
Abstract
The whispered speech enhancement based on a novel improved Mel frequency scale is investigated in the proposed algorithm. The scale is derived from the characteristics of whispered speech. The whispered speech magnitude spectrum recombines with a changed phase spectrum in the process of synthesis rather than preserving the noisy whispered speech phase spectrum. The significance of phase correction is that the low-energy component of the new complex spectrum cancels more than the high-energy component, thus removing background noise as much as possible. Moreover, the noise estimation parameter in the compensated phase is obtained by a new method. This algorithm tries to find a trade-off mechanism between the whispered speech distortion, the noise reduction and the level of remnant music noise. The objective and subjective evaluations show that the proposed algorithm outperforms comparable whispered speech enhancement algorithms.











Similar content being viewed by others
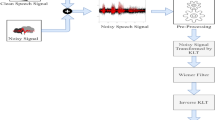
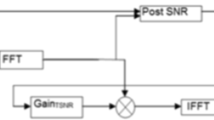

References
S.E. Bou-Ghazale, J.H.L. Hansen, A comparative study of traditional and newly proposed features for recognition of speech under stress. IEEE Trans. Speech Audio Process. 8(4), 429–442 (2000)
I. Eklund, H. Traunmüller, Comparative study of male and female whispered and phonated versions of the long vowels of Swedish. Phonetica 54(1), 1–21 (1997)
A. Farmani, H.B. Bahar, Hardware implementation of 128-Bit AES image encryption with low power techniques on FPGA to VHDL. Majlesi J. Electr. Eng. 6(4), 13–22 (2012)
A. Farmani, M. Jafari, S.S. Miremadi, A high performance hardware implementation image encryption with AES algorithm, in Third International Conference on Digital Image Processing (ICDIP 2011). International Society for Optics and Photonics, vol 8009 (2011) p. 800905
H. Fastl, E. Zwicker, Psychoacoustics; Fact and Models, 3rd edn. (Springer, Berlin, 2006)
D.T. Grozdic, S.T. Jovicic, Whispered Speech recognition using deep denoising autoencoder and inverse filtering. IEEE ACM Trans. Audio Speech Lang. Process. (TASLP) 25(12), 2313–2322 (2017)
W.W. Hung, H.C. Wang, On the use of weighted filter bank analysis for the derivation of robust MFCCs. Signal Process. Lett. IEEE 8(3), 70–73 (2001)
T. Itoh, K. Takeda, F. Itakura, Acoustic analysis and recognition of whispered speech. IEEE Workshop on Automatic Speech Recognition and Understanding. ASRU’01 IEEE, (2001), pp. 429–432
T. Itoh, K. Takeda, F. Itakura, Acoustical analysis and recognition of whispered speech. Speech Commun. 45(2), 139–152 (2005)
S.T. Jovičić, Formant feature differences between whispered and voiced sustained vowels. Acta Acust. united with Acust. 84(4), 739–743 (1998)
K.J. Kallail, F.W. Emanuel, Formant-frequency differences between isolated whispered and phonated vowel samples produced by adult female subjects. J. Speech Lang. Hear. Res. 27(2), 245–251 (1984)
S. Kamath, A Multi-Band Spectral Subtraction Method for Speech Enhancement. Master’s Thesis, University of Texas-Dallas, Department Electrical Engineering, (2001), pp. 34–36
S. Kamath, P. Loizou, A multi-band spectral subtraction method for enhancing speech corrupted by colored noise, in Proceedings International Conference Acoustic, Speech, Signal Processing, Orlando, USA, (2002)
M.S.E. Langarani, H. Veisi, H. Sameti, The effect of phase information in speech enhancement and speech recognition, in International Conference on Information Science, Signal Processing and Their Applications (2012, IEEE), pp. 1446–1447
X.L. Li, B.L. Xu, Formant comparison between whispered and voiced vowels in Mandarin. Acta Acust. united with Acust. 91(6), 1079–1085 (2005)
X.L. Li, D. Hui, B.L. Xu, Entropy-based initial/final segmentation for Chinese whispered speech. Sheng xue Xue bao (ActaAcustica) 30(1), 69–75 (2005)
J.J. Li, I.V. McLoughlin, L.R. Dai, Z.H. Ling, Whisper-to-speech conversion using restricted Boltzmann machine arrays. Electron. Lett. 50(24), 1781–1782 (2014)
J.S. Lim, A.V. Oppenheim, Enhancement and bandwidth compression of noisy speech. Proc. IEEE 67(12), 1586–1604 (1979)
W. Lin, L.L. Yang, B.L. Xu, Speaker recognition of Chinese whispered speech based on modified MFCC parameters. J. Nanjing Univ. (Nat. Sci.) 42(1), 54–62 (2006)
P. Loizou, Speech Enhancement: Theory and Practice (CRC, Boca Raton, 2007)
M. Matsuda, H. Kasuya, Acoustic nature of the whisper, in European Conference on Speech Communication and Technology. DBLP (1999)
G. N. Meenakshi, P. K. Ghosh, Whispered speech to neutral speech conversion using bidirectional LSTMs, in Proceedings of Interspeech, (2018), pp. 491–495
B.C.J. Moore, An Introduction to the Psychology of Hearing, 5th edn. (Academic Press, Cambridge, 2003), pp. 66–69
R.W. Morris, Enhancement and Recognition of Whispered Speech (Georgia Institute of Technology, Georgia, 2003)
R.W. Morris, M.A. Clements, Reconstruction of speech from whispers. Med. Eng. Phys. 24(7–8), 515–520 (2002)
S. Pascual, A. Bonafonte, J. Serrà, J.A. Gonzalez, Whispered-to-voiced Alaryngeal Speech Conversion with Generative Adversarial Networks. arXiv preprint arXiv:1808.10687 (2018)
A.W. Rix, J.G. Beerends, M.P. Hollier, Perceptual evaluation of speech quality (PESQ)—a new method for speech quality assessment of telephone networks and codecs, in IEEE International Conference on Acoustics (IEEE, 2002)
M.F. Schwartz, Identification of speaker sex from isolated, whispered vowels. J. Acoust. Soc. Am. 44(6), 1736–1737 (1968)
A.P. Stark, K.K. Wójcicki, J.G. Lyons, Noise driven short-time phase spectrum compensation procedure for speech enhancement, in Ninth Annual Conference of the International Speech Communication Association (2008)
J. Sun, Z. Tao, J.H. Gu, Research on whisper enhancement based on AD neural network. Comput. Eng. Appl. 43(29), 242–244 (2007)
Z. Tao, H.M. Zhao, D. Wu, Ear speech enhancement based on modified Mel domain masking model and no speech probability. J. Acoust. 34(4), 370–377 (2009)
Z. Tao, X.J. Zhang, H.M. Zhao, Noise reduction in whisper speech based on the auditory masking model, in International Conference on Information Networking and Automation (ICINA), IEEE, vol. 2, (2010), pp. V2-272–V2-277
V.C. Tartter, What’s in a whisper? J. Acoust. Soc. Am. 86(5), 1678–1683 (1989)
V.C. Tartter, Identifiability of vowels and speakers from whispered syllables. Percept. Psychophys. 49(4), 365–372 (1991)
K. Wójcicki, M. Milacic, A. Stark, Exploiting conjugate symmetry of the short-time Fourier spectrum for speech enhancement. IEEE Signal Process. Lett. 15, 461–464 (2008)
W. Xie, Research on Single-Channel Whisper Enhancement Based on Multi-window Spectrum (Southeast University, Nanjing, 2011)
L.L. Yang, W. Lin, B.L. Xu, Research on Chinese whispered isolated character recognition. Appl. Acoust. 25(3), 187–192 (2006)
J. Zhou, Whisper intelligibility enhancement using a supervised learning approach. Circuits Syst. Signal Process. 31(6), 2061–2074 (2012)
J. Zhou, R. Liang, L. Zhao, Unsupervised learning of phonemes of whispered speech in a noisy environment based on convolutive non-negative matrix factorization. Inf. Sci. 257(2), 115–126 (2014)
Acknowledgements
This project was supported by the National Key Research and Development Program of China (Grant No. 2017YFB0503500), the Natural Science Foundation of Jiangsu Province (Grant No. BK20171031) and the Key Laboratory of Virtual Geographic Environment (Nanjing Normal University), Ministry of Education (Grant No. 2017VGE01).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Wei, Y., Li, C., Li, T. et al. Whispered Speech Enhancement Based on Improved Mel Frequency Scale and Modified Compensated Phase Spectrum. Circuits Syst Signal Process 38, 5839–5860 (2019). https://doi.org/10.1007/s00034-019-01164-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-019-01164-4