
Abstract
Many applications such as social networks, recommendation systems, email communication patterns, and other collaborative applications are built on top of graph infrastructures. The data stored on such networks may contain personal information about individuals and may therefore be sensitive from a privacy point of view. Therefore, a natural solution is to remove identifying information from the nodes and perturb the graph structure, so that re-identification becomes difficult. Typical graphs encountered in real applications are sparse. In this paper, we will show that sparse graphs have certain theoretical properties which make them susceptible to re-identification attacks. We design a systematic way to exploit these theoretical properties in order to construct re-identification signatures, which are also known as characteristic vectors. These signatures have the property that they are extremely robust to perturbations, especially for sparse graphs. We use these signatures in order to create an effective attack algorithm. We supplement our theoretical results with experimental tests using a number of algorithms on real data sets. These results confirm that even low levels of anonymization require perturbation levels which are significant enough to result in a massive loss of utility. Our experimental results also show that the true anonymization level of graphs is much lower than is implied by measures such as \(k\)-anonymity. Thus, the results of this paper establish that the problem of graph anonymization has fundamental theoretical barriers which prevent a fully effective solution.




Similar content being viewed by others
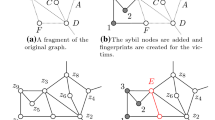

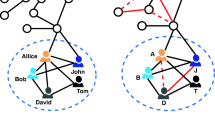
Notes
In the case of many social networking sites, the links are typically symmetric and therefore form an undirected network. In the case of a directed network, it is assumed that both inlinks and outlinks are known.
Available at http://www.cs.helsinki.fi/u/tsaparas/MACN2006.
Available at http://www.cs.helsinki.fi/u/tsaparas/MACN2006.
Available at http://www.sommer.jp/graphs.
References
Aggarwal CC, Li Y, Yu P (2011) On the hardness of graph anonymization, ICDM conference
Aggarwal CC, Yu PS (2008) Privacy-preserving data mining: models and algorithms, Springer, Berlin
Agrawal R, Srikant R (2000) Privacy-preserving data mining. ACM SIGMOD conference
Agrawal D, Aggarwal CC (2001) On the design and quantification of privacy preserving data mining algorithms. ACM PODS conference
Ahuja R, Orlin J, Magnanti T (1992) Network flows: theory, algorithms, and applications. Prentice Hall, Englewood Cliffs, NJ, USA
Backstrom L, Dwork C, Kleinberg J (2007)Wherefore Art Thou R3579X? Anonymized social networks, hidden patterns, and structural steganography. WWW conference
Bayardo RJ, Agrawal R (2005) Data privacy through optimal k-anonymization. ICDE conference
Cormode G, Srivastava D, Yu T, Zhang Q (2008) Anonymizing bipartite graph data using safe groupings. VLDB conference
Evfimievski A, Srikant R, Agrawal R, Gehrke J (2002) Privacy preserving mining of association rules. ACM KDD conference
Fung B, Wang K, Yu PS (2007) Anonymizing classification data for privacy preservation. IEEE TKDE, pp 711–725
Garey M, Johnson D (1979) Computers and intractability: a guide to the theory of NP-completeness, Freeman
Hay M, Miklau G, Jensen D, Towsley D, Weis P (2008) Resisting structural re-identification in social networks, VLDB conference
Hay M, Miklau G, Jensen D, Weis P, Srivastava S (2007) Anonymizing social networks. Technical report 07–19. University of Massachusetts, Amherst
Kifer D, Gehrke J (2006) Injecting utility into anonymized datasets. SIGMOD conference, pp 217–228
LeFevre K, DeWitt D, Ramakrishnan R (2006) Mondrian multidimensional k-anonymity. ICDE conference
Liu K, Terzi E (2008) Towards identity anonymization on graphs. ACM SIGMOD conference
Machanavajjhala A A, Gehrke J, Kifer D, Venkitasubramaniam M (2006) l-Diversity: privacy beyond k-anonymity. ICDE conference
Samarati P (2001) Protecting respondents identities in microdata release. IEEE TKDE 13(6):1010–1027
Tassa T, Cohen D (2013) Anonymization of centralized and distributed social networks by sequential clustering. IEEE TKDE 25:311–324
Vuokko N, Terzi E (2010) Reconstructing randomized social networks, SDM Conf.,
Wu L, Ying X, Wu X (2010) Reconstruction from randomized graph via low rank approximation, SDM Conf.,
Ying X, Wu X (2008) Randomizing social networks: a spectrum preserving approach. SDM conference
Ying X, Pan K, Wu X, Guo L (2009) Comparisons of randomization and \(k\)-degree anonymization schemes for privacy-preserving social network publishing. ACM KDD Conference
Zhou B, Pei J (2008) Preserving privacy in social networks against neighborhood attacks. ICDE conference
Acknowledgments
This work is supported in part by NSF through grants CNS-1115234 and OISE-1129076, and US Department of Army through grant W911NF-12-1-0066.
Author information
Authors and Affiliations
Corresponding author
Additional information
This paper is an extended version of the ICDM 2011 paper in [1].
Rights and permissions
About this article

Cite this article
Aggarwal, C.C., Li, Y. & Yu, P.S. On the anonymizability of graphs. Knowl Inf Syst 45, 571–588 (2015). https://doi.org/10.1007/s10115-014-0788-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-014-0788-1