
Abstract
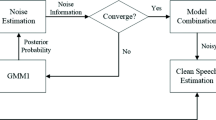
This paper presents a combination approach to robust speech recognition by using two-stage model-based feature compensation. Gaussian mixture model (GMM)-based and hidden Markov model (HMM)-based compensation approaches are combined together and conducted sequentially in the multiple-decoding recognition system. The clean speech is firstly modeled as a GMM in the initial pass, and then modeled as a HMM generated from the initial pass in the following passes, respectively. The environment parameter estimation on these two modeling strategies are formulated both under maximum a posteriori (MAP) criterion. Experimental result shows that a significant improvement is achieved compared to European Telecommunications Standards Institute (ETSI) advanced compensation approach, GMM-based feature compensation approach, HMM-based feature compensation approach, and acoustic model compensation approach.
Similar content being viewed by others

References
Hermansky H (1990) Perceptual linear predictive (PLP) analysis for speech. J Acoust Soc Am 87: 1738–1752
Hermansky H, Morgan N, Bayya A, Kohn P (1991) Rasta-PLP speech analysis
Hunt MJ (1979) A statistical approach to metrics for word and syllable recognition. J Acoust Soc Am 66: S535–S536
Stern RM, Raj B, Moreno PJ (1997) Compensation for environmental degradation in automatic speech recognition. In: Proceedings of ESCA-NATO Tutorial Research Workshop Robust Speech Recognition for Unknown Communication Channels, pp 33–42
Moreno PJ, Raj B, Stern RM (1998) Data-driven environmental compensation for speech recognition: a unified approach. Speech Commun 24: 267–285
Moreno PJ, Raj B, Stern RM (1996) A vector Taylor series approach for environment-independent speech recognition. In: Proceedings of ICASSP-96, pp 733–736
Moreno PJ (1996) Speech recognition in noisy environments. Ph.D. Dissertation, ECE Department, CMU
Raj B, Gouvea EB, Moreno PJ, Stern RM (1996) Cepstral compensation by polynomial approximation for environment-independent speech recognition. In: Proceedings of the International Conference on Spoken Language Processing, Philadelphia, pp 2340–2343
Kim NS (1998) Statistical linear approximation for environment compensation. IEEE Signal Process Lett 5(1): 8–10
Han ZB, Zhang SW, Zhang HY, Xu B (2003) A vector statistical piecewise polynomial approximation algorithm for environment compensation in telephone LVCSR. In: Proceedings of ICASSP-2003, pp 117–120
Kim NS (1998) Nonstationary environment compensation based on sequential estimation. IEEE Signal Process Lett 5(3): 8–10
Deng L, Droppo J, Acero A (2001) Recursive noise estimation using iterative stochastic approximation for stereo-based robust speech recognition. In: Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, pp 81–84
Shen HF, Liu G, Guo J, Li QX (2005) Two-domain feature compensation for robust speech recognition. In: Proceedings of the ISNN-2005, Lecture Notes in Computer Science, vol 3497, Advance in Neural Network-ISNN 2005, Springer, pp 351–356
Shen HF, Liu G, Guo J, Huang PM, Li QX (2005) Environment compensation based on maximum a posteriori estimation for improved speech recognition. In: Proceedings of the MICAI-2005, Lecture Notes in Artificial Intelligence, vol 3789, MICAI 2005. Advances in Artificial Intelligence, Springer, pp 854–862 (2005)
Couvreur C, Hamme HV (2000) Model-based feature enhancement for noisy speech recognition. In: Proceedings of the ICASSP-2000, vol 3, pp 1719–1722
Stouten V, Hamme HV, Demuynck K, Wambacq P (2003) Robust speech recognition using model-based feature enhancement. In: Proceedings of the Eurospeech 2003, pp 17–20
Normandin Y, Cardin R, Mori RD (1994) High-performance connected digit recognition using maximum mutual information estimation. IEEE Trans. Speech Audio Process 2(2):299–311
Nadas A, Nahamoo D, Picheny MA (1998) On a model-robust training method for speech recognition. IEEE Trans Acoust Speech Signal Process 36(9): 1432–1436
Ephraim Y, Dembo A, Rabiner L (1989) A Minimum discrimination information approach for hidden markov modeling. IEEE Trans Inf Theory 35(5): 1001–1013
Gauvain JL, Lee CH (1994) Maximum a posteriori estimation for multivariate Gaussian mixture observation of Markov chains. IEEE Trans Speech Audio Process 2(2): 291–298
Huo Q, Lee CH (1997) On-line adaptive learning of the continuous density hidden Markov model based on approximate recursive Bayes estimate. IEEE Trans Speech Audio Process 5(2): 161–172
Huo Q, Chan C, Lee CH (1995) Bayesian adaptive learning of the parameters of hidden Markov model for speech recognition. IEEE Trans Speech Audio Process 3(5):334–3 (1995)
Huo Q, Chan C, Lee CH (1994) Bayesian learning of the SCHMM parameters for speech recognition. In: Proceedings of the ICASSP-94, vol 1, pp 221–224
Huo Q, Lee CH (1995) A study of on-line quasi-Bayes adaptation for CDHMM-based speech recognition. In: Proceedings of the ICASSP-96, vol 2, pp 705–708
Acero A, Deng L, Kristjansson K, Zhang J (2000) HMM adaptation using vector Taylor series for noisy speech recognition. In: Proceedings of the ICSLP 2000
SagaYama S, Yamaguchi Y, Takahashi S, Takahashi J (1997) Jacobian approach to fast acoustic model adaptation. In: Proceedings of the ICASSP-97, Munich, pp 835–838
Cerisara C, Rigazio L, JunQua JC (2004) α-Jacobian environmental adaptation. Speech Commun 42: 25–41
Gales MJF (1995) Model-based techniques for noise robust speech recognition. Ph.D. thesis, University of Cambridge
Gales MJF, Young SJ (1993) Cepstral parameter compensation for HMM recognition in noise. Speech Commun 12: 231–239
Gales MJF, Young SJ (1995) A fast and flexible implementation of parallel model combination. In: Proceedings of the ICASSP-95, Detroit, pp 133–136
Komori Y, Kosaka T, Yamamoto, H, Yamada M (1997) Fast parallel model combination noise adaptation processing. In: Proceedings of the Eurospeech-97, Rhodes, Greece, pp 1523–1526
Gales MJF (1998) Predictive model-based compensation schemes for robust speech recognition. Speech Commun 25: 49–74
Hwang TH, Wang HC (2000) A fast algorithm for parallel model combination for noisy speech recognition. Comput Speech Lang 14: 81–100
Shen HF, Li QX, Guo J, Liu G (2005) HMM parameter adaptation using the truncated first-order VTS and EM algorithm for robust speech recognition. In: Proceedings of the CIS-2005, Lecture Notes in Artificial Intelligence, vol 3801, Springer, pp 979–984
Kim NS, Lim W, Stern RM (2005) Feature compensation based on switching linear dynamic model. IEEE Signal Process Lett 12(6): 473–476
Droppo J, Acero A (2004) Noise robust speech recognition with a switching linear dynamic model. In: Proceedings of the ICASSP-2004, Montreal, QC, Canada, pp 953–956
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc B 39(1): 1–38
Zu YQ Issues in the scientific design of the continuous speech database. Available at: http://www.cass.net.cn/chinese/s18_yys/yuyin/report/report_1998.htm
Varga A, Steenneken HJM, Tomilson M, Jones D (1992) The NOISEX–92 study on the effect of additive noise on automatic speech recognition. Documentation on the NOISEX-92 CD-ROMs
ETSI standard document. Speech Processing, Transmission and Quality aspects (STQ); Distributed speech recognition; Advanced front-end feature extraction algorithm; Compression algorithm. ETSI document ES 202 050 v1.1.3 (2003-11), Nov. 2003
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Shen, H., Liu, G. & Guo, J. Two-stage model-based feature compensation for robust speech recognition. Computing 94, 1–20 (2012). https://doi.org/10.1007/s00607-011-0152-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00607-011-0152-1