
Abstract
Multi-aspect data appear frequently in web-related applications. For example, product reviews are quadruplets of the form (user, product, keyword, timestamp), and search-engine logs are quadruplets of the form (user, keyword, location, timestamp). How can we analyze such web-scale multi-aspect data on an off-the-shelf workstation with a limited amount of memory? Tucker decomposition has been used widely for discovering patterns in such multi-aspect data, which are naturally expressed as large but sparse tensors. However, existing Tucker decomposition algorithms have limited scalability, failing to decompose large-scale high-order (\(\ge \) 4) tensors, since they explicitly materialize intermediate data, whose size grows exponentially with the order. To address this problem, which we call “Materialization Bottleneck,” we propose S-HOT, a scalable algorithm for high-order Tucker decomposition. S-HOT minimizes materialized intermediate data by using an on-the-fly computation, and it is optimized for disk-resident tensors that are too large to fit in memory. We theoretically analyze the amount of memory and the number of data scans required by S-HOT. Moreover, we empirically show that S-HOT handles tensors with higher order, dimensionality, and rank than baselines. For example, S-HOT successfully decomposes a real-world tensor from the Microsoft Academic Graph on an off-the-shelf workstation, while all baselines fail. Especially, in terms of dimensionality, S-HOT decomposes 1000 \(\times \) larger tensors than baselines.





Similar content being viewed by others



Notes
\(\textsc {S-HOT}_{\text {space}}\) and \(\textsc {S-HOT}_{\text {scan}}\) appeared in the conference version of this paper [35]. This work extends [35] with \(\textsc {S-HOT}_{\text {memo}}\), which is significantly faster than \(\textsc {S-HOT}_{\text {space}}\) and \(\textsc {S-HOT}_{\text {scan}}\), space complexity analyses, and additional experimental results.
When the input tensor is sparse, a straightforward way of computing
 is to (1) compute
is to (1) compute  for each nonzero element \(\varvec{\mathscr {X}}(i_{1},\dots ,i_{N})\) and (2) combine the results together. The result of
for each nonzero element \(\varvec{\mathscr {X}}(i_{1},\dots ,i_{N})\) and (2) combine the results together. The result of  takes \(O(\prod _{p\ne n}J_p)\) space. Since there are M nonzero elements, \(O(M \prod _{p\ne n}J_p)\) space is required in total.
takes \(O(\prod _{p\ne n}J_p)\) space. Since there are M nonzero elements, \(O(M \prod _{p\ne n}J_p)\) space is required in total.For example, see line 13 of Algorithm 4 in [25].
Instead of computing the eigenvectors of
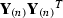 , we can use directly obtain the singular vectors of
, we can use directly obtain the singular vectors of  using, for example, Lanczos bidiagonalization [7]. We leave exploration of such variation for future work.
using, for example, Lanczos bidiagonalization [7]. We leave exploration of such variation for future work.The size of the memo never exceeds 200KB unless otherwise stated.
However, this does not mean that S-HOT is limited to binary tensors nor our implementation is optimized for binary tensors. We choose binary tensors for simplicity. Generating realistic values, while we control each factor, is not a trivial task.
 is to (1) compute
is to (1) compute  for each nonzero element
for each nonzero element  takes
takes 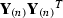 , we can use directly obtain the singular vectors of
, we can use directly obtain the singular vectors of  using, for example, Lanczos bidiagonalization [
using, for example, Lanczos bidiagonalization [References
Acar E, Çamtepe SA, Krishnamoorthy MS, Yener B (2005) Modeling and multiway analysis of chatroom tensors. In: ISI
Adamic LA, Huberman BA (2002) Zipf’s law and the Internet. Glottometrics 3(1):143–150
Arthur D, Vassilvitskii S (2007) k-means++: the advantages of careful seeding. In: SODA
Austin W, Ballard G, Kolda TG (2016) Parallel tensor compression for large-scale scientific data. In: IPDPS
Bader BW, Kolda TG. Matlab tensor toolbox version 2.6. http://www.sandia.gov/~tgkolda/TensorToolbox/
Baskaran M, Meister B, Vasilache N, Lethin R (2012) Efficient and scalable computations with sparse tensors. In: HPEC
Berry MW (1992) Large-scale sparse singular value computations. Int J Supercomput Appl 6(1):13–49
Beutel A, Kumar A, Papalexakis EE, Talukdar PP, Faloutsos C, Xing EP (2014) Flexifact: scalable flexible factorization of coupled tensors on hadoop. In: SDM
Cai Y, Zhang M, Luo D, Ding C, Chakravarthy S (2011) Low-order tensor decompositions for social tagging recommendation. In: WSDM
Chi Y, Tseng BL, Tatemura J (2006) Eigen-trend: trend analysis in the blogosphere based on singular value decompositions. In: CIKM
Choi D, Jang JG, Kang U (2017) Fast, accurate, and scalable method for sparse coupled matrix-tensor factorization. arXiv preprint arXiv:1708.08640
Choi JH, Vishwanathan S (2014) Dfacto: distributed factorization of tensors. In: NIPS
Clauset A, Shalizi CR, Newman ME (2009) Power-law distributions in empirical data. SIAM Rev 51(4):661–703
Cohen JE, Farias RC, Comon P (2015) Fast decomposition of large nonnegative tensors. IEEE Signal Process Lett 22(7):862–866
Chakaravarthy V-T, Choi J-W, Joseph D-J, Murali P, Pandian S-S, Sabharwal Y, Sreedhar D (2018) On optimizing distributed tucker decomposition for sparse tensors. IEEE Signal Process Mag
de Almeida AL, Kibangou AY (2013) Distributed computation of tensor decompositions in collaborative networks. In: CAMSAP, pp 232–235
de Almeida AL, Kibangou AY (2014) Distributed large-scale tensor decomposition. In: ICASSP
De Lathauwer L, De Moor B, Vandewalle J (2000) On the best rank-1 and rank-(R1, R2,., Rn) approximation of higher-order tensors. SIAM J Matrix Anal Appl 21(4):1324–1342
De Lathauwer L, De Moor B, Vandewalle J (2000) A multilinear singular value decomposition. SIAM J Matrix Anal Appl 21(4):1253–1278
Franz T, Schultz A, Sizov S, Staab S (2009) Triplerank: ranking semantic web data by tensor decomposition. In: ISWC
Jeon B, Jeon I, Sael L, Kang U (2016) Scout: Scalable coupled matrix-tensor factorization—algorithm and discoveries. In: ICDE
Jeon I, Papalexakis EE, Kang U, Faloutsos C (2015) Haten2: billion-scale tensor decompositions. In: ICDE
Kang U, Papalexakis E, Harpale A, Faloutsos C (2012) Gigatensor: scaling tensor analysis up by 100 times-algorithms and discoveries.e In: KDD
Kaya O, Uçar B (2015) Scalable sparse tensor decompositions in distributed memory systems. In: SC
Kaya O, Uçar B (2016) High performance parallel algorithms for the tucker decomposition of sparse tensors. In: ICCP
Kolda TG, Bader BW (2009) Tensor decompositions and applications. SIAM Rev 51(3):455–500
Kolda TG, Sun J (2008) Scalable tensor decompositions for multi-aspect data mining. In: ICDM
Kolda TG, Bader BW, Kenny JP (2005) Higher-order web link analysis using multilinear algebra. In: ICDM
Lamba H, Nagarajan V, Shin K, Shajarisales N (2016) Incorporating side information in tensor completion. In: WWW companion
Lehoucq RB, Sorensen DC, Yang C (1998) ARPACK users’ guide: solution of large-scale eigenvalue problems with implicitly restarted Arnoldi methods, vol 6. Siam
Li J, Choi J, Perros I, Sun J, Vuduc R (2017) Model-driven sparse CP decomposition for higher-order tensors. In: IPDPS
Li J, Sun J, Vuduc R (2018) HiCOO: hierarchical storage of sparse tensors. In: SC
Maruhashi K, Guo F, Faloutsos C (2011) Multiaspectforensics: pattern mining on large-scale heterogeneous networks with tensor analysis. In: ASONAM
Moghaddam S, Jamali M, Ester M (2012) ETF: extended tensor factorization model for personalizing prediction of review helpfulness. In: WSDM
Oh J, Shin K, Papalexakis EE, Faloutsos C, Yu H (2017) S-hot: scalable high-order tucker decomposition In: WSDM
Oh S, Park N, Sael L, Kang U (2018) Scalable tucker factorization for sparse tensors—algorithms and discoveries. In: ICDE, pp 1120–1131
Oh S, Park N, Sael L, Kang U (2019) High-performance tucker factorization on heterogeneous platforms. IEEE Trans Parallel Distrib Syst
Papalexakis EE, Faloutsos C, Sidiropoulos ND (2015) Parcube: sparse parallelizable candecomp-parafac tensor decomposition. TKDD 10(1):3
Papalexakis EE, Faloutsos C, Sidiropoulos ND (2016) Tensors for data mining and data fusion: models, applications, and scalable algorithms. TIST 8(2):16
Perros I, Chen R, Vuduc R, Sun J (2015) Sparse hierarchical tucker factorization and its application to healthcare. In: ICDM
Pang R, Allman M, Paxson V, Lee J (2014) The devil and packet trace anonymization. ACM SIGCOMM Comput Commun Rev 36(1):29–38
Powers DM (1998) Applications and explanations of Zipf’s law. In: NeMLaP/CoNLL
Rendle S, Schmidt-Thieme L (210) Pairwise interaction tensor factorization for personalized tag recommendation. In: WSDM
Saad Y (2011) Numerical methods for large eigenvalue problems. Society for Industrial and Applied Mathematics, Philadelphia
Sael L, Jeon I, Kang U (2015) Scalable tensor mining. Big Data Res 2(2):82–86
Smith S, Karypis G (2015) Tensor-matrix products with a compressed sparse tensor. In: IA3
Smith S, Karypis G (2017) Accelerating the tucker decomposition with compressed sparse tensors. In: Euro-Par
Smith S, Choi JW, Li J, Vuduc R, Park J, Liu X, Karypis G. FROSTT: the formidable repository of open sparse tensors and tools. http://frostt.io/
Shin K, Hooi B, Faloutsos C (2018) Fast, accurate, and flexible algorithms for dense subtensor mining. TKDD 12(3):28:1–28:30
Shin K, Hooi B, Kim J, Faloutsos C (2017) DenseAlert: incremental dense-subtensor detection in tensor streams. In: KDD
Shin K, Lee S, Kang U (2017) Fully scalable methods for distributed tensor factorization. TKDE 29(1):100–113
Sidiropoulos ND, Kyrillidis A (2012) Multi-way compressed sensing for sparse low-rank tensors. IEEE Signal Process Lett 19(11):757–760
Sinha A, Shen Z, Song Y, Ma H, Eide D, Hsu B-JP, Wang K (2015) An overview of microsoft academic service (MAS) and applications. In: WWW companion
Sun J, Tao D, Faloutsos C (2006) Beyond streams and graphs: dynamic tensor analysis. In: KDD
Sun J-T, Zeng H-J, Liu H, Lu Y, Chen Z (2005) Cubesvd: a novel approach to personalized web search. In: WWW
Shetty J, Adibi J. The Enron email dataset database schema and brief statistical report. Information sciences institute technical report. University of Southern California
Tsourakakis CE (2010) Mach: fast randomized tensor decompositions. In: SDM, SIAM
Tucker LR (1966) Some mathematical notes on three-mode factor analysis. Psychometrika 31(3):279–311
Vannieuwenhoven N, Vandebril R, Meerbergen K (2012) A new truncation strategy for the higher-order singular value decomposition. SIAM J Sci Comput 34(2):A1027–A1052
Acknowledgements
This research was supported by Disaster-Safety Platform Technology Development Program of the National Research Foundation of Korea (NRF) funded by the Ministry of Science and ICT (Grant Number: 2019M3D7A1094364) and the National Research Foundation of Korea (NRF) Grant funded by the Korea government (MSIP) (No. 2016R1E1A1A01942642).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, J., Oh, J., Shin, K. et al. Fast and memory-efficient algorithms for high-order Tucker decomposition. Knowl Inf Syst 62, 2765–2794 (2020). https://doi.org/10.1007/s10115-019-01435-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-019-01435-1