
Abstract
Speech enhancement aims to separate pure speech from noisy speech, to improve speech quality and intelligibility. A complex convolutional recurrent network with a parameter-free attention module is proposed to improve the effect of speech enhancement. First, the feature information is enhanced by improving the convolutional layer of the encoding layer and the decoding layer. Then, the redundant information is suppressed by adding a parameter-free attention module to extract features that are more effective for the speech enhancement task, and the middle layer is selected for the bidirectional gated recurrent unit. Compared with the best of several baseline models, in the Voice Bank + DEMAND dataset, Perceptual Evaluation of Speech Quality (PESQ) increased by 0.17 (6.23%), MOS predictor of intrusiveness of background noise (CBAK) increased by 0.14 (4.34%), (MOS predictor of overall processed speech quality) COVL increased by 0.40 (12.42%), and (MOS predictor of speech distortion) CSIG index increased by 0.57 (15.28%). Experimental results show that the proposed approach has higher theoretical significance and practical value for actual speech enhancement.




Similar content being viewed by others
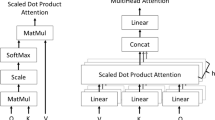

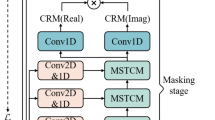
Data Availability
The datasets generated during and/or analyzed during the current study are available from the first author on reasonable request.
Code Availability
The code will be made available on reasonable demand.
References
Y. Bengio, P. Simard, P. Frasconi, Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5, 157–166 (1994)
S. Boll, Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 27, 113–120 (1979)
J. Cao, et al. Do-conv: depthwise over-parameterized convolutional layer. arXiv preprint arXiv:2006.12030 (2020)
K. Cho, B. Van Merriënboer, D. Bahdanau, Y. Bengio, On the properties of neural machine translation: encoder-decoder approaches. arXiv preprint arXiv:1409.1259 (2014)
I. Cohen, B. Berdugo, Speech enhancement for non-stationary noise environments. Signal Process. 81, 2403–2418 (2001)
Y. Ephraim, D. Malah, Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 32, 1109–1121 (1984)
H. Gustafsson, S.E. Nordholm, I. Claesson, Spectral subtraction using reduced delay convolution and adaptive averaging. IEEE Trans. Speech Audio Process. 9(8), 799–807 (2001)
S. Hochreiter, S. Schmidhuber, Long short-term memory. Neural Comput. 9, 1735–1780 (1997)
Y. Hu, et al. DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement. arXiv preprint arXiv:2008.00264 (2020)
Y. Hu, P.C. Loizou, Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 16, 229–238 (2007)
ITU, R. I.-T. P. 862.2: wideband extension to recommendation P. 862 for the assessment of wideband telephone networks and speech codecs. ITU-Telecommunication Standardization Sector (2007)
D.P. Kingma, J. Ba, Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
B. Kumar, Comparative performance evaluation of greedy algorithms for speech enhancement system. Fluct. Noise Lett. 20(02), 2150017 (2021)
J.S. Lim, A.V. Oppenheim, Enhancement and bandwidth compression of noisy speech. Proc. IEEE 67, 1586–1604 (1979)
S.R. Park, J. Lee, A fully convolutional neural network for speech enhancement. arXiv preprint arXiv:1609.07132 (2016)
O. Ronneberger, P. Fischer, T. Brox, in U-net: convolutional networks for biomedical image segmentation. International Conference on Medical image computing and computer-assisted intervention, pp. 234–241 (2015)
D.E. Rumelhart, G.E. Hinton, R.J. Williams, Learning representations by back-propagating errors. Nature 323, 533–536 (1986)
A. Stergiou, R. Poppe, G. Kalliatakis, Refining activation downsampling with Softpool. arXiv preprint arXiv:2101.00440 (2021)
D. Stoller, S. Ewert, S. Dixon, Wave-u-net: A multi-scale neural network for end-to-end audio source separation. arXiv preprint arXiv:1806.03185 (2018)
L. Sun, J. Du, L.-R. Dai, C.-H. Lee, in Multiple-target deep learning for LSTM-RNN based speech enhancement. 2017 Hands-free Speech Communications and Microphone Arrays (HSCMA), pp. 136–140 (IEEE, 2017)
K. Tan, D. Wang, in A convolutional recurrent neural network for real-time speech enhancement. Interspeech, pp. 3229–3233 (2018)
K. Tan, D. Wang, in Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement. ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6865–6869 (IEEE, 2019)
K. Tan, D. Wang, Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement. IEEE/ACM Trans. Audio, Speech, Language Process. 28, 380–390 (2019)
J. Thiemann, N. Ito, E. Vincent, in The diverse environments multi-channel acoustic noise database (DEMAND): a database of multichannel environmental noise recordings. Proceedings of Meetings on Acoustics ICA2013, vol. 19 035081 (Acoustical Society of America, 2013)
C. Tian, Y. Xu, W. Zuo, C.-W. Lin, D. Zhang, Asymmetric CNN for image superresolution. IEEE Trans. Syst. Man Cybernet. Syst. (2021)
C. Valentini-Botinhao, others. Noisy speech database for training speech enhancement algorithms and tts models. (2017)
C. Veaux, J. Yamagishi, S. King, in The voice bank corpus: design, collection and data analysis of a large regional accent speech database. 2013 International Conference Oriental COCOSDA Held Jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), pp. 1–4 (IEEE, 2013)
T.H. Vu, J.-C. Wang, Acoustic scene and event recognition using recurrent neural networks. Detect. Classif. Acoust. Scenes Events (2016)
Y. Wang, D. Wang, in Boosting classification based speech separation using temporal dynamics. Thirteenth Annual Conference of the International Speech Communication Association (2012)
B.S. Webb, N.T. Dhruv, S.G. Solomon, C. Tailby, P. Lennie, Early and late mechanisms of surround suppression in striate cortex of macaque. J. Neurosci. 25, 11666–11675 (2005)
L. Yang, R.-Y. Zhang, L. Li, X. Xie, X. Simam in A simple, parameter-free attention module for convolutional neural networks. International Conference on Machine Learning, pp. 11863–11874 (PMLR, 2021)
H. Zhang, X. Zhang, G. Gao, in Training supervised speech separation system to improve STOI and PESQ directly. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5374–5378 (IEEE, 2018)
M. Zhao, S. Zhong, X. Fu, B. Tang, M. Pecht, Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Industr. Inf. 16, 4681–4690 (2019)
Funding
The research was supported by the National Natural Science Foundation of China (62161040), Natural Science Foundation of Inner Mongolia (2021MS06030) and Inner Mongolia Science and Technology Project (2021GG0023), Supported By Program for Young Talents of Science and Technology in Universities of Inner Mongolia Autonomous Region (NJYT22056)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
None
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Jiangjiao Zeng and Lidong Yang have contributed equally to this work.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zeng, J., Yang, L. Speech Enhancement of Complex Convolutional Recurrent Network with Attention. Circuits Syst Signal Process 42, 1834–1847 (2023). https://doi.org/10.1007/s00034-022-02155-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-022-02155-8