
Abstract
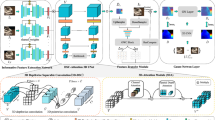
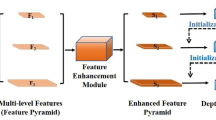
Multi-view stereo (MVS) methods based on deep learning have developed rapidly in recent years, but inaccuracies in reconstruction due to the general effect of feature extraction and poor correlation between cost volumes are still present, opening possibilities for improvement in reconstruction accuracy and completeness. We therefore develop a hierarchical MVS network model with cost volume separation and fusion to mitigate these problems. First, to obtain a more complete and accurate feature information from the input images, a U-shape feature extraction module was designed that outputs feature information simultaneously according to a hierarchical structure composed of three different scales. Then, to enhance the learning ability of the network structure for features, we introduced attention mechanisms to the extracted features that focus on and learn the highlighted features. Finally, in the cost volume regularization stage, a cost volume separation and fusion module was designed in the structure of a hierarchical cascade. This module separates the information within the small-scale cost volume, passes it to the lower level cost volume for fusion, and performs a coarse-to-fine depth map estimation. This model results in substantial improvements in reconstruction accuracy and completeness. The results of extensive experiments on the DTU dataset show that our method performs better than Cascade-MVSNet by about 10.2% in accuracy error (acc.), 7.6% in completeness error (comp.), and 9.0% in overall error (overall), with similar performance in the reconstruction completeness, showing the validity of our module.










Similar content being viewed by others

References
Schönberger, J.L., Zheng, E., Frahm, J.M., Pollefeys, M.: Pixelwise view selection for unstructured multi-view stereo. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer vision–ECCV 2016. Lecture notes in computer science, vol. 9907. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_31
Schönberger, J. L., Frahm, J.: Structure-from-Motion Revisited. 2016 IEEE conference on computer vis-ion and pattern recognition (CVPR), pp. 4104–4113, (2016). https://doi.org/10.1109/CVPR.2016.445
Campbell, N.D.F., Vogiatzis, G., Hernández, C., Cipolla, R.: Using multiple hypotheses to improve depth-maps for multi-view stereo. In: Forsyth, D., Torr, P., Zisserman, A. (eds.) Computer vision–ECCV 2008 lecture notes in computer science, vol. 5302. Springer, Berlin, Heidelberg (2008). https://doi.org/10.1007/978-3-540-88682-2_58
Furukawa, Y., Ponce, J.: Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 32(8), 1362–1376 (2010). https://doi.org/10.1109/TPAMI.2009.161
Galliani, S., Lasinger, K., Schindler, K.: Massi-vely parallel multiview stereopsis by surface norm-al diffusion. 2015 IEEE International Confer-ence on Computer Vision (ICCV), pp. 873–881. (2015). https://doi.org/10.1109/ICCV.2015.106
Tola, E., Strecha, C., Fua, P.: Efficient large-scale multi-view stereo for ultra high-resolution image sets. Mach. Vis. Appl. 23, 903–920 (2012). https://doi.org/10.1007/s00138-011-0346-8
Hartmann, W., Galliani, S., Havlena, M., Van Gool, L., Schindler, K.: Learned Multi-patch Similarity. 2017 IEEE International Conference on Computer Vision (ICCV), pp. 1595–1603, (2017) https://doi.org/10.1109/ICCV.2017.176
Ji, M., Gall, J., Zheng, H., Liu, Y., Fang, L.: SurfaceNet: an end-to-end 3d neural network for multiview stereopsis. 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2326–2334, (2017). https://doi.org/10.1109/ICCV.2017.253
Kar, A., Hane, C., Malik, J.: Learning a multi-view stereo machine. Adv Neural Inf Process Syst (NIPS) (2017). https://arxiv.org/pdf/1708.05375.pdf
Huang, P. H., Matzen, K., Kopf, J., Ahuja, N., Hu-ang, J. B.: DeepMVS: learning multi-view stereo-psis. In Proceedings-2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition). IEEE Computer Society. (2018). pp. 2821–2830. https://doi.org/10.1109/CVPR.2018.00298
Yao, Y., Luo, Z., Li, S., Fang, T., Quan, L.: MVSNet: depth inference for unstructured multi-view Stereo. ArXiv, abs/1804.02505. (2018). https://doi.org/10.1007/978-3-030-01237-3_47.
Yao, Y., Luo, Z., Li, S., Shen, T., Fang, T., Quan, L.: Recurrent MVSNet for high-resolution multi-view stereo depth inference. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5520–5529, (2019). https://doi.org/10.1109/CVPR.2019.00567.
Chen, R., Han, S., Xu, J., Su, H.: Point-Based Multi-View Stereo Network. 2019 IEEE/CVF Inter-national Conference on Computer Vision (ICCV), pp. 1538–1547. (2019). https://doi.org/10.1109/ICCV.2019.00162
Luo, K., Guan, T., Ju, L., Huang, H, Luo, Y.: P-MVSNet: learning patch-wise matching confi-dence aggregation for multi-view stereo. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10451–10460, (2019). https://doi.org/10.1109/ICCV.2019.01055
Gu, X., Fan, Z., Zhu, S., Dai, Z., Tan, F., Tan, P.: Cascade cost volume for high-resolution multi-view stereo and stereo matching. 2020 IEEE/CVF Conference on Computer Vision and Pattern Reco-gnition (CVPR), pp. 2492–2501. (2020). https://doi.org/10.1109/CVPR42600.2020.00257
Yu, Z., Gao, S.: Fast-MVSNet: sparse-to-dense multi-view stereo with learned propagation and gauss-newton refinement. 2020 IEEE/CVF Confer-ence on Computer Vision and Pattern Recognition (CVPR), pp. 1946–1955. (2020). https://doi.org/10.1109/cvpr42600.2020.00202
Aanæs, H., Jensen, R.R., Vogiatzis, G., et al.: Large-scale data for multiple-view stereopsis. Int. J. Comput. Vis. 120, 153–168 (2016). https://doi.org/10.1007/s11263-016-0902-9
Furukawa, Y., Ponce, J.: Carved visual hulls for image-based modeling. Int. J. Comput. Vision 81(1), 53–67 (2009). https://doi.org/10.1007/s11263-008-0134-8
Li, Z., Wang, K., Zuo, W., Meng, D., Zhang, L.: Detail-preserving and content-aware variational multi-view stereo reconstruction. IEEE Trans Image Process 25(2), 864–877 (2016). https://doi.org/10.1109/TIP.2015.2507400
Seitz, S.M., Dyer, C.R.: Photorealistic scene recons-truction by voxel coloring. Int J Computer Vision (IJCV) (1999). https://doi.org/10.1109/CVPR.1997.609462
Merrell, P.C., Akbarzadeh, A., Wang, L., Mordohai, P., Frahm, J., Yang, R., Nistér, D., Pollefeys, M.: Real-time visibility-based fusion of depth maps. 2007 IEEE 11th International Conference on Computer Vision, 1–8. (2007). https://doi.org/10.1109/ICCV.2007.4408984
Newcombe, R.A., Izadi, S., Hilliges, O., Molyneaux, D., Kim, D., Davison, A., Kohli, P., Shotton, J., Hodges, S., Fitzgibbon, A.: KinectFusion: real-time dense surface mapping and tracking. 2011 10th IEEE International Symposium on Mixed and Augmented Reality, 127–136. (2011). https://doi.org/10.1109/ISMAR.2011.6092378
Woo, S., Park, J., Lee, J., Kweon, I.: CBAM: convolutional block attention module. (ECCV) (2018). https://doi.org/10.1007/978-3-030-01234-2_1.
Yang, G., Manela, J., Happold, M., Ramanan, D.: Hierarchical deep stereo matching on high-resolution images. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5510–5519, (2019). https://doi.org/10.1109/CVPR.2019.00566
Luo, W., Schwing, A. G., Urtasun, R.: Efficient deep learning for stereo matching. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5695–5703, (2016). https://doi.org/10.1109/CVPR.2016.614
Zbontar, J., LeCun, Y.: Stereo matching by training a convolutional neural network to compare image patches. J Mach Learn Res 17(65), 1–65 (2016)
Xue Y, Chen J, Wan W, et al.: MVSCRF: learning multi-view stereo with conditional random fields[C]. International Conference on Computer Vision, 2019: 4311–4320
Yu Z, Gao S.: Fast-MVSNet: sparse-to-dense multi-view stereo with learned propagation and gauss-newton refinement[C]. Conference on Computer Vision and Pattern Recognition, 2020: 1946–1955
Yang J, Mao W, Álvarez J, et al.: cost volume pyramid based depth inference for multi-view stereo[C]. Conference on Computer Vision and Pattern Recognition, 2020: 4876–4885
Xu Q, Tao W.: Learning inverse depth regression for multi-view stereo with correlation cost volume[C]. AAAI, 2020: 12508–12515
Yan J, Wei Z, Yi H, et al.: Dense hybrid recurrent multi-view stereo net with dynamic consistency checking[C]. ECCV, 2020: 674–689
Acknowledgements
The DTU datasets used in this paper are from the addresses provided by MVSNet and CascadeMVSNet, and we also thank Y. Yao and X. Gu for sharing their contributions.
Funding
This work was funded by National Natural Science Foundation of China (Grant Number: 42071351) and Liaoning Natural Fund General Project (Grant Number: LJ2019JL010).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare they have no conflict of interest.
Additional information
Communicated by C. Yan.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, W., Wang, J., Qu, H. et al. Hierarchical MVSNet with cost volume separation and fusion based on U-shape feature extraction. Multimedia Systems 29, 377–387 (2023). https://doi.org/10.1007/s00530-022-01009-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-022-01009-2