
Abstract
We address the task of identifying tweets that mention books from amongst tweets that contain the same strings as book titles. Assuming the existence of a comprehensive list of book titles, this task can be defined as text classification targeting tweets that contain the same string as book titles. In carrying out the task, we need to exclude two types of tweets. The first is automatically posted, spam-like tweets that promote book sales or post recommendations (bot tweets). This type of tweets is excluded because we are developing an online surrogate to book exposure embedded within human communication on social media, and the results of the present task are to be used in this system. The second is tweets that contain the same string as book titles but are not about books (noise tweets). We proposed a two-step, machine learning-based pipeline consisting of bot filtering followed by noise reduction. Evaluation of experiments showed that our proposed method achieved an F1-score of 0.76, which is comparable to the best performance reported in similar tasks and sufficient as a first step for use in practical applications. We also analysed the detailed performance and errors, which suggested that the proposed method maintained an appropriate balance between precision and recall, and can be further improved by increasing the data size and taking into account word senses.



Similar content being viewed by others

Notes
For instance, Sullivan and Brown [64] showed an evidence for mathematics.
The Telegraph on 11 September 2011 (https://bit.ly/2AVlW8J), and Independent on 21 February 2014 (https://ind.pn/2U5nlk9)
In 1999, there were 22,296 bookstores in Japan, and the number had fallen to 13,488 by 2015 according to the survey of Almedia, Co., Ltd. (Tokyo, Japan).
Traditionally, electronic advertisements have been intended for unintentional information display, although internet users usually perceive them as just annoying [1].
Evidences of US are available in Twenge et al. [68] and The New Yorker which reports ‘fewer people were reading at all, a proportion falling from 26.3% of the population in 2003 to 19.5% in 2016’ based on American Time Use Survey by US Department of Labor (https://bit.ly/2lHvUCV). According to Statistics Bureau of Japan, the average number of people reading books for pleasure declines from 39.5 to 38.7% and average days per year spent for reading decreases from 94.6 to 79.7 days during 2011–2016.
In this paper, italic strings within tweet examples denote actual book titles.
F1-score (F) is defined by \(F = 2 \cdot P \cdot R / (P + R)\), or the harmonic mean of precision (P: the number of relevant documents divided by the number of retrieved documents) and recall (R: the number of relevant documents in the retrieved documents divided by the total number of relevant documents).
ProActive Information Retrieval (ProActIR) workshop (https://sites.google.com/site/proactir/) is an example of the popularity of this field.
This was formerly called BotOrNot [20, 71] (https://botometer.iuni.iu.edu/#!/).
From the Twitter public stream, we collected 2258 tweets that contain the word ‘
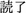 (finished reading)’ in Japanese between 12 and 22 September 2016 and annotated a 10% sample (226 tweets). We obtained 211 (93%) mentions of book titles but only 122 (54%) author names and less than 100 other bibliographic fields.
(finished reading)’ in Japanese between 12 and 22 September 2016 and annotated a 10% sample (226 tweets). We obtained 211 (93%) mentions of book titles but only 122 (54%) author names and less than 100 other bibliographic fields.Since Twitter Inc. announced on 27 September 2017,Footnote 16 a tweet has been able to contain up to 280 characters for all languages except Japanese, Korean, and Chinese.
In Japanese, book titles are supposed to be enclosed by double quotation marks (i.e.
 ).
).Note that all values in every vector are normalised with its L2 norm.
We adopted a popular normalisation scheme for Japanese informal texts (https://github.com/neologd/mecab-ipadic-neologd/wiki/Regexp).
Some tweets use blank spaces and line breaks to be more readable.
This example does not consider any preprocessing which is typically applied in English text processing. Note that we target Japanese tweets.
Webcat Plus is a unified bibliographic database run by the Japan National Institute of Informatics. http://webcatplus.nii.ac.jp/.
We adopted implementations of scikit-learn [51] (v0.20.2) for both algorithms.
Replacing the algorithms we adopted in this paper to simple NN models (e.g. multilayer perceptron and convolutional or recurrent-NN layers) resulted in no significant improvement.
We used Webcat Plus which unifies the wide range of bibliographic databases, such as the national library (National Diet Library, Japan), university libraries, and commercial book catalogues in Japan. See also the footnote 25.
Since some TMBs mention books to be published in the near future at the period of making the tweets, we used the book title list that contains books published by 2016.
In this section, the term TMBs is mentioned in its general meaning.
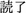 (finished reading)’ in Japanese between 12 and 22 September 2016 and annotated a 10% sample (226 tweets). We obtained 211 (93%) mentions of book titles but only 122 (54%) author names and less than 100 other bibliographic fields.
(finished reading)’ in Japanese between 12 and 22 September 2016 and annotated a 10% sample (226 tweets). We obtained 211 (93%) mentions of book titles but only 122 (54%) author names and less than 100 other bibliographic fields. ).
).References
Adobe: Click here: the state of online advertising. Tech. rep., Adobe Systems Incorporated (2013)
Alharthi, H., Inkpen, D., Szpakowicz, S.: A survey of book recommender systems. J. Intell. Inf. Syst. 51(1), 139–160 (2018)
Alothali, E., Zaki, N., Mohamed, E.A., Alashwal, H.: Detecting social bots on twitter: a literature review. In: International Conference on Innovations in Information Technology (IIT), pp. 175–180. IEEE (2018)
Amigó, E., Corujo, A., Gonzalo, J., Meij, E., de Rijke, M.: Overview of RepLab 2012: evaluating online reputation management systems. In: Forner, P., Karlgren, J., Womser-Hacker, C. (eds.) CLEF 2012 Evaluation Labs and Workshop, Online Working Notes, CEUR-WS.org, CEUR Workshop Proceedings, vol. 1178, pp. 1–24 (2012)
Amigó, E., de Albornoz, J.C., Chugur, I., Corujo, A., Gonzalo, J., Martín-Wanton, T., Meij, E., de Rijke, M., Spina, D.: Overview of RepLab 2013: evaluation of online reputation monitoring systems. In: Forner, P., Navigli, R., Tufis, D., Ferro, N. (eds.) Working Notes for CLEF 2013 Conference, CEUR-WS.org, CEUR Workshop Proceedings, vol. 1179, pp. 1–20 (2013)
Aramaki, E., Maskawa, S., Morita, M.: Twitter catches the flu: detecting influenza epidemics using twitter. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 1568–1576 (2011)
Artstein, R., Poesio, M.: Inter-coder agreement for computational linguistics. Comput. Linguist. 34(4), 555–596 (2008)
Belinkov, Y., Glass, J.: Analysis methods in neural language processing: a survey. Tech. rep. (2018). ArXiv arXiv:1812.08951
Bourdieu, P.: The forms of capital. In: Handbook of Theory and Research for the Sociology of Education. Greenwood Press, New York (1986)
Breiman, L.: Bagging predictors. Mach. Learn. 24, 123–140 (1996)
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001)
Brin, S.: Extracting patterns and relations from the world wide web. In: Atzeni, P., Mendelzon, A.O., Mecca, G. (eds.) Selected Papers from the International Workshop on the World Wide Web and Databases, pp. 172–183. Springer, London, UK, WebDB ’98 (1999)
Carter, S., Weerkamp, W., Tsagkias, M.: Microblog language identification: overcoming the limitations of short, unedited and idiomatic text. Lang. Resour. Eval. 47(1), 195–215 (2013)
Chandrashekar, G., Sahin, F.: A survey on feature selection methods. Comput. Electr. Eng. 40(1), 16–28 (2014)
Chavoshi, N., Hamooni, H., Mueen, A.: DeBot: twitter bot detection via warped correlation. In: Proceedings—IEEE International Conference on Data Mining, pp. 817–822 (2017)
Chu, Z., Gianvecchio, S., Wang, H., Jajodia, S.: Detecting automation of twitter accounts: are you a human, bot, or cyborg? IEEE Trans. Dependable Secur. Comput. 9(6), 811–824 (2012)
Cohen, J.: A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 20(1), 37–46 (1960)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Crichton, G., Pyysalo, S., Chiu, B., Korhonen, A.: A neural network multi-task learning approach to biomedical named entity recognition. BMC Bioinform. 18(1), 368 (2017)
Davis, C.A., Varol, O., Ferrara, E., Flammini, A., Menczer, F.: BotOrNot: a system to evaluate social bots. In: Proceedings of the 25th International Conference Companion on World Wide Web—WWW ’16 Companion, pp. 273–274. ACM Press, New York, New York, USA (2016)
Davis, J., Goadrich, M.: The relationship between precision-recall and ROC curves. In: Proceedings of the 23rd International Conference on Machine Learning, pp. 1–8 (2006)
De Gemmis, M., Lops, P., Semeraro, G., Musto, C.: An investigation on the serendipity problem in recommender systems. Inf. Process. Manag. 51(5), 695–717 (2015)
Derczynski, L., Maynard, D., Rizzo, G., Van Erp, M., Gorrell, G., Troncy, R., Petrak, J., Bontcheva, K.: Analysis of named entity recognition and linking for tweets. Inf. Process. Manag. 51(2), 32–49 (2014)
Downey, D., Broadhead, M., Etzioni, O.: Locating complex named entities in web text. In: Proceedings of the Twentieth International Joint Conference on Artificial Intelligence, pp. 2733–2739 (2007)
Erdmann, M., Ward, E., Ikeda, K., Hattori, G., Ono, C., Takishima, Y.: Automatic labeling of training data for collecting tweets for ambiguous TV program titles. In: Proceedings of 5th International Conference on Social Computing, pp. 796–802 (2013)
Evans, M.D., Kelley, J., Sikora, J., Treiman, D.J.: Family scholarly culture and educational success: books and schooling in 27 nations. Res. Soc. Stratif. Mobil. 28(2), 171–197 (2010)
Evans, M.D.R., Kelley, J., Sikora, J.: Scholarly culture and academic performance in 42 nations. Soc. Forces 92(4), 1573–1605 (2014)
Freund, Y., Schapire, R.R.E.: Experiments with a new boosting algorithm. In: International Conference on Machine Learning, pp. 1–9 (1996)
Gridach, M.: Character-level neural network for biomedical named entity recognition. J. Biomed. Inform. 70, 85–91 (2017)
Grier, C., Thomas, K., Paxson, V., Zhang, M.: @Spam: the underground on 140 characters or less. In: Proceedings of the 17th ACM Conference on Computer and Communications Security, pp. 27–37 (2010)
Guzman, E., Alkadhi, R., Seyff, N.: An exploratory study of twitter messages about software applications. Requir. Eng. 22(3), 387–412 (2017)
Habib, M.B., Van Keulen, M.: TwitterNEED: a hybrid approach for named entity extraction and disambiguation for tweet. Nat. Lang. Eng. 22(03), 423–456 (2016)
Holzinger, A.: Interactive machine learning for health informatics: when do we need the human-in-the-loop? Brain Inform. 3(2), 119–131 (2016)
Izyan, N., Saat, Y., Azman, S., Noah, M., Mohd, M.: Towards serendipity for content-based recommender systems. Int. J. Adv. Sci. Eng. Inf. Technol. 8(4–2), 1762–1769 (2018)
Jiang, R., Chiappa, S., Lattimore, T., Agyorgy, A., Kohli, P., Sinha, A., Gleich, D.F., Ramani, K.: Deconvolving feedback loops in recommender systems. In: Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R. (eds.) Advances in neural information processing systems, vol. 29, pp. 3243–3251. Curran Associates, Inc. (2016)
Kaur, P., Singhal, A., Kaur, J.: Spam detection on twitter: a survey. In: 3rd International Conference on Computing for Sustainable Global Development, pp. 2570–2573 (2016)
Kazai, G., Landoni, M., Eickhoff, C., Brusilovsky, P.: BooksOnline’12: 5th workshop on online books, complementary social media and their impact. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management, pp. 2764–2765 (2012)
Kitamura, S., Hashimoto, Y., Kimura, T., Tsuji, D., Korenaga, R., Mori, Y., Ogasahara, M., Kawai, D.: Cross-national comparison of information behavior and social attitudes: online survey in Japan, China, South Korea, Singapore, and the United States [in Japanese], vol. 34, pp. 119–211. Research Survey Reports in Information Studies Interfaculty Initiative in Information Studies, the University of Tokyo (2018)
Koolen, M., Bogers, T., Kazai, G., Kamps, J.: Overview of the INEX 2014 social book search track. In: Cappellato, L., Ferro, N., Halvey, M., Kraaij, W. (eds.) Working Notes for CLEF 2014 Conference, CEUR-WS.org, CEUR Workshop Proceedings, vol. 1180, pp. 462–479 (2014)
Kotkov, D., Wang, S., Veijalainen, J.: A survey of serendipity in recommender systems. Knowl. Based Syst. 111, 180–192 (2016)
Kou, Z., Cohen, W.W., Murphy, R.F.: High-recall protein entity recognition using a dictionary. Bioinformatics 21(Suppl 1), i266–i273 (2005)
Limsopatham, N., Collier, N.: Bidirectional LSTM for named entity recognition in twitter messages. In: 2nd Workshop on Noisy User-generated Text, pp. 145–152 (2016)
Liu, P., Qiu, X., Huang, X.: Recurrent neural network for text classification with multi-task learning. In: Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, pp. 2873–2879 (2016)
Luyt, B., Heok, A.: David and Goliath: tales of independent bookstores in Singapore. Publ. Res. Q. 31(2), 122–131 (2015)
McCallum, A., Nigam, K.: A comparison of event models for naive bayes text classification. In: Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, pp. 41–48 (1998)
McCord, M., Chuah, M.: Spam detection on twitter using traditional classifiers. In: Calero, J., Yang, L., Mármol, F., García Villalba, L., Li, A., Wang, Y. (eds.) Autonomic and Trusted Computing SE—13. Lecture Notes in Computer Science, vol. 6906, pp. 175–186. Springer, Berlin (2011)
Neubig, G., Duh, K.: How much is said in a tweet? A multilingual, information-theoretic perspective. In: Proceedings of the AAAI Spring Symposium: Analyzing Microtext, pp. 32–39 (2013)
OECD: Preparing our youth for an inclusive and sustainable world: the OECD PISA global competence framework (2018)
Pandey, G., Kotkov, D., Semenov, A.: Recommending serendipitous items using transfer learning. In: Proceedings of the 27th ACM International Conference on Information and Knowledge Management, pp. 1771–1774 (2018)
Pariser, E.: The Filter Bubble: What the Internet is Hiding from You. Penguin Press, London (2011)
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E.: Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12, 2825–2830 (2011)
Ponnusamy, R., Degife, W.A., Alemu, T.: Recommender frameworks outline system design and strategies: a review. In: Knowledge Computing and Its Applications, pp. 261–285. Springer, Singapore (2018)
Prasetyo, P.K., Lo, D., Achananuparp, P., Tian, Y., Lim, E.P.: Automatic classification of software related microblogs. In: Proceedings of the 28th International Conference on Software Maintenance, pp. 596–599 (2012)
Prusa, J.D., Khoshgoftaar, T.M.: Deep neural network architecture for character-level learning on short text. In: Proceedings of the Thirtieth International Florida Artificial Intelligence Research Society Conference, pp. 353–358 (2017)
Ritter, A., Clark, S., Etzioni, O.: Named entity recognition in tweets: an experimental study. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, ACL, pp. 1524–1534 (2011)
Saito, T., Rehmsmeier, M.: The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 10(3), 1–21 (2015)
Salton, G., Yang, C.S.: On the specification of term values in automatic indexing. J. Doc. 29(4), 351–372 (1973)
Sang, E.F.T.K., De Meulder, F.: Introduction to the CoNLL-2003 shared task: language-independent named entity recognition. In: Proceedings of the Seventh Conference on Natural Language Learning, vol. 4, pp. 142–147 (2003)
Sekine, S., Nobata, C.: Definition, dictionaries and tagger for extended named entity hierarchy. In: Proceedings of the 11th International Conference on Language Resources and Evaluation, pp. 1977–1980 (2004)
Severyn, A., Moschitti, A.: UNITN: training deep convolutional neural network for twitter sentiment classification. In: Proceedings of the 9th International Workshop on Semantic Evaluation, pp. 464–469 (2015)
Sharma, M., Mann, S.: A survey of recommender systems: approaches and limitations. Int. J. Innov. Eng. Technol. 2, 1–9 (2013)
Sikora, J., Evans, M.D., Kelley, J.: Scholarly culture: how books in adolescence enhance adult literacy, numeracy and technology skills in 31 societies. Soc. Sci. Res. 77, 1–15 (2019)
Strauss, B., Toma, B.E., Ritter, A., De Marneffe, M.C., Xu, W.: Results of the WNUT16 named entity recognition shared task. In: Proceedings of the 2nd Workshop on Noisy User-generated Text (WNUT), pp. 138–144 (2016)
Sullivan, A., Brown, M.: Reading for pleasure and progress in vocabulary and mathematics. Br. Educ. Res. J. 41(6), 971–991 (2015)
Tang, Y., Chen, H.H.: Mining sentiment words from microblogs for predicting writer-reader emotion transition. In: Proceedings of the Eight International Conference on Language Resources and Evaluation, pp. 1226–1229 (2012)
Tuarob, S., Mitrpanont, J.L.: Automatic discovery of abusive thai language usages in social networks. In: Choemprayong, S., Crestani, F., Cunningham, S.J. (eds.) Digital Libraries: Data, Information, and Knowledge for Digital Lives. Lecture Notes in Computer Science, vol. 10647, pp. 267–278. Springer, Cham (2017)
Tuarob, S., Tucker, C.S., Salathe, M., Ram, N.: An ensemble heterogeneous classification methodology for discovering health-related knowledge in social media messages. J. Biomed. Inform. 49, 255–268 (2014)
Twenge, J.M., Martin, G.N., Spitzberg, B.H.: Trends in U.S. Adolescents’ media use, 1976–2016: the rise of digital media, the decline of TV, and the (near) demise of print. Psychology of Popular Media Culture (Advance online publication) (2018)
UNESCO: Recommendation concerning the international standardization of statistics relating to book production and periodicals. In: Records of the General Conference, thirteenth session, Paris, 1964: Resolutions, pp. 143–147 (1965)
van Bergen, E., van Zuijen, T., Bishop, D., de Jong, P.F.: Why are home literacy environment and children’s reading skills associated? What parental skills reveal. Read. Res. Q. 52(2), 147–160 (2017)
Varol, O., Ferrara, E., Davis, C., Menczer, F., Flammini, A.: Online human–bot interactions: detection, estimation, and characterization. In: International AAAI Conference on Web and Social Media, pp. 280–289 (2017)
Verma, M., Divya, D., Sofat, S.: Techniques to detect spammers in twitter—a survey. Int. J. Comput. Appl. 85(10), 27–32 (2014)
Wang, A.: Detecting spam bots in online social networking sites: a machine learning approach. In: Foresti, S., Jajodia, S. (eds.) Data and Applications Security and Privacy XXIV SE—25. Lecture Notes in Computer Science, vol. 6166, pp. 335–342. Springer, Berlin (2010)
Willis, C., Efron, M.: Finding information in books: characteristics of full-text searches in a collection of 10 million books. In: Proceedings of the 76th ASIS&T Annual Meeting: Beyond the Cloud: Rethinking Information Boundaries, pp. 1–10 (2013)
Wu, M., Scholer, F., Thom, J.A.: The impact of query length and document length on book search effectiveness. In: Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 5631, pp. 172–178. LNCS (2009)
Wu, T., Wen, S., Xiang, Y., Zhou, W.: Twitter spam detection: survey of new approaches and comparative study. Comput. Secur. 76, 265–284 (2018)
Yada, S.: Development of a book recommendation system to inspire ‘infrequent readers’. In: Tuamsuk, K., Jatowt, A., Rasmussen, E. (eds.) The Emergence of Digital Libraries—Research and Practices, LNCS, vol. 8839, pp. 399–404. Springer, Berlin (2014)
Yada, S.: Tweets that mention books 2015. Mendeley Data, vol. V1 (2019). https://doi.org/10.17632/y37hn2x8s6.1
Yada, S., Kageura, K.: Identification of tweets that mention books: an experimental comparison of machine learning methods. In: Allen, R.B., Hunter, J., Zeng, M.L. (eds.) Digital Libraries: Providing Quality Information. Lecture Notes in Computer Science, vol. 9469, pp. 278–288. Springer, Cham (2015)
Zhang, X., Zhao, J., LeCun, Y.: Character-level convolutional networks for text classification. In: Proceedings of the 28th International Conference on Neural Information Processing Systems, pp. 649–657 (2015)
Acknowledgements
We thank Associate Professor Takeshi Abekawa for allowing us to use the Webcat Plus data. We show our appreciation for the annotator who labelled a part of our data set. Finally, we express our gratitude to all the reviewers for their thoughtful comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research is supported by the Japan Society for the Promotion of Science (JSPS) KAKENHI Grant Number JP 16K12542 and JSPS Invitational Fellowships for Research in Japan S18111 (2018)
Rights and permissions
About this article

Cite this article
Yada, S., Kageura, K. & Paris, C. Identification of tweets that mention books. Int J Digit Libr 21, 265–287 (2020). https://doi.org/10.1007/s00799-019-00273-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00799-019-00273-4