive parameters are used, the mathematical expressions for particle updating in this paper are shown in Eqs. (19) and (20).
3.6 In-Depth Analysis—FAMOPSO
In traditional MOPSO, the population tends to lose diversity because it relies on only a few gbest to share information with the population at the beginning of the iteration, leading to the problem of decreasing population diversity and increasing the risk of local optimality. To solve this problem, we borrow the ‘explosion mechanism’ that is unique to FA. This mechanism allows existing gbest to be ‘exploded’ into multiple new individuals, called fbest, which not only inherit some of the good traits of the original gbest, but also carry some new traits after mutation, thus providing more diverse choices and richer genetic information for the whole population. This ensures that even at the beginning of the iteration, when the number of gbest is relatively small, there are enough leaders to guide the population in a better direction. In addition, since fbest are obtained by expanding existing gbest, there is a degree of variability among them that helps to maintain or even improve the overall diversity level of the population.
The experimental results show that, compared to the traditional MOPSO algorithm without any improvements, the FAMOPSO method proposed in this paper is able to significantly reduce the probability of falling into a local optimum while maintaining a high search efficiency. In particular, its advantage is more obvious when dealing with complex multi-peak functions or objective spaces with highly non-linear characteristics. This shows that by introducing the ‘explosion mechanism’ in FA and applying it to the MOPSO framework, the drawbacks of relying on a small number of gbests can be effectively mitigated, and the non-dominated solution front obtained in the end is closer to the real Pareto front.
Second, in the traditional MOPSO archive management strategy, the single archive mechanism dominates, and its core mechanisms all revolve around the particle deletion operation, which is triggered immediately when the archive capacity is exceeded, with the aim of retaining the particles with superior performance as potential candidates for gbest. This process is essentially a one-time screening of the archive content, which directly determines the gbest candidate set.
The innovative double-size archive strategy proposed in this paper is inspired by the principle of a positive correlation between population size and the rate of output of elite talent in human societies, i.e., the larger the base of high-quality individuals, the higher the probability of breeding better individuals. Based on this, we design an oversized primary grand archive, three times the size of the population, with the aim of broadly accommodating non-dominated solutions and ensuring maximum preservation of diversity and convergence. When the grand archive is saturated, it is fine-tuned using an adaptive grid technique, which effectively increases the overall diversity of the population through spatial partitioning with intelligent culling of particles in high-density regions, constituting the first round of selection of non-dominated solutions. We then introduce a secondary mini-archive that matches the population size and use two indicators, SDE and CD, as a scoring system to evaluate the particles in the primary archive in depth. Only the top particles that pass the assessment of these two strict metrics can be promoted to the secondary archive until it reaches its maximum capacity limit. This link is the second round of fine screening for non-dominated solutions. Compared to the traditional approach, our strategy adds an additional layer of filtering mechanism that significantly improves the quality of non-dominated particles as gbest candidates, thus promoting more efficient convergence while increasing the diversity of the algorithm.
In addition, to further enrich the genetic diversity of the large archive and to prevent premature convergence of the algorithm, we embed a mutation mechanism. An adaptive grid strategy is used to locate the densest regions of particle distribution and to target some particles for mutation. This local fine-tuning strategy has little impact on the overall performance of the algorithm due to the limited number of particles, but on the other hand, it can induce particles to migrate to the low-density region, which effectively expands the search space and strengthens the algorithm’s ability to explore the unexplored areas, demonstrating a significant advantage in maintaining the diversity of the population and avoiding the trap of local optimality.
It is worth noting that for the maintenance of the large archive, we use the adaptive grid technique, a strategy that enhances population diversity by dynamically adjusting the grid division in the search space to adapt to changes in the distribution of populations. Specifically, the adaptive grid automatically adjusts the size and position of the grid according to the distribution of individuals in the target space. This method can cover the solution space more effectively, especially for high-dimensional problems, and helps to maintain population diversity and avoid falling into local optima. The effectiveness of this method has been verified in the literature [22,23,24], showing that it can significantly improve the diversity exploration capability of the algorithm. In the small archive pairwise particle screening process, we use the SDE metric, which is an improved density estimation method that enhances population diversity by changing the transfer probability of individuals. Unlike traditional density estimation methods, SDE considers not only the distribution of individuals in the population but also their convergence. Specifically, SDE shifts individuals with poor convergence to crowded regions and assigns them a higher density value, making them more likely to be removed during the selection process. The effectiveness of this strategy is also supported in the literature [43], highlighting its role in improving the overall performance of the algorithm. Overall, both adaptive grids and SDEs are effective strategies for increasing the diversity of MOEAs. Adaptive grids dynamically adjust the partitioning of the search space, while SDE alters the transfer probability of individuals, both of which help to maintain the diversity of the population and prevent the algorithm from prematurely converging to a local optimal solution.
Finally, we analyze the three scenarios of particle updating and find that the traditional pbest is no longer suitable for guiding particle updating. Therefore, in this paper, we innovatively propose the concept of Active particles to replace the traditional pbest, which not only takes into account the information of individuals but also fully integrates the information of the global optimum, thus effectively improving the performance of the algorithm. In addition, we incorporate an adaptive parameter tuning strategy, aiming to break through the bottleneck of the existing algorithms. These initiatives aim to enhance the algorithm’s ability to explore and develop complex multi-objective optimization problems and inject new research vitality and practical paths into the whole field. Through these improvements, we expect to push the multi-objective optimization algorithms in the direction of being more efficient and smarter.
In summary, this paper integrates the FA strategy for generating fbest, the size double archiving strategy, and the design of Active particles and adaptive parameters. It not only effectively solves the problem of insufficient diversity of the MOPSO algorithm at the initial stage but also significantly improves the solving efficiency and accuracy of the algorithm for complex MOPs through the refined management and screening mechanism.
3.7 Complexity Analysis of the Proposed Algorithm
To deeply analyze the computational complexity of the FAMOPSO algorithm, this paper focuses on its core components, covering the fireworks algorithm to generate the fbest, the maintenance mechanism of the small and large double archives, the generation strategy of Active particles, and the dynamic update process of the adaptive parameters. The population size is set to be N, the maximum capacity of the small archive and the large archive are N and 3N, respectively, the target dimension is M, the dimension of the decision space is D, and the number of non-dominated solutions is denoted as G, where the number of non-dominated solutions exceeding the archive capacity is defined as Z (i.e., G − N = Z).
In the maintenance process of the size-double archive, two key aspects are involved: the maintenance operation of the archive and the mutation processing of the particles. The computational complexity of archive maintenance is divided into three scenarios based on different situations:
-
1.
If the sum of the newly generated non-dominated particles of the population and the total number of existing archived particles does not exceed N, they are added directly, and then the computational complexity is O(1).
-
2.
When the sum is between N and 3N, two evaluation indexes, SDE and CD, need to be introduced, both of which have a computational complexity of O(GM), so the overall complexity in this case is O(G + 2GM).
-
3.
If the sum exceeds 3N, the adaptive grid strategy is firstly used to eliminate redundant particles, and the complexity of this step is O(GZ), so the overall complexity is raised to O(G + GZ + 2GM).
The computational complexity of the particle mutation is stable at O(N/2 + GM). Taken together, the maximum computational complexity of the size double archive maintenance part can be expressed as O(G + GZ + 3GM + N/2). Further, the computational complexity involved in the process of generating fbest under the action of FA is O((N + 4) × (N/4)), while the computational complexity of Active particle generation and adaptive parameter adjustment are O(N^2) and O(N), respectively. In particular, it is noted that the computational complexity of Active particle generation is consistent with the process of selecting pbest in the original MOPSO algorithm.
In conclusion, the overall computational complexity of the FAMOPSO algorithm is jointly determined by the key steps of the maintenance of the size double archive, the generation of the fbest, the generation of Active particles, and the timely tuning of the adaptive parameters, and the combined effect of these factors shapes the efficiency and performance characteristics of the algorithm in solving complex multi-objective optimization problems.
4 Experimental Research
This section uses three well-known benchmark test sets, ZDT [45], UF [46], and DTLZ [47], to thoroughly assess the performance of the suggested FAMOPSO method. These test sets encompass a range of attributes and challenges in MOPs, enabling a thorough assessment of the algorithm's efficacy.
We carefully designed a series of experiments and conducted a thorough comparison with other popular MOPSO algorithms to thoroughly examine the performance of the FAMOPSO algorithm. These algorithms, which give a strong basis for our comparison, include MMOPSO [48], MOPSOCD [49], NMPSO [34], SMPSO [50], and dMOPSO [51]. They reflect several research directions and technological advancements in the field of multi-objective optimization. Additionally, we compare this algorithm with a number of competitive MOEAs to assess FAMOPSO's efficiency even more. Among these MOEAs are MOEAD [52], NSGAIII [8], SPER [53], CMOAD [54], and IMMOEA [55], which are recognized as highly proficient examples in the optimization field and exhibit exceptional performance while handling MOPs.
To guarantee the impartiality of any comparative assessment of algorithmic performance, it is essential to ensure that all pertinent parameters established by the comparative algorithm are aligned with the original references. Every test question undergoes 30 separate runs of each algorithm. Using the MATLAB R2020b platform, the experimental results of every algorithm were acquired on an Intel (R) Core (TM) i7-7700 CPU @ 3.60 GHz Windows 10 machine. The transparency and repeatability of the experiment are guaranteed by the source code of the comparison algorithm, which is made available by PlatEMO [56]. The purpose of the experiment is to assess FAMOPSO's performance using a number of quantitative and qualitative metrics. These consist of stability, computational efficiency, diversity, and convergence. These indications allow for a thorough evaluation of FAMOPSO’s performance in managing MOPs from a variety of angles.
The experimental results will provide a comprehensive analysis of the performance differences between FAMOPSO and the comparison algorithm on each benchmark set. The capacity of FAMOPSO to explore and utilize the solution space will be examined, as will its efficacy in maintaining solution diversity and avoiding premature convergence. Furthermore, the performance of FAMOPSO will be examined across a range of MOPs types and difficulties, with a view to establishing its applicability and robustness. This chapter is intended to provide readers with a comprehensive and transparent evaluation of the performance of the FAMOPSO algorithm, based on careful planning of the experimental process and an in-depth discussion of the results.
4.1 Test Questions
To deeply analyze the performance of the FAMOPSO algorithm, we carefully selected and used three different benchmark suites for experimental evaluation. These kits include the diversification problems and PF shapes in the optimization field, which ensures the comprehensive evaluation of the algorithm in various situations. For example, we choose five bi-objective problems in the ZDT suite, which are widely studied in the industry and can effectively test the ability of the algorithm to deal with bi-objective problems with different characteristics. At the same time, we also use seven bi-objective problems, three tri-objective problems of the UF suite, and seven tri-objective problems of the DTLZ suite, each of which considers different PF shapes and dimensions, so as to comprehensively evaluate the performance of the algorithm in MOPs.
It should be pointed out that, due to the particularity of the ZDT5 problem (discrete optimization), we did not take it into consideration. Similarly, DTLZ8 and DTLZ9 are not included because they involve constrained optimization, which is beyond the scope of this study.
Table 1 lists the parameter settings of each test question in detail, including the overall size of the particle swarm (“N”), the number of optimization targets (“M”), the dimension of the decision space (“D”), and the maximum number of evaluations (“Fes”). These parameters are carefully designed according to the uniqueness of each test question to provide a challenging search space for the algorithm and evaluate its performance more accurately. Through these comprehensive benchmark tests, we can fully understand the performance of FAMOPsO on MOPS with different difficulties and types, which is of great significance for deeply understanding the efficiency of the algorithm and guiding its future application and improvement.
4.2 Comprehensive Performance Evaluation Metrics
In FAMOPSO, the key metrics for evaluating the performance of the algorithms include inverted generational distance (IGD) [57] and hypervolume (HV) [58]. These metrics are critical for measuring the performance of the algorithms in solving MOPs.
Mathematical definitions:
where \({P}^{*}\) is a set of uniformly distributed reference points representing the ideal Pareto front; \(P\) is the solution set on the approximate Pareto front generated by the algorithm; \(\parallel \bullet \parallel\) denotes the Euclidean distance; and \(\left|{P}^{*}\right|\) is the number of reference points.The smaller the value of IGD, the closer the solution set generated by the algorithm is to the ideal Pareto front, i.e., the better the convergence and diversity.
where \({v}_{i}\) is the volume of the goal space occupied by each solution in the solution set. A larger value of HV indicates that the non-dominated solutions found cover a wider range of the goal space, thus reflecting the exploratory capability and diversity of the algorithm.
Reasons for selection: IGD considers both convergence and diversity. It not only focuses on the distance of the solution from the true Pareto front (i.e., convergence), but also indirectly promotes diversity in the solution set by minimizing the distance from all reference points to the nearest solution. HV directly quantifies the volume of the target space occupied by the set of approximate solutions and is an important measure of diversity. A high HV value means that the algorithm is able to find more good-quality solutions spread across different regions, which is particularly important for multi-objective optimization.
Discussion of limitations: although IGD and HV are powerful tools for evaluating the performance of MOEAs, they have some limitations:
-
1.
Computational complexity: especially for high-dimensional problems, computing IGD and HV can be very time-consuming as they require the evaluation of a large number of reference points or distances between solutions.
-
2.
Dependence on the choice of reference points: the accuracy of IGD is highly dependent on the choice of reference points. Inappropriate reference points may lead to misinterpretation of the algorithm's performance.
-
3.
Does not fully reflect preferences: both metrics focus on the overall quality of the solution set and do not directly reflect the preferences of a particular decision maker. In some applications, more specific metrics may be needed to assess the quality of solutions that satisfy specific needs.
In summary, we use IGD and HV as key metrics for evaluating the performance of the FAMOPSO algorithm. IGD enables a comprehensive assessment of the convergence and diversity of the algorithm, while HV provides a method of evaluation that does not require reference to the Pareto frontier. Although these metrics have their own strengths and limitations, together they provide us with a comprehensive view that helps us better understand the FAMOPSO.
4.3 Experimental Parameterization
In this paper, we provide an in-depth look at the performance of FAMOPSO on MOPs and compare it to several popular algorithms for MOPSOs, as well as five representative MOEAs. To ensure the fairness of the comparison, we carefully configured the relevant parameters of all the algorithms involved in the comparison to ensure that they are consistent with the settings reported in the respective original references. Such a rigorous approach aims to eliminate any performance bias due to misconfigured parameters, thus ensuring the fairness and reliability of the experimental results. In terms of specific implementation, the FA-related parameters in FAMOPSO were carefully tuned to m = 100, A = 40, a = 0.3, and b = 0.8. Meanwhile, in the adaptive parameter update mechanism, the parameters were set to W = 0.4 and C1 = C2 = 2. The careful selection and tuning of these parameters are intended to enable the FAMOPSO algorithm to maintain a balance between exploration and exploitation, resulting in superior performance on MOPs.
4.4 Experimental Results
Comparison with five other MOPSOs: Tables 2 and 3 provide a detailed account of the performance of the six MOPSOs on the ZDT, UF, and DTLZ test problems. The data set includes the standard deviation and mean of the IGD and HV metrics, thus providing a comprehensive quantitative assessment of the algorithms’ performance. In Tables 2 and 3, the terms “Mean” and “Std” refer to the mean and standard deviation, respectively. The best IGD and HV values are highlighted in bold font to facilitate the rapid identification of the algorithms' strengths on different test problems.
Through an examination of the outcomes condensed in Table 2's final row, we can see that FAMOPSO performed admirably across the 22 benchmark test cases. In particular, FAMOPSO completes 12 test problems with the best results, a feat that fully validates its exceptional performance. MMOPSO, which showed the best performance on five test instances, trailed it closely. While SMPSO performed well on the ZDT6 test problem and MMOPSO performed admirably on the DTLZ test problem, the other MOPSO algorithms in the comparison did not outperform each other on the majority of the test problems. However, their performance on the UF test suite was not as strong. Specifically, SMPSO performs noticeably worse on the DTLZ6 test problem. The aforementioned observations indicate that, while these algorithms exhibit certain strengths, only FAMOPSO is capable of demonstrating consistent efficacy in addressing the majority of test problems, thereby substantiating the soundness and practicality of its design.
Table 3 provides a comprehensive illustration of the comparative outcomes between FAMOPSO and the other five MOPSOs algorithms in relation to HV metrics. As with the IGD comparison results, FAMOPSO also demonstrates excellent performance in the majority of the 22 benchmark tests, significantly outperforming the other algorithms that were compared. The empirical results presented here demonstrate that the proposed FAMOPSO algorithm not only exhibits superior convergence but also maintains solution diversity when solving MOPs.
It is important to remember that the FAMOPSO algorithm’s advantage is a result of its special algorithmic design, not chance. To find a better solution during the search process, FAMOPSO incorporates an update strategy for the fireworks algorithm, which successfully balances the algorithm's exploratory and exploitative capabilities. Convergence speed and algorithm stability are further enhanced by the addition of the size-double archiving mechanism, which guarantees that the algorithm can keep the best-performing population updated to inform iterations. Furthermore, FAMOPSO uses the Active leader strategy, which greatly enhances the algorithm's search performance and strengthens it when handling different MOPs. The innovative designs of the FAMOPSO demonstrate a high level of competitiveness when compared to the selected algorithms for MOPSOs.
Comparison with five existing MOEAs: this paper presents a comparative analysis of the performance of MOEADD, NSGAIII, SPEAR, CMOEAD, IMMOEA, and the FAMOPSO algorithm on a series of standardized test problems, including ZDT1-ZDT4, ZDT6, UF1-UF10, and DTLZ1-DTLZ7, with respect to the IGD and HV metrics. The specific data are detailed in Tables 4 and 5, which list the standard deviation and mean values of each algorithm in detail.
We discover that FAMOPSO exhibits notable benefits in the 22 benchmarking tasks by examining the IGD value data in Table 4. More than half of the test issues yield ideal outcomes for FAMOPSO, which completely proves its superior performance. On the majority of the test issues, however, the other MOEAs in the comparison performed poorly. For instance, while NSGAIII did quite poorly on the ZDT series of test problems, it did well on the DTLZ series. Similar to this, MOEADD performed well on the DTLZ4 test problems but much worse on the DTLZ6 test problems. The comparison between FAMOPSO and the other five MOEAs algorithms on the HV metrics is presented in detail in Table 5. Comparing FAMOPSO against the other examined algorithms, it scores better in 13 out of 22 benchmark tests, which is similar to the IGD comparison results. These empirical findings clearly show that, when solving MOPs, the suggested FAMOPSO algorithm retains solution variety in addition to having superior convergence. The experimental results suggest that while each of these algorithms has some distinct advantages, only FAMOPSO consistently performs exceptionally well on the majority of the investigated issues, demonstrating the validity and broad applicability of its design.
4.5 Comparison of FAMOPSO with Broader MOEAs
To explore the performance advantages of FAMOPSO, we have carefully selected two widely recognized algorithms in the field of MOEAs as benchmarks for comparison: MOEA/D and NSGA-III. Through a multi-dimensional and detailed comparison, FAMOPSO demonstrates its significant unique advantages. Below are the main advantages of FAMOPSO summarized from an exhaustive analysis of the three algorithms:
Strong global search capability: FAMOPSO—using the global search capability of PSO and the fbest generated by FA, it is able to quickly find the potential optimal solution region in the solution space. This global search ability makes FAMOPSO more efficient in dealing with complex MOPs.
MOEA/D: although it also has strong search capability, its decomposition-based strategy may limit the scope of global search in some cases. NSGA-III: emphasizes population diversity through the reference point mechanism, but performance metrics computation and diversity maintenance may be more time-consuming when dealing with hyper-dimensional objective optimization problems.
Fast convergence: FAMOPSO—due to the gbest filtered by PSO’s unique information sharing mechanism and size double archiving mechanism, it is guaranteed that FAMOPSO usually converges to PF faster. MOEA/D: although the computational complexity is lower, it performs well on low-dimensional problems but may face the problem of slower convergence due to decreased selection pressure on high-dimensional problems. NSGA-III uses a reference point mechanism to maintain population diversity, but this approach may increase the computational burden and affect the convergence speed when dealing with super-dimensional objective optimization problems.
High flexibility: FAMOPSO further improves the performance and adaptability of the algorithm through Active particle collaboration mechanisms, adaptive parameters, and the introduction of mutation strategies inside the archive. MOEA/D: while also supporting the use in combination with other algorithms, the decomposition-based strategy may limit the flexibility of its application to some specific problems. NSGA-III: while suitable for handling high-dimensional objective optimization problems, it may require additional strategy tuning when dealing with unconstrained and constrained problems.
In summary, FAMOPSO demonstrates obvious advantages over MOEA/D and NSGA-III in terms of global search capability, convergence speed, and flexibility. These advantages make FAMOPSO more efficient and more widely applicable when dealing with complex MOPs.
4.6 Comparison of MOPSOs Box Plots
To comprehensively evaluate the stability performance of each algorithm on 22 test questions, we construct Fig. 5, which depicts in detail the box-type statistical chart of IGD values of FAMOPSO and five other MOPSOs in 30 independent runs. In this box diagram, the horizontal axis is labeled from 1 to 6 and represents the following algorithms: MMOPSO, MOPSOCD, NMPSO, SMPSO, dMOPSO, and FAMOPSO. The vertical axis shows the IGD values of the corresponding algorithms. As an effective method of data visualization, the box diagram is capable of clearly illustrating the distribution characteristics of the data in question. The box represents the range between the lower quartile (Q1) and the upper quartile (Q3) of the IGD value. The plus symbol indicates an outlier in the data set. A smaller height of the box indicates a greater degree of data concentration, while a reduced number of outliers suggests enhanced algorithmic stability.

Comparison of box plots of 6 MOPSOs
Figure 5 illustrates that the FAMOPSO box diagram is relatively flat on the majority of test problems, indicating a generally low IGD value. This suggests that FAMOPSO exhibits enhanced stability and superior performance in addressing MOPs. In comparison to the other five algorithms, FAMOPSO demonstrates a reduced number of outliers and a more stable data distribution, which serves to reinforce the conclusions presented in Table 2. Consequently, FAMOPSO is not only capable of achieving superior outcomes when solving MOPs, but it is also demonstrably more stable than the other five MOPSOs.
4.7 Comparison of MOEAs Box Plots
Figure 6 illustrates the performance of FAMOPSO and five additional MOEAs on 22 test questions. The statistical box diagram of the IGD value distribution obtained by 30 independent runs allows for an intuitive comparison of the stability of each algorithm. The abscissa of the figure represents the various algorithms, including MOEADD, NSGAIII, SPEAR, CMOEAD, IMMOEA, and FAMOPSO, while the ordinate depicts the IGD value of each algorithm.

Comparison of box plots of 6 MOEAs
As illustrated in Fig. 6, while the IGD values of FAMOPSO on ZDT4, DTLZ1, DTLZ3, and other test problems exhibit considerable volatility and are less stable than those of other algorithms, in the majority of test problems, the anomalous values of FAMOPSO’s experimental data are scarce, the distribution is relatively flat, and the IGD values are typically minimal. This indicates that FAMOPSO exhibits superior comprehensive performance in addressing multi-objective optimization problems, particularly in terms of result quality and algorithm stability.
Further analysis demonstrates that FAMOPSO exhibits remarkable stability on the majority of test problems, primarily due to its distinctive algorithmic design. FAMOPSO incorporates the update strategy of the fireworks algorithm, which enhances the exploration capability. Concurrently, the large and small double archiving mechanisms ensure effective retention of the gbest with optimal performance and improve convergence speed and stability. Additionally, the Active leadership strategy enhances the search capability to address complex problems.
4.8 Comparison of IGD Frontier Maps for Each Algorithm
To provide a comprehensive assessment of the optimization performance of each algorithm, an exhaustive experimental analysis was conducted. In this process, a series of standard test problems, including ZDT2, ZDT3, UF9, and DTLZ7, were used to compare the performance of FAMOPSO with that of ten state-of-the-art comparison algorithms. The distribution of the PF optimal solution sets for these problems is illustrated in Figs. 7, 8, 9, and 10. These graphs offer an intuitive representation of the convergence and diversity of the algorithms under evaluation. Examining Figs. 7, 8, 9, and 10 in detail reveals that FAMOPSO performs better on the ZDT2, ZDT3, UF9, and DTLZ7 problems than the majority of the algorithms used in the comparison. With regard to each test problem, FAMOPSO excels, especially at solving the dual-objective test problem ZDT2. Only MMOPSO and FAMOPSO can precisely locate the PF, as seen in Fig. 7.While MMOPSO can locate the PF as well, its distribution uniformity over the frontier is much less than FAMOPSO’s. Similarly, FAMOPSO demonstrates its superior performance for the ZDT3 problem (Fig. 8), outperforming the other comparison algorithms in terms of localization and distribution accuracy at the PF. As demonstrated in Fig. 9, FAMOPSO fully demonstrates its advantages in convergence and diversity by exhibiting better distribution uniformity near the real PF on the UF9 problem, even in the face of the three-objective problem's complexity. The comparison’s other algorithms exhibit shortcomings in both areas. Looking further at Fig. 10, we can see that FAMOPSO performs significantly better in terms of particle diversity, even though NMPSO and NSGAIII demonstrate good convergence on the more difficult DTLZ7 problem.

Illustration of the IGD front for ZDT2

Illustration of the IGD front for ZDT3

Illustration of the IGD front for UF9

Illustration of the IGD front for DTLZ7
It is evident that FAMOPSO exhibits a more robust and pronounced performance advantage in comparison to alternative algorithms. This further substantiates the efficacy of the learning strategy proposed in this study, which not only ensures the uniform distribution of solutions but also guarantees convergence.
4.9 Comparison of IGD Indicator Convergence Rates
In addition to the aforementioned experimental analysis, another crucial index for evaluating the efficacy of the algorithm is its convergence speed. Figure 11 illustrates the convergence paths of the IGD values generated by all comparison algorithms following 10,000 evaluations by FAMOPSO on ZDT2, ZDT3, UF4, and DTLZ7. The aforementioned paths are classified into two distinct categories. The initial four graphs illustrate the IGD convergence paths of FAMOPSO and five MOPSOs, while the subsequent four graphs depict the IGD convergence paths of FAMOPSO and five MOEAs. As illustrated in the figure, FAMOPSO exhibits a markedly accelerated convergence rate, conferring a significant advantage in enhancing the algorithm’s execution efficiency and calculation speed. A further examination of the final state of each algorithm in the process of convergence reveals that the IGD value of FAMOPSO is the lowest. This not only underscores the notable enhancement in convergence performance of FAMOPSO but also highlights its exceptional capacity for diversity and uniform distribution. These results serve to further confirm the comprehensive performance advantages of the learning strategy proposed by FAMOPSO in dealing with MOPs.

IGD convergence trajectories for FAMOPSO and ten comparison algorithms on four test problems
4.10 Analysis of the Effectiveness of the Algorithm
As mentioned earlier, FAMOPSO incorporates several strategies to enhance the performance of the original MOPSO. To rigorously validate the effectiveness of these strategies, we designed a series of ablation experiments aimed at evaluating the contribution of specific components to the overall performance by systematically removing them. The core of the ablation experiments lies in the control variable approach, i.e., by investigating the change in the system's performance in the absence or weakening of a component, we can gain a deeper understanding of the component's role and value in the overall system.
Specifically, three experimental groups were set up in this study, and one key strategy was excluded from each group to highlight its importance: (1) FAMOPSO without the size-double archive strategy (FAMOPSO-23); (2) FAMOPSO without the fireworks explosion algorithm for generating fbest (FAMOPSO-13); and (3) FAMOPSO lacking adaptive parameter tuning and an information-based fusion strategy to generate Active particles for FAMOPSO (FAMOPSO-12). Meanwhile, the same parameter settings as in the above experiments were maintained, and the standard FAMOPSO was used as a control group.
All three variants of the algorithm and FAMOPSO itself were run independently on the ZDT, UF, and DTLZ test suites for 30 runs to obtain the statistical mean and standard deviation of the IGD and HV metrics. If the experimental group shows a significant performance dip compared to the control group, it is a clear indication that the excluded strategies play a key role in improving the performance of the algorithm. Detailed IGD vs. HV comparison results can be found in Tables 6 and 7, where the best results are highlighted in bold black.
From the data in Tables 6 and 7, it can be clearly observed that there is a significant difference in the performance of its variant algorithms compared to FAMOPSO. Specifically, FAMOPSO-23 obtained only one best IGD value on 22 test problems and failed to achieve the best HV value on any problem, while FAMOPSO-13 obtained one best IGD value and two best HV values, and FAMOPSO-12 performed slightly better, obtaining five best IGD values and one best HV value.
In contrast, FAMOPSO, which integrates multiple strategies, performs well on both metrics, obtaining a total of 15 best IGD values and 15 best HV values.
These results strongly demonstrate that the size-double archiving strategy, the firework explosion algorithm for generating fbest, adaptive parameter tuning, and the information fusion-based strategy for generating Active particles all play an integral role in enhancing the performance of the FAMOPSO algorithm. Through an exhaustive comparative analysis between the experimental and control groups, we validate the effectiveness of the proposed strategies and confirm that each of the improvement methods has a positive impact on the original MOPSO algorithm. This finding not only highlights the importance of the use of integrated strategies but also provides valuable insights and directions for the design of future MOEAs.
4.11 Parameter Sensitivity Analysis
The aim of this section is to explore in depth the effect of the key parameter m on the number of sparks mentioned in the paper and how the core parameters W, C1, and C2 in the adaptive inertia weights and learning factor formulations affect the performance mechanism of FAMOPSO. Specifically, the value of parameter m has a direct impact on the output effectiveness of the algorithm: if m is set too small, the algorithm will only generate a small number of fbest, which may lead to the algorithm converging to the local optimum prematurely and missing the opportunity to explore the globally optimal solution; on the contrary, if m is too large, it may lead to the redundancy of the search process, which may in turn reduce the learning efficiency and convergence speed. Given that the inertia weights and learning factors in this paper are dynamically adjusted by an adaptive strategy, their intrinsic mechanisms are quite complex and difficult to be analyzed directly. Therefore, we focus on the basic parameters W, C1, and C2 in the formula of inertia weights and learning factors (i.e., Eqs. 21–23), and through in-depth analyses of their sensitivities, we aim to reveal the specific effects of these parameters on the performance of the algorithm. The reasonable configuration of these parameters is of vital importance to enhance the overall performance of FAMOPSO. In this study, a systematic sensitivity analysis of the above four parameters will be carried out to provide solid theoretical support and practical guidance for the parameter selection of FAMOPSO.
Tables 8, 9 and 10 show in detail the IGD value performance of FAMOPSO under different parameters when dealing with test problems ZDT1, ZDT2, ZDT6, UF4, UF6, UF7, DTLZ6, and DTLZ7. These tests cover three different parameter configurations, specifically the number of fireworks M (taking values of 60, 80, 100, 120, and 140, in that order), the inertia weight base parameter W (0.2, 0.3, 0.4, 0.5, and 0.6, in that order), and the base parameter for the learning factor C1 = C2 (2, 3, 4, 5, and 6, in that order). To highlight the best performance, the best IGD values for each test problem are bolded in the table. For each test problem, the algorithm was run independently 30 times to ensure the reliability and stability of the results.
Analyzing the data in Table A, it can be seen that FMOPSO obtained the best IGD values on 7 out of the 8 test functions when m = 100. This indicates that the performance of the algorithm is optimal at that particular parameter setting. Looking further at Tables B and C, we find that the algorithm similarly achieves optimal performance on 4 test problems for W = 0.4 as well as C1 = C2 = 2. This result further validates the importance of specific parameter combinations to enhance the performance of the algorithm. To demonstrate more intuitively the trend of the IGD values of FMOPSO under different parameter settings, we plotted the data in Tables 8, 9 and 10 as line graphs 12, 13 and 14. These graphs clearly reveal how different parameter configurations affect the IGD results of the algorithm, which in turn helps us to better understand the mechanism of the parameter choices’ impact on the algorithm’s performance.

IGD line graph for different values of m

IGD line graph for different values of W

IGD line graph for different values of C1, C2
4.12 Friedman Rank Test
In the preceding chapter, a comprehensive comparison was conducted between FAMOPSO, MOPSOs, and MOEAs with the adoption of IGD and HV indicators. Additionally, the performance differences between FAMOIPSO and other algorithms were illustrated in an intuitive manner. To provide a more comprehensive evaluation of the performance of FAMOPSO, this chapter introduces the Friedman rank test [16] to facilitate a detailed statistical analysis of the data presented in Tables 2, 3, 4, and 5. This analysis aims to provide a more objective comparison of the overall performance of FAMOPSO with that of the selected comparison algorithm.
Table 11 shows the ordering of IGD indicators and the comprehensive results of the Friedman rank test for each algorithm when it is used to solve the ZDT, UF, and DTLZ test problems. Based on the test findings, FAMOPSO is ranked first in the Friedman rank test because its IGD index on the ZDT and UF series problems is significantly better than that of the other comparative algorithms. In the overall rating of the Friedman test, FAMOPSO continues to rank higher even though its performance in the DTLZ series is not entirely satisfactory. Next, the algorithm ranking data based on the HV index is shown in Table 12. The results demonstrate that FAMOPSO also achieved first place in the Friedman rank test of ZDT and UF test problems, which indicates its efficacy in addressing MOPs.
The detailed analysis of the IGD and HV indicators, along with the statistical verification of the Friedman rank test, clearly demonstrates that the overall performance of FAMOPSO is superior to that of the other ten comparison algorithms in the selected diversified test problems. This outcome serves to illustrate the considerable aptitude of FAMOPSO in addressing intricate MOPs.
5 Summarizing Work on FAMOPSO
5.1 The Discussion of FAMOPSO in Practical Application Areas is Missing
This paper has primarily concentrated on the technical aspects and performance of the FAMOPSO algorithm, with less emphasis on its practical applications in non-technical domains such as management and decision-making. To enhance the practicality and breadth of the research, future work will further investigate the application of FAMOPSO to MOPs. For example, in the field of logistics, FAMOPSO can be used to optimize goods distribution routes and warehouse layouts. In the field of economics, the algorithm can be applied to asset allocation or market strategy analysis. To apply the FAMOPSO algorithm to multi-objective optimization problems in different domains, it is necessary to adjust the parameter settings or introduce specific domain knowledge in accordance with the particular nature and constraints of the problem under consideration. In the future, we will present case studies demonstrating the effectiveness and potential value of the algorithm in solving real-world MOPs.
5.2 Limitations of FAMOPSO
Despite the excellent performance demonstrated by FAMOPSO, it is not without certain inherent limitations. The first issue is that the algorithm may be susceptible to a phenomenon known as ‘dimensional catastrophe’ when confronted with high-dimensional optimization challenges. This not only impedes the rate of convergence but also predisposes the search process to converge on a local optimum rather than a global optimum prematurely. Secondly, in real-time optimization scenarios, the computational complexity and response time of FAMOPSO may become significant limitations to its widespread application, particularly in highly time-sensitive environments. Ultimately, while this paper provides a comprehensive analysis of the technical aspects and performance indicators of the FAMOPSO algorithm, it does not delve deeply into its non-technical application value, particularly in the exploration of its potential in practical application scenarios such as management decision-making and strategic planning. In our follow-up work, we will conduct further research in these areas to comprehensively evaluate and promote the application and development of the FAMOPSO algorithm in a wider range of practices.
5.3 Summary of FAMOPSO's Innovations
In this paper, we innovatively propose the FAMOPSO algorithm, which greatly enriches the diversity of the population and significantly accelerates the convergence process through the subtle integration of the FA for generating the fbest that leads the evolution of the population, the well-designed size-double archiving mechanism, as well as the introduction of Active particles based on the fusion of information and designing the adaptive parameters, which are strategies that greatly enrich the diversity of the population and significantly accelerate the convergence process. Experimental data show that FAMOPSO outperforms existing MOPSO variants and MOEAs on several standard test functions, demonstrating its superior ability to solve MOPs.
5.4 The Future of Work
Although FAMOPSO shows significant application potential in the field of MOPs, it still faces many challenges to achieve its wide application across industries and domains. Further research should concentrate on the development of more sophisticated algorithmic enhancement strategies, the creation of bespoke variants of the algorithm for particular application contexts, and the deepening of the algorithm's integration with the practical application environment. Specifically, further explore the optimization of FA parameter settings to enhance the exploration capability and efficiency of FAMOPSO; secondly, consider combining the adaptive parameter tuning mechanism with other intelligent optimization techniques, such as machine learning or deep learning, to achieve more fine-grained dynamic tuning; and lastly, in view of the computational resource constraints of the practical applications, study how to reduce the computational complexity of FAMOPSO and improve its practicality and scalability. By continuously optimizing and improving the FAMOPSO and its application framework, it is anticipated that more efficient and practical solutions for solving complex MOPs will be provided, which will in turn promote further development and innovation in this field.
Data availability
All data generated or analyzed during this study are included in this published article.
References
Li, K., Chen, R.: Batched data-driven evolutionary multi-objective optimization based on manifold interpolation. IEEE Trans. Evol. Comput.Evol. Comput. 27(1), 126–140 (2022)
Pescador-Rojas, M., Coello, C.A.C.: Collaborative and adaptive strategies of different scalarizing functions in MOEA/D. IEEE Congr. Evol. Comput. (CEC) 2018, 1–8 (2018)
Hu, Y., Zhang, Y., Gong, D.: Multi-objective particle swarm optimization for feature selection with fuzzy cost. IEEE Trans. Cybern. 51, 874–888 (2021)
Moubayed, N.A., Petrovski, A., Mccall, J.: D2MOPSO: MOPSO based on decomposition and dominance with archiving using crowding distance in objective and solution spaces. Evol. Comput.. Comput. 22, 47–77 (2014)
Li, M., Yang, S., Liu, X.: Pareto or non-Pareto: bi-criterion evolution in multi-objective optimization. IEEE Trans. Evol. Comput.Evol. Comput. 20, 645–665 (2016)
Feng, W., Gong, D., Yu, Z.: Multi-objective evolutionary optimization based on online perceiving Pareto front characteristics. Inf. Sci. 581, 912–931 (2021)
bin Mohd Zain, M.Z., Kanesan, J., Chuah, J.H., Dhanapal, S., Kendall, G.: A multi-objective particle swarm optimization algorithm based on dynamic boundary search for constrained optimization. Appl. Soft Comput.Comput. 70, 680–700 (2018)
Deb, K., Jain, H.: An evolutionary many-objective optimization algorithm using reference-point-based non-dominated sorting approach, part I: solving problems with box constraints. IEEE Trans. Evol. Comput.Evol. Comput. 18(4), 577–601 (2013)
Liu, J., Liu, J.: Applying multi-objective ant colony optimization algorithm for solving the unequal area facility layout problems. Appl. Soft Comput.Comput. 74, 167–189 (2019)
Hancer, E.: A new multi-objective differential evolution approach for simultaneous clustering and feature selection. Eng. Appl. Artif. Intell.Artif. Intell. 87, 103307 (2020)
Fister, I., Perc, M., Ljubic, K., Kamal, S.M., Iglesias, A., Fister, I.: Particle swarm optimization for automatic creation of complex graphic characters. Chaos Solitons Fractals 73, 29–35 (2015)
Yang, C., Ding, J., Jin, Y., Chai, T.: Offline data-driven multiobjective optimization: knowledge transfer between surrogates and generation of final solutions. IEEE Trans. Evol. Comput.Evol. Comput. 24, 409–423 (2020)
Zhang, J., Zhang, C., Chu, T., Perc, M.: Resolution of the stochastic strategy spatial prisoner’s dilemma by means of particle swarm optimization. PLoS ONE 6(7), e21787 (2011)
Taleizadeh, A.A., Niaki, S.T.A., Aryanezhad, M.-B., Shafii, N.: A hybrid method of fuzzy simulation and genetic algorithm to optimize constrained inventory control systems with stochastic replenishments and fuzzy demand. Inf. Sci. 220, 425–441 (2013)
Han, H.G., Zhang, L., Liu, H.X., Qiao, J.F.: Multi-objective design of fuzzy neural network controller for wastewater treatment process. Appl. Soft Comput.Comput. 67, 467–478 (2018)
Lu, J., Zhang, J., Sheng, J.: Enhanced multi-swarm cooperative particle swarm optimizer. Swarm Evol Comput 69, 100989 (2022)
Eberhart,R.C., Kennedy, J.: A new optimizer using particle swarm theory. In: Proceedings of the Sixth International Symposium on Micro Machine and Human Science, IEEE, pp. 39–43 (1995)
Cheng, S.X., Zhan, H., Yao, H.Q., Fan, H.Y., Liu, Y.: Large-scale many-objective particle swarm optimizer with fast convergence based on alpha-stable mutation and logistic function. Appl. Soft Comput.Comput. 99, 106947 (2021)
Coello, C.A.C., Pulido, G.T., Lechuga, M.S.: Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput.Evol. Comput. 8(3), 256–279 (2004)
Wu, B.L., Hu, W., Hu, J.J., Yen, G.G.: Adaptive multi-objective particle swarm optimization based on evolutionary state estimation. IEEE Trans. Cybern. 51, 3738–3751 (2021)
Raquel,C.R., Naval, P.C.: An effective use of crowding distance in multi-objective particle swarm optimization. In: GECCO 2005—Genet. Evol. Comput. Conf., pp. 257–264 (2005)
Yuan,Y.Q., Sun, J., Zhou, D.M.: Multi-objective random drift particle swarm optimization algorithm with adaptive grids. In: 2016 IEEE Congr. Evol. Comput, IEEE, pp. 2064–2070 (2016)
Yang, S.X., Li, M.Q., Liu, X.H., Zheng, J.H.: A grid-based evolutionary algorithm for many-objective optimization. IEEE Trans. Evol. Comput.Evol. Comput. 17, 721–736 (2013)
Hu, W., Yen, G.G.: Adaptive multi-objective particle swarm optimization based on parallel cell coordinate system. IEEE Trans. Evol. Comput.Evol. Comput. 19, 1–18 (2015)
Cui, Y., Meng, X., Qiao, J.: A multi-objective particle swarm optimization algorithm based on two-archive mechanism. Appl. Soft Comput.Comput. 119, 108532 (2022)
Wu,B.L., Hu, W., He, Z.N., Jiang, M., Yen, G.G. A many-objective particle swarm optimization based on virtual pareto front. In: IEEE. Cong. Evol. Comput, (CEC), pp. 78–85 (2018)
Luo, J.P., Huang, X.W., Yang, Y., Li, X., Wang, Z.K., Feng, J.Q.: A many-objective particle swarm optimizer based on indicator and direction vectors for many-objective optimization. Inf. Sci. 514, 166–202 (2020)
Ishibuchi, H., Setoguchi, Y., Masuda, H., Nojima, Y.: Performance of decomposition-based many-objective algorithms strongly depends on pareto front shapes. IEEE Trans. Evol. Comput.Evol. Comput. 21, 169–190 (2017)
Kouka, N., BenSaid, F., Fdhila, R., Fourati, R., Hussain, A., Alimi, A.M.: A novel approach of many-objective particle swarm optimization with cooperative agents based on an inverted generational distance indicator. Inf. Sci. 623, 220–241 (2023)
Garcia,I.C., Coello, C.A.C., Arias-Montano, A.: MOPSOhv: a new hypervolume-based multi-objective particle swarm optimizer. In: IEEE. Cong. Evol. Comput, (CEC), pp. 266–273 (2014)
Li, Y., Zhang, Y., Hu, W.: Adaptive multi-objective particle swarm optimization based on virtual Pareto front. Inf. Sci. 625, 206–236 (2023)
Han, H., Lu, W., Qiao, J.: An adaptive multi-objective particle swarm optimization based on multiple adaptive methods. IEEE Trans. Cybern. 47(9), 2754–2767 (2017)
Zhou, Y., Kang, J.H., Guo, H.N.: Many-objective optimization of feature selection based on two-level particle cooperation. Inf. Sci. 532, 91–109 (2020)
Lin, Q.Z., Liu, S.B., Zhu, Q.L., Tang, C.Y., Song, R.Z., Chen, J.Y., Coello, C.A.C., Wong, K.C., Zhang, J.: Particle swarm optimization with a balanceable fitness estimation for many-objective optimization problems. IEEE Trans. Evol. Comput.Evol. Comput. 22, 32–46 (2018)
Martín, D., Rosete, A., Alcalá-Fdez, J., Herrera, F.: A new multi-objective evolutionary algorithm for mining a reduced set of interesting positive and negative quantitative association rules. IEEE Trans. Evol. Comput.Evol. Comput. 18(1), 54–69 (2014)
Helwig, S., Branke, J., Mostaghim, S.: Experimental analysis of bound handling techniques in particle swarm optimization. IEEE Trans. Evol. Comput.Evol. Comput. 17(2), 259–271 (2013)
Zhang, X., Tian, Y., Cheng, R., Jin, Y.: An efficient approach to non-dominated sorting for evolutionary multiobjective optimization. IEEE Trans. Evol. Comput.Evol. Comput. 19(2), 201–213 (2015)
Cheng, S., Zhao, L., Jiang, X.: An effective application of bacteria quorum sensing and circular elimination in MOPSO. IEEE/ACM Trans. Comput. Biol. Bioinform.Comput. Biol. Bioinform. 14(1), 56–63 (2017)
Feng, Q., Li, Q., Chen, P., Wang, H., Xue, Z., Yin, L., Ge, C.: Multi-objective particle swarm optimization algorithm based on adaptive angle division. IEEE Access 7, 87916–87930 (2019)
Zhang, Y., Wei Gong, D., Hua Zhang, J.: Robot path planning in uncertain environment using multi-objective particle swarm optimization. Neurocomputing 103, 172–185 (2013)
Li, L., Li, G., Chang, L.: A many-objective particle swarm optimization with grid dominance ranking and clustering. Appl. Soft Comput.Comput. 96, 106661 (2020)
Tan Y., Zhu Y.: Fireworks algorithm for optimization. In: Advances in Swarm Intelligence: First International Conference, ICSI 2010, Beijing, China, June 12–15, 2010, Proceedings, Part I 1, pp. 355–364. Springer, Berlin Heidelberg (2010)
Li, M., Yang, S., Liu, X.: Shift-based density estimation for Pareto-based algorithms in many-objective optimization. IEEE Trans. Evol. Comput.Evol. Comput. 18(3), 348–365 (2013)
Raquel,C.R., Naval, P.C.: An effective use of crowding distance in multiobjective particle swarm optimization. In: GECCO 2005—Genet. Evol. Comput. Conf., pp. 257–264 (2005)
Zitzler, E., Deb, K., Thiele, L.: Comparison of multi-objective evolutionary algorithms: empirical results. Evol. Comput.. Comput. 8(2), 173–195 (2000)
Zhang, Q., Zhou, A., Zhao, S., Suganthan, P.N., Liu, W., Tiwari, S.: Multi-objective optimization test instances for the CEC 2009 special session and competition. Mech Eng New York 264, 1–30 (2008)
Deb, K., Thiele, L., Laumanns, M., Zitzler, E.: Scalable test problems for evolutionary multi-objective optimization. In: Evol Mult Opt London, pp. 105–145 (2005)
Lin, Q.Z., Li, J.Q., Du, Z.H., Chen, J.Y., Ming, Z.: A novel multi-objective particle swarm optimization with multiple search strategies. Eur. J. Oper. Res.Oper. Res. 247, 732–744 (2015)
Raquel, C.R., Naval, Jr P.C.: An effective use of crowding distance in multi-objective particle swarm optimization. In: Proceedings of the 7th Annual conference on Genetic and Evolutionary Computation, 257–264 (2005)
Nebro, A.J., Durillo, J.J., Nieto, G., Coello, C.A.C., Luna, F., Alba, E.: SMPSO: a new pso-based metaheuristic for multi-objective optimization. In: 2009 IEEE Symp. Comput. Intell. Multi-Criteria Decis., pp. 66–73 (2009)
Martínez, S.Z., Coello, C.A.C.: A multi-objective particle swarm optimizer based on decomposition. In: Genet. Evol. Comput. Conf. GECCO’11, pp. 69–76 (2011)
Li, K., Deb, K., Zhang, Q.F., Kwong, S.: An evolutionary many-objective optimization algorithm based on dominance and decomposition. IEEE Trans. Evol. Comput.Evol. Comput. 19, 694–716 (2015)
Jiang, S.Y., Yang, S.X.: A strength pareto evolutionary algorithm based on reference direction for multiobjective and many-objective optimization. IEEE Trans. Evol. Comput.Evol. Comput. 21, 329–346 (2017)
Jain, H., Deb, K.: An evolutionary many-objective optimization algorithm using reference-point based non-dominated sorting approach, part II: handling constraints and extending to an adaptive approach. IEEE Trans. Evol. Comput.Evol. Comput. 18(4), 602–622 (2013)
Cheng, R., Jin, Y., Narukawa, K., et al.: A multiobjective evolutionary algorithm using Gaussian process-based inverse modeling. IEEE Trans. Evol. Comput.Evol. Comput. 19(6), 838–856 (2015)
Tian, Y., Cheng, R., Zhang, X.Y., Jin, Y.C.: PlatEMO: A Matlab platform for evolutionary multi-objective optimization. IEEE Comput. Intell. Mag.Comput. Intell. Mag. 12, 73–87 (2017)
Zhou, A.M., Jin, Y.C., Zhang, Q.F., Sendhoff, B., Tsang, E.: Combining model-based and genetics-based offspring generation for multi-objective optimization using a convergence criterion. In: 2006 IEEE Int Conf Evol Comput, pp. 892–899. https://doi.org/10.1109/CEC.2006.1688406 (2006)
While, L., Hingston, P., Barone, L., Huband, S.: A faster algorithm for calculating hypervolume. IEEE Trans. Evol. Comput.Evol. Comput. 10(1), 29–38 (2006). https://doi.org/10.1109/TEVC.2005.851275
Acknowledgements
This paper was partially supported by the Key Laboratory of Evolutionary Artificial Intelligence of Guizhou Province (Qianjiaoji [2022] 059), the Key Talent Program of Digital Economy of Guizhou Province, the National Natural Science Foundation of China (NSFC 62062071), and the Qiankehe Platform Talent ZZSG [2024] 014.
Author information
Authors and Affiliations
Contributions
Yansong Zhang: methodology, software, investigation, validation, writing—original manuscript. Yanmin Liu: project conceptualization, funding acquisition, methodology, project management, writing, review. Xiaoyan Zhang and Qian Song: data management, validation, writing review, and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors certify that they have no competing financial interests or personal relationships that could have influenced the work presented in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Y., Liu, Y., Zhang, X. et al. Multi-objective Particle Swarm Optimization with Integrated Fireworks Algorithm and Size Double Archiving. Int J Comput Intell Syst 18, 2 (2025). https://doi.org/10.1007/s44196-024-00722-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00722-2