
Abstract
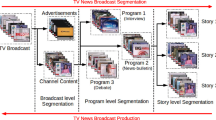
Broadcast news video has been playing an increasingly important role in our daily life. However, how to effectively segment a broadcast news video into meaningful semantic story units is still a challenge issue. In this paper, we propose a novel unified video structure parsing approach, named multiple style exploration-based news story segmentation (MSE-NSS), to segment broadcast news videos into semantic story units. In MSE-NSS, we first investigate the appropriate methods to explore multiple kinds of style information inherent in broadcast news videos, including temporal style inferred from caption texts, boundary style represented by a wealth of multi-modal visual–audio features, and structural style known as the spanning duration of story units. Then the above multiple style information is integrated together and the task of story unit segmentation is accomplished through the following three steps: temporal style-based pre-location, boundary style-based description, and boundary-structural style-based segmentation, where the segmentation process is composed of a SVM-based detector and a dynamic programming-based refiner that considers the boundary style and the structural style collectively. Parallel to this, a news-oriented broadcast management system—NOBMs is implemented on top of the proposed MSE-NSS. Encouraging experimental results on a large broadcast news video dataset demonstrate the effectiveness of the proposed MSE-NSS, as well as its superiority over traditional story unit segmentation methods.








Similar content being viewed by others


References
Ardissono, L., Kobsa, A., Maybury, M. (eds.): Personalized digital television. Kluwer, Norwell (2004)
Xie, L., Zheng, L.L., Liu, Z.H., Zhang, Y.N.: Laplacian eigenmaps for automatic story segmentation of broadcast news. IEEE Trans. Audio Speech Language Process. 20(1), 276–289 (2012)
Zhai, Y., Rasheed, Z., Shah, M.: University of Central Florida at TRECVID 2003. In: Proc. TRECVID Workshop (2003)
Wang, J.Q., Duan, L.Y., Liu, Q.S., Lu, H.Q., Jin, J.S.: A multimodal scheme for program segmentation and representation in broadcast video streams. IEEE Trans. Multimedia 10(3), 393–408 (2008)
Santo, M.D., Foggia, P., Percannella, G., Sansone, C., Vento, M.: An unsupervised algorithm for anchor shot detection. In: Proc. IEEE ICPR, pp. 1238–1241 (2006)
Hsu, W.H., Kenney, L.S., Chang, S.F., Franz, M., Smith, J.: Columbia-IBM news video story segmentation in TRECVID 2004. In: Proc. ACM CIVR, pp. 1–11 (2005)
Gao, X., Tang, X.: Unsupervised video-shot segmentation and model-free anchorperson detection for news video story parsing. IEEE Trans. Circuits System Video Technol. 12(9), 765–776 (2002)
Bertini, M., Bimbo, A.D., Pala, P.: Content-based indexing and retrieval of TV news. Pattern Recogn. Lett. 22, 503–516 (2001)
Shriberg, E., Stolcke, A., Hakkani-Tür, D., Tür, G.: Prosody-based automatic segmentation of speech into sentences and topics. Speech Commun. 32(1–2), 127–154 (2000)
Tür, G., Hakkani-Tür, D.: Integrating prosodic and lexical cues for automatic topic segmentation. Comput. Linguist. 27(1), 31–57 (2001)
Tseng, C.Y., Pin, S.H., Lee, Y., Wang, H.M., Chen, Y.C.: Fluent speech prosody: framework and modeling. Speech Commun. 46(3–4), 284–309 (2005)
Xie, L., Liu, C., Meng, H.: Combined use of speaker and tone-normalized pitch reset with pause duration for automatic story segmentation in mandarin broadcast news. In: Proc. HLT-NAACL, pp. 193–199 (2007)
Xie, L.: Discovering salient prosodic cues and their interactions for automatic story segmentation in mandarin broadcast news. Multimedia Syst. 14(4), 237–253 (2008)
Hearst, M.A.: TextTiling: segmenting text into multi-paragraph subtopic passages. Comput. Liguist. 23(1), 33–64 (1997)
Stokes, N., Carthy, J., Smeaton, A.: SeLeCT: a lexical cohesion based news story segmentation system. J. AI Commun. 17(1), 3–12 (2004)
Chan, S.K., Xie, L., Meng, H.M.L.: Modeling the statistical behavior of lexical chains to capture word cohesiveness for automatic story segmentation. In: Proc. Interspeech, pp. 2408–2411 (2007)
Poulisse, G.J., Moens, M.F.: Multimodal news story segmentation. In: Proc. Int. Conf. on intelligent human computer interaction, pp. 95–101 (2009)
Chaisorn, L., Chua, T.S., Lee, C.H.: A multi-modal approach to story segmentation for news video. World Wide Web Internet Web Inf. Systems 6(2), 187–208 (2003)
Liu, M.M., Zheng, L.L., Leung, C.C., Xie, L., Ma, B., Li, H.Z.: Broadcast news story segmentation using probabilistic latent semantic analysis and laplacian eigenmaps. In: Pro. APSIPA-ASC, pp. 356–360 (2011)
Xu, S., Feng, B.L., Chen, Z.N., Xu, B.: A general framework of video segmentation to logical unit based on conditional random fields. In: Proc. ACM ICMR (2013)
Wang, X., Xie, L., Ma, B., Chng, E.S., Li, H.: Modeling broadcast news prosody using conditional random fields for story segmenation. In: Proc. APSIPA ASC (2010)
Ojala, T., Pietikainen, M., Maenpaa, T.: Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Analysis Mach. Intell. 24(7), 971–987 (2002)
Maitra, R., Peterson, A.D., Ghosh, A.P.: A systematic evaluation of different methods for initializing the K-means clustering algorithm. IEEE Trans. Knowledge Data Eng, 1–11 (2010)
Yang, M.H., Kriegman, D., Ahuja, N.: Detecting faces in images: a survey. IEEE Trans. Pattern Analysis Mach. Intell. 24(1), 34–58 (2002)
Gao, X., Tang, X.: Unsupervised video-shot segmentation and model-free anchorperson detection for news video story parsing. IEEE Trans. Circuits System Video Technol. 12(9), 765–776 (2002)
He, S.N., Yu, J.B.: A novel chinese continuous speech endpoint detection method based on time domain features of the word structure. In: Proc. IEEE ICCCAS, pp. 992–996 (2002)
Yang, S.Y., Zhou, Y.Y., Huang, S.X.: A survey of endpoint detection methods for speech signal. Inf. Technol. 29(7), 5–8 (2005)
Zhu, S.Q., Qiu, X.H.: Research on endpoint detection of speech signals. Comput. Simul. 22(3), 214–216 (2005)
Zhang, S.L., Zhang, S.W., Xu, B.: A two-level method for unsupervised speaker-based audio segmentation. In: Proc. IEEE ICPR, pp. 298–301 (2006)
Liang, J.E., Meng, M., Wang, X.R., Ding, P., Xu, B.: An improved mandarin keyword spotting system using mce training and context-enhanced verfication. In: Proc. IEEE ICASSP, pp. 1145–1148 (2006)
Feng, B.L., Ding, P., Chen, J.S., Bai, J.F., Xu, S., Xu, B.: Multi-modal information fusion for news story segmentation in broadcast video. In: Proc. IEEE ICASSP, pp. 1417–1420 (2012)
Chua, T.S., Chang, S.F., Chaisorn, L., Hsu, W.: Story boundary detection in large broadcast news video archives—techniques, experience and trends. In: Proc. ACM MM, pp. 656–659 (2004)
Cao, J., Ngo, C.W., Zhang, Y.D., Li, J.T.: Tracking web video topics: discovery, visualization and monitoring. IEEE Trans. Circuits Systems Video Technol 21(12), 1835–1846 (2011)
Chen, Z.N., Cao, J., Xia, T., Song, Y.C., Zhang, Y.D., Li, J.T.: Web video retagging. Multimedia Tools Appl. 55(1), 53–82 (2011)
Chen, Z.N., Cao, J., Song, Y.C., Guo, J.B, Zhang, Y.D., Li, J.T.: Context-oriented web video tag recommendation. In: Proc. WWW, pp. 1079–1080 (2010)
Feng, B.L., Cao, J., Bao, L., Zhang, Y.D., Lin, S.X., Bao, X.G., Yun, X.C.: Graph-based multi-space semantic correlation diffusion for video retrieval. Visual Comput. Int. J. Comput. Graphics 27(1), 21–34 (2011)
Yao, T., Ngo, C.W., Mei, T.: Circular reranking for visual search. IEEE Trans. Image Process. 22(4), 1644–1655 (2013)
Hsu, W., Kennedy, L., Huang, C.W., Chang, S.F., Lin, C.Y., Iyengar, G.: News video story segmentation using fusion of multi-level multi-modal features in TRECVID 2003. In: Proc. IEEE ICASSP, pp. 645–648 (2004)
Hsu, W, Chang, S.F., Huang, C.W., Kennedy, L., Lin, C.Y., Iyengar, G.: Discovery and fusion of salient multi-modal features towards news story segmentation. IS&T/SPIE Electronic Imaging. (2004)
Wang, X.X., Xie, L., Lu, M.M., Ma, B., Chng, E.S., Li, H.Z.: Broadcast news story segmentation using conditional random fields and multimodal features. IEICE Trans. Inf. Systems, 95-D(5), 1206–1215 (2012)
Lu, M.M., Xie, L., Fu, Z.H., Jiang, D.M., Zhang, Y.N.: Multi-modal feature integration for story boundary detection in broadcast news. International Symposium on Chinese Spoken Language Processing, pp. 420–425 (2010)
Noreau, N.: HTK(v.3.1): basic tutorial. Technical Report (2002)
Kudo, T.: CRF++: yet another CRF toolkit. Technical Report (2005)
Acknowledgments
This work was supported by National Nature Science Foundation of China (No. 61202326), Beijing Natural Science Foundation (No. 4132071) and National Nature Science Foundation of China (No. 61303175). The authors would like to thank Bao Han and Guoyue Si for their supports with the system UI development.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by P. Pala.
Rights and permissions
About this article
Cite this article
Feng, B., Chen, Z., Zheng, R. et al. Multiple style exploration for story unit segmentation of broadcast news video. Multimedia Systems 20, 347–361 (2014). https://doi.org/10.1007/s00530-013-0350-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-013-0350-0